What it is, why you need it, and best practices. This guide provides definitions and practical advice to help you understand and establish modern data integrity.
Data integrity refers to the accuracy, consistency, and completeness of data throughout its lifecycle. It’s a critically important aspect of systems which process or store data because it protects against data loss and data leaks. Maintaining the integrity of your data over time and across formats is a continual process involving various processes, rules, and standards.
Why is Data Integrity Important?
Your organization is most likely flooded by large and complex datasets from many sources, both historical data and real-time streaming data. And you want to confidently make data-driven decisions that improve your business performance.
Incorrect or incomplete data can lead to bad decisions which can cost you significant time, effort, and expense. Plus, the loss of sensitive data–especially if it ends up in the hands of criminals�–can mean enduring and wide-ranging negative impacts.
Here are the key benefits of establishing and maintaining data integrity as part of your data governance framework:
Protecting your customers’ and other data subjects’ information such as personally identifiable information (PII), financial records and usage data.
Helping ensure regulatory compliance such as General Data Protection Regulation (GDPR).
Types of Data Integrity
To ensure integrity in both hierarchical and relational databases, there are the two primary types–physical integrity and logical integrity. Within logical integrity, there are four sub-categories: domain, entity, referential, and user-defined integrity. All are collections of rules and procedures which application programmers, system programmers, data processing managers, and internal auditors use to ensure accurate data.
PHYSICAL INTEGRITY refers to the rules and procedures which ensure the accuracy of data as it is stored and retrieved. Threats to physical integrity include external factors such as power outages, natural disasters and hackers and internal factors such as storage erosion, human error or design flaws. Typically, the affected dataset is unusable.
LOGICAL INTEGRITY seeks to ensure that the data accurately makes sense in a specific context (whether it’s “logical”). Logical integrity also has the challenge of human errors and design flaws. Thankfully, a dataset can be overwritten with new data and reused if it has a logical error. There are four topics of logical integrity as follows:
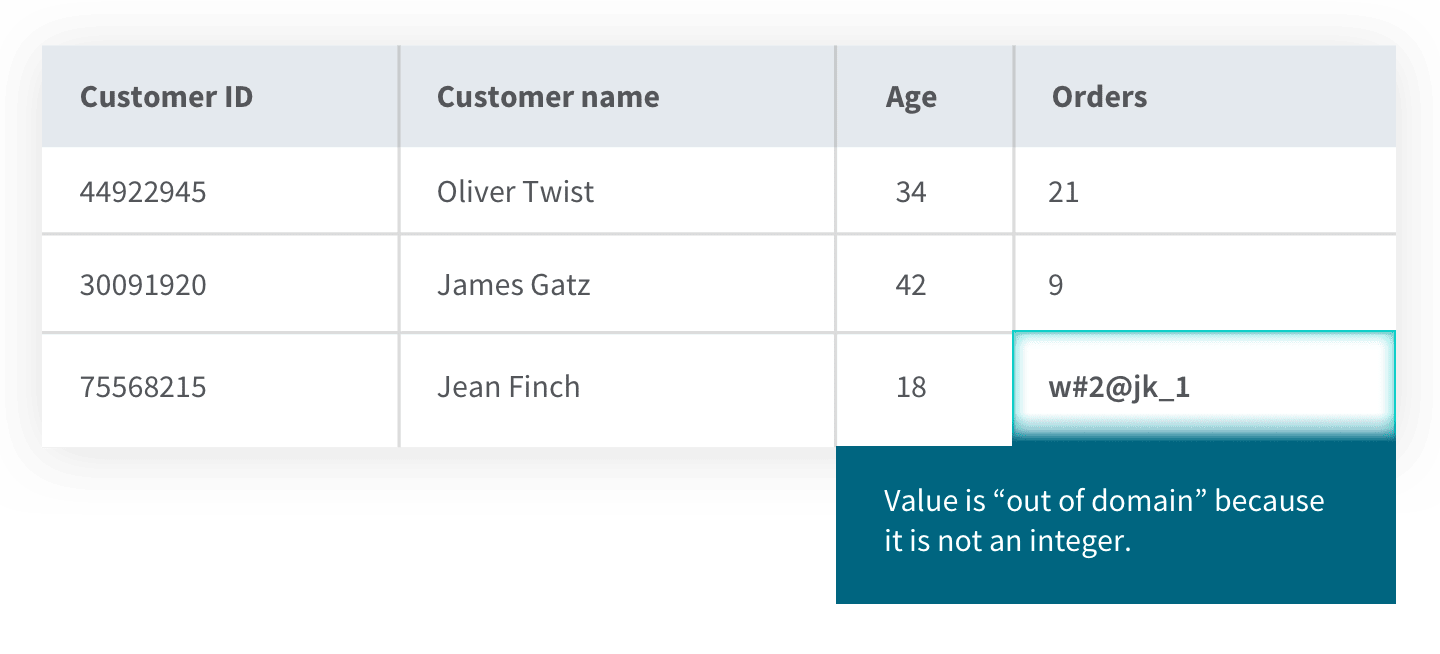
Domain integrity refers to the range of values such as integer, text, or date which are acceptable to be stored in a particular column in a database. This set of values (the “domain”) has constraints which limit the format, amount, and types of data entered. All entries must be available in the domain of the data type. As shown in the example below, the entry for the number of Jean’s orders is not an integer so it is out of domain. This would cause the database management system to produce an error.
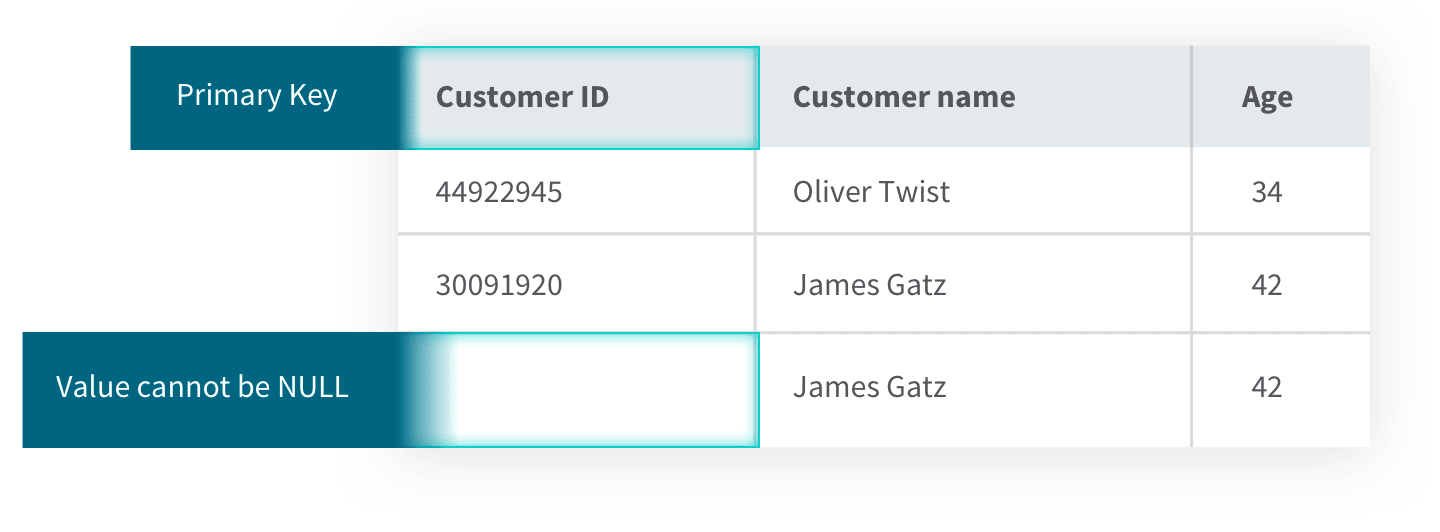
Entity integrity uses primary keys to uniquely identify records saved in a table in a relational database. This prevents them from being duplicated. It also means they can’t be NULL because then you couldn’t uniquely identify the row if the other fields in the rows are the same. For example, you might have two customers with the same name and age, but without the unique identifier of the customer ID primary key, you could have errors or confusion when pulling the data.
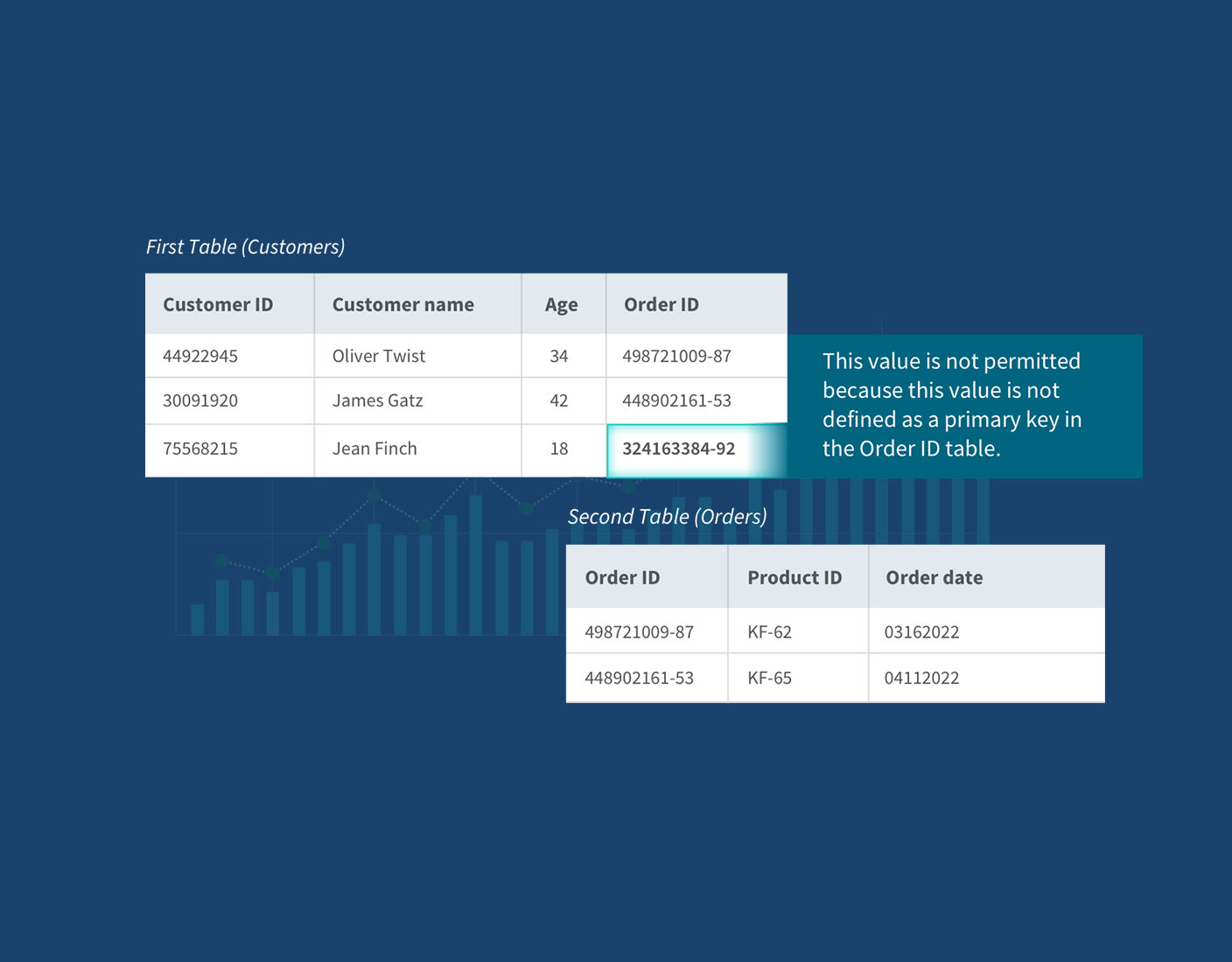
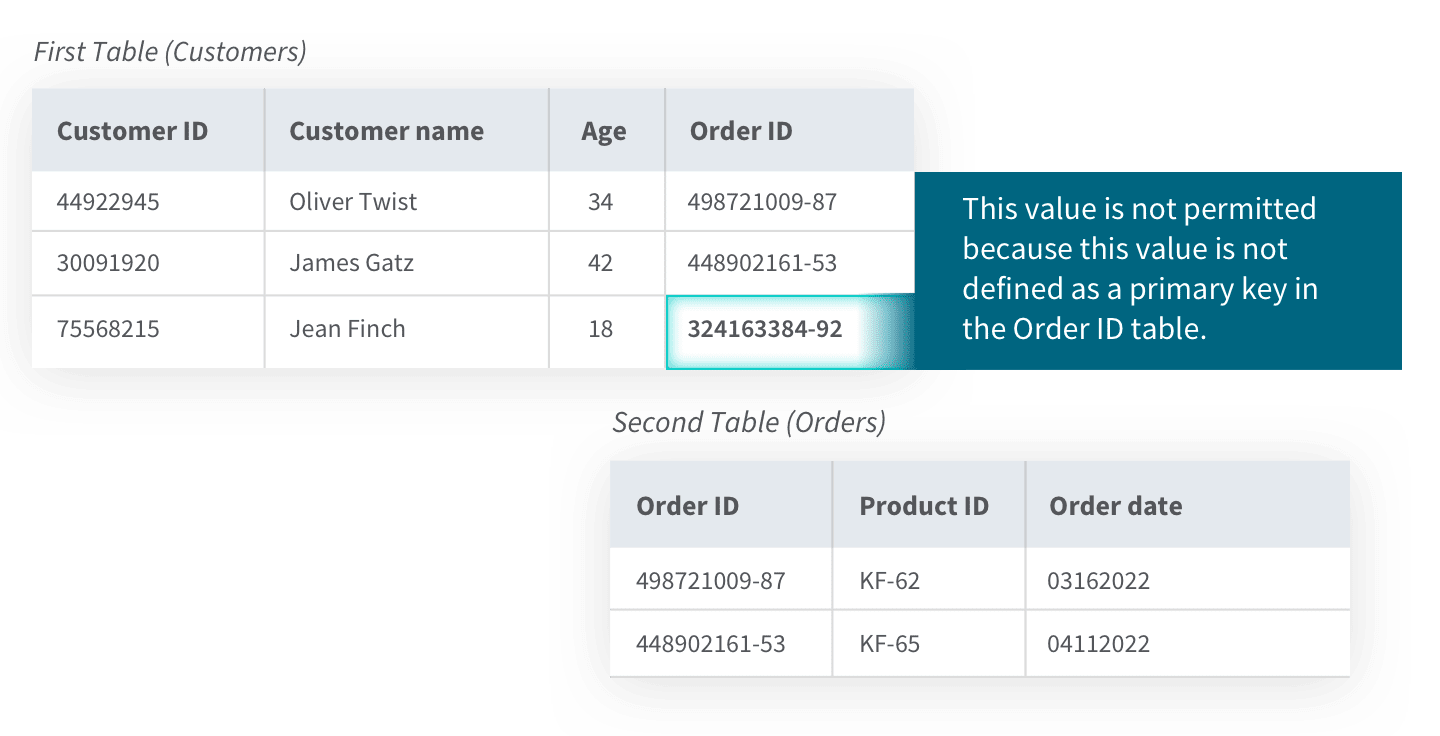
Referential integrity refers to the collection of rules and procedures used to maintain data consistency between two tables. These rules are embedded into the database structure regarding how foreign keys can be used to ensure the data entry is accurate, there is no duplicate data, and, as in the example below, data which doesn't apply is not entered. You can see below how referential integrity is maintained by not allowing an order ID which does not exist in the order table.
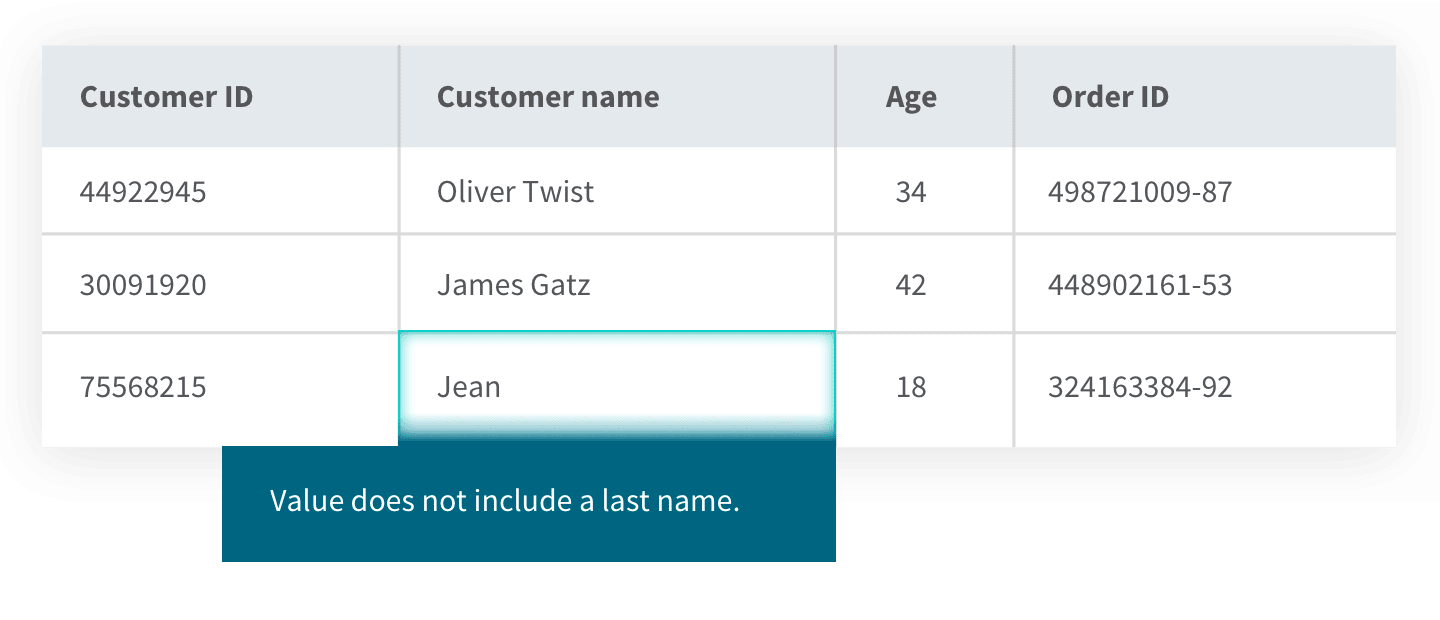
User-defined integrity acts as a way to catch errors which domain, referential and entity integrity do not. Here, you define your own specific business rules and constraints which trigger automatically when predefined events occur. For instance, you could define the constraint that customers must reside in a certain country to be entered into the database. Or, as in the example below, you might require that customers provide both first and last names.
Manage Quality and Security in the Modern Data Analytics Pipeline
There are a wide variety of threats to data integrity. And while most people imagine malicious hackers as the main threat, the majority of root causes are internal and unintentional, such as errors in data collection, inconsistencies across formats, and human error. You should build a culture of data integrity by:
Educating business leaders on the risks
Establishing a robust data governance framework
Investing in the right tools and expertise.
You can ensure physical integrity in your database system by taking steps such as:
Having an uninterruptible power supply
Setting up redundant hardware
Controlling the physical environment against heat, dust or electromagnetic pulses
Using a clustered file system
Using error-correcting memory and algorithms
Using simple algorithms such as Damm or Luhn to detect human transcription errors
Using hash functions to detect computer-induced transcription errors
You can ensure logical integrity by enforcing the four types of integrity constraints described in the previous section (domain, entity, referential, and user-defined). Often, integrity issues arise when data is replicated or transferred. The best data replication tools check for errors and validate the data to ensure it is intact and unaltered between updates.
In addition to these steps, here are 5 key actions to maintain data integrity as a data custodian:
Use a modern data lineage tool to keep an audit trail, tracking any alterations made to the data during its complete lifecycle.
Use a data catalog to control access, making different kinds of data available to different kinds of users. You should also control physical access to your servers.
Require input validation for all data sets, whether they’re supplied by a known or unknown source.
Ensure your data processes have not been corrupted.
Regularly backup and save all data and metadata to a secure location and also verify the retrieval of this backup data during internal audits.
FAQs
Data integrity vs data quality. What’s the difference?
Both data quality and integrity refer to whether your data is reliable and accurate. But data integrity goes further, requiring your data to be complete, consistent, and in context so that it will be of value to you.
Data integrity vs data security. What's the difference?
Integrity refers to the accuracy, consistency, and completeness of data whereas data security focuses on preventing data corruption by using controlled access mechanisms.
What is ALCOA+ data integrity?
The acronym ALCOA originated as an integrity guideline in pharmaceutical manufacturing facilities. It defined that data should be Attributable, Legible, Contemporaneous, Original, and Accurate. The original ALCOA guideline has been updated to ALCOA+, adding the four principles: Complete, Consistent, Enduring, and Available.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.