Using Machine Learning for Data Quality
In my last blog, I highlighted some of the Data Governance challenges in Big Data and how Data Quality (DQ) is a big part of Data Governance. In this blog, I wanted to focus on how Big Data is changing the DQ methodology.
Big Data has made Machine Learning (ML) mainstream and just as DQ has impacted ML, ML is also changing the DQ implementation methodology. DQ has traditionally been a task within IT wherein, analysts would look a data, understand the patterns (Profiling) and establish data cleansing and matching rules (Standardization). After rules have been established and productionized, there will be attempts to measure the quality of each data set in regular intervals.
Why Use ML in DQ?
Limitations of Traditional DQ process
Let’s look at the limitations of the traditional approach to data Matching. Until now, the selection criteria has been very dependent on blocking and choosing correct weights. These activities by their very nature is very manual and therefore subject to substantial errors. Defining matching rules is also a very time consuming process. Organizations take months to define and fine-tune matching rules.
Another limitation is the size of each block of data. If the size of the block is too big, the performance of the matching process can be severely impacted. Any huge variation in the datasets in terms of the quality will also make the rules inefficient. This is the reason organizations usually have strict guidelines for data matching and are reluctant to use any manual algorithms that are more prone to errors. This problem has the potential to get drastically more challenging as the number of data sources a businesses need to extract and match in order to have a full picture of their enterprise is increasing daily.
The rise of ML has the potential to dramatically impact methodologies for DQ. Part of the standardization processes, specifically data matching, could be automated by making a ML model ‘learn’ and predict the matches routinely. After the initial manual work to setup the labels, ML models can start learning from the new data that is being submitted for standardization. The more data supplied to the model, the better the ML algorithm can perform and deliver accurate results. Therefore, ML is more scalable compared to traditional approaches. Companies need not restrict the volume of data or number of sources to identify matching rules. Having said that, there is also a need for systems designed to measure how the ML model itself is performing.
Machine Learning Going Mainstream
According to some studies, 22 percent of the companies surveyed have already implemented machine learning algorithms in their data management platforms. NASA, for example, has discovered a lot of applications for machine learning in assessing the quality of scientific data such as detection of unusual data values and anomaly detection.
The reason ML is becoming mainstream is because Big Data processing engines such as Spark have made it possible for developers to now use ML libraries to process their code. Each of the ML libraries currently available through Spark are also available for Talend developers. The Winter ’17 release of Talend Data Fabric also introduced ML components for data matching. They are tMatchpairing, tMatchModel and tMatchPredict. Below is a high-level overview of the process required to use these components for predicting matching results.
Data Matching with Machine Learning in 4 Easy Steps
- Step 1: Pre-analyze the data set using the tMatchpairing component. This uncovers any suspicious data whose match score is between the threshold and match score. The match scores would also be the part of the data set
- Step 2: Data stewards then label the suspect match record as ‘match’ and ‘non-match’. It is a manual process and the Talend Stewardship console can be leveraged to streamline this labelling.
- Step 3: A sample of result set from Step 2 is fed into the tMatchModel for ‘learning’ and the output would be a ML classification model. Model validation is automatically done here using the tMatchPredict component.
- Step 4: The model generated in Step 3 is ready to be used to predict matches for new data sources.
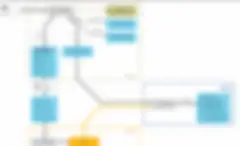
In summary, by combining the power of ML with Spark and data quality processes this workflow can be used to predict matches for data sets automatically. The amount of data will not be a restriction as the process would run automatically on the nodes of the big data cluster leveraging the distributed processing framework of Apache Spark. Therefore, companies who already have Data Scientists can use this workflow not just for analytics but also for their Data Management projects. But its obvious that we are at an infancy stage in terms of using ML for Data Management. More research will need to done to find out ML can help in more advanced Data mangement concepts such as MDM and Data Stewardship.
References:

More related articles
- What is Data Profiling?
- What is data integrity and why is it important?
- What is Data Quality? Definition, Examples, and Tools
- What is Data Quality Management?
- What is Data Redundancy?
- What is data synchronization and why is it important?
- 8 Ways to Reduce Data Integrity Risk
- 10 Best Practices for Successful Data Quality
- Data Quality Analysis
- Data Quality and Machine Learning: What’s the Connection?
- Data Quality Software
- Data Quality Tools - Why the Cloud is the Cure for Dirty Data
- How to Choose a Big Data Quality Model
- How to Choose the Right Data Quality Tools
- The Value of Data Quality in Healthcare