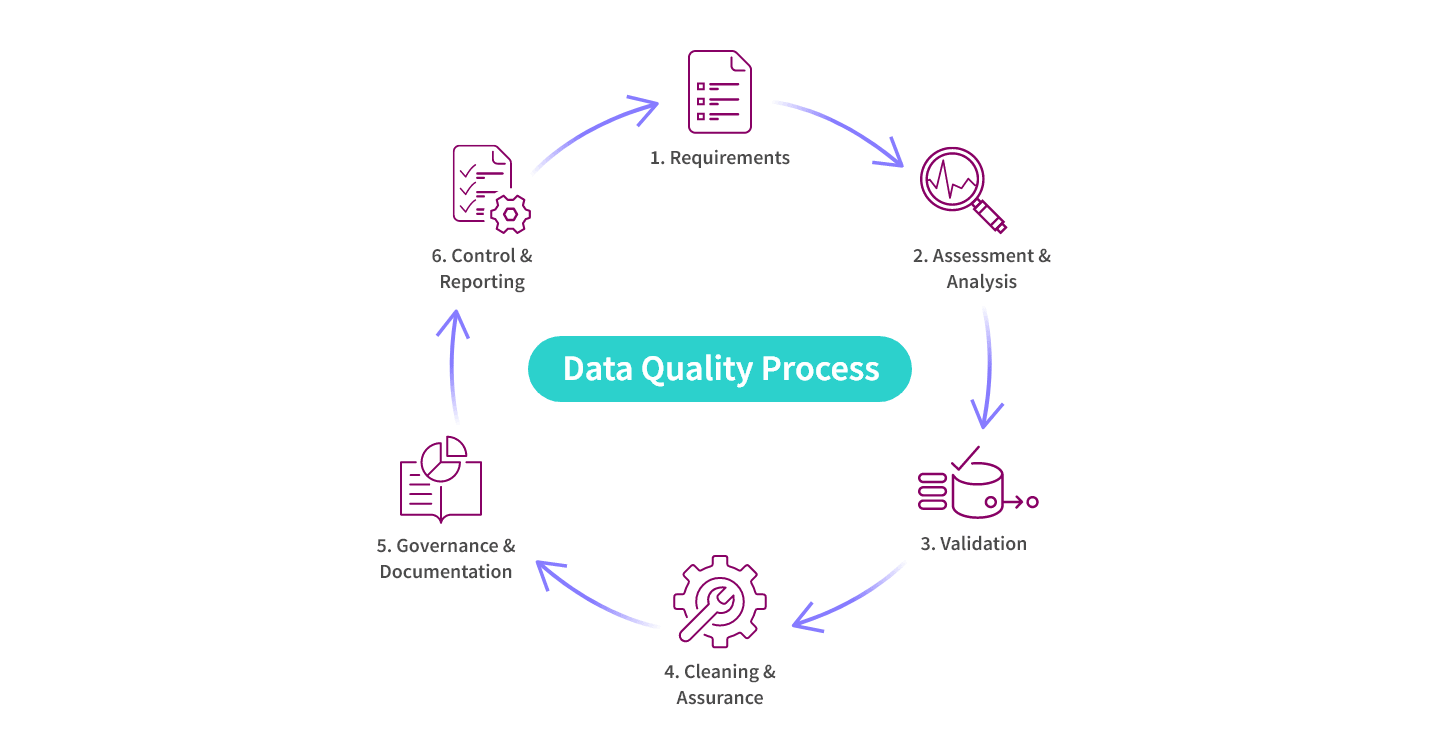
Why It’s Important
Data quality is essential because it underpins informed decision-making, reliable reporting, and accurate analysis. Bad data can lead to errors, misinterpretations, and misguided decisions, potentially causing financial losses and reputational damage. Reliable data enables you to have confidence in your business intelligence insights, leading to better strategic choices, improved operational efficiency, and enhanced customer experiences.