Uso dell'apprendimento automatico per la qualità dei dati
Nel mio ultimo blog, ho evidenziato alcune delle problematiche della governance dei dati in relazione ai big data e come la qualità dei dati, Data Quality (DQ), ne sia una sua componente significativa. In questo blog voglio concentrarmi sul modo in cui i big data stanno cambiando la metodologia DQ.
Con i big data, l'apprendimento automatico (ML) è diventato l'approccio dominante e, così come la qualità dei dati ha influito sull'ML, quest'ultimo sta cambiando la metodologia di implementazione DQ. La DQ è sempre stata una competenza IT: gli analisti studiavano i dati, ne comprendevano i pattern (profilazione) e stabilivano le regole di pulizia e di corrispondenza (standardizzazione). Dopo la definizione e la messa in pratica delle regole, si passava ai tentativi di misurazione della qualità di ciascun set di dati a intervalli regolari.
Perché usare l’apprendimento automatico nella qualità dei dati
Limitazioni del processo DQ tradizionale
Esaminiamo le limitazioni dell'approccio tradizionale alla corrispondenza dei dati. Finora i criteri di selezione sono in gran parte dipesi dalla definizione e dalla scelta dei parametri ponderali corretti. Queste attività, per loro stessa natura, sono molto manuali e pertanto suscettibili di errori sostanziali. Inoltre, la definizione delle regole di corrispondenza richiede grandi quantità di tempo. Le organizzazioni impiegano mesi per formulare e mettere a punto tali regole.
Un'altra limitazione è rappresentata dalle dimensioni di ciascun blocco di dati. Se sono troppo grandi, le prestazioni del processo di corrispondenza sono gravemente compromesse. Anche la variabilità dei canoni di qualità dei set di dati rende inefficienti le regole. Questo è il motivo per cui le organizzazioni di solito seguono rigide linee guida per la corrispondenza dei dati e sono restie a usare molti algoritmi manuali, che sono più soggetti a errori. Questo aspetto può diventare drasticamente più problematico con l’aumento costante del numero di sorgenti di dati che un'azienda deve usare e abbinare per avere il quadro completo del business.
La crescita dell'ML può influire in modo considerevole sulle metodologie per la qualità dei dati. Parte dei processi di standardizzazione, in particolare la corrispondenza dei dati, potrebbe essere automatizzata configurando un modello di ML in modo che impari a riconoscere e prevedere le corrispondenze come operazione di routine. Dopo il lavoro manuale iniziale di impostazione delle etichette, i modelli di ML possono iniziare ad apprendere dai nuovi dati inviati alla standardizzazione. Più dati vengono forniti al modello, migliori saranno le prestazioni dell'algoritmo ML e più accurati i risultati. È per questo che l'ML risulta più scalabile rispetto agli approcci tradizionali. Le aziende non hanno bisogno di limitare il volume di dati o il numero di fonti per identificare le regole di corrispondenza. Detto questo, c'è anche la necessità di avere sistemi progettati per misurare le prestazioni del modello ML stesso.
La divulgazione dell'apprendimento automatico
Secondo alcuni studi, il 22% delle aziende contattate ha già implementato algoritmi di apprendimento automatico nelle proprie piattaforme di gestione dei dati. La NASA, ad esempio, ha scoperto una quantità di applicazioni di apprendimento automatico mentre valutava la qualità dei dati scientifici, come il rilevamento di valori insoliti e l'individuazione delle anomalie.
L'utilizzo dell'ML si sta diffondendo perché i motori di elaborazione dei big data, come Spark, consentono oggi agli sviluppatori di usare librerie di apprendimento automatico per elaborare il proprio codice. Ogni libreria ML attualmente disponibile tramite Spark è anche a disposizione degli sviluppatori Talend. La release dell'inverno 2017 di Talend Data Fabric ha inoltre introdotto dei componenti ML per la corrispondenza dei dati: tMatchpairing, tMatchModel e tMatchPredict. Di seguito è illustrata una panoramica delle operazioni necessarie per usare questi componenti allo scopo di prevedere i risultati della corrispondenza.
Corrispondenza dei dati con apprendimento automatico in 4 semplici passaggi
- Passaggio 1. Si esegue un’analisi preliminare del set di dati con il componente tMatchpairing, che evidenzia i dati sospetti il cui punteggio di corrispondenza cade tra la soglia e il punteggio prestabilito. Anche i punteggi di corrispondenza rientrano nel set di dati.
- Passaggio 2. I data steward etichettano i record di corrispondenze sospette come "match" e "non-match". È un procedimento manuale, ma può essere ottimizzato avvalendosi della console Talend Stewardship.
- Passaggio 3. Un campione di risultati ottenuti nel passaggio 2 viene inviato a tMatchModel per l'apprendimento e l'output diventa un modello di classificazione ML. La convalida del modello avviene automaticamente tramite il componente tMatchPredict.
- Passaggio 4. Il modello generato nel passaggio 3 è pronto per prevedere le corrispondenze delle nuove sorgenti di dati.
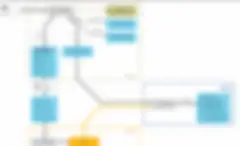
Per riepilogare, abbinando l'efficacia dell'apprendimento automatico di Spark e i processi di qualità dei dati, è possibile usare questo flusso di lavoro per prevedere automaticamente le corrispondenze dei set di dati. Non vi sono limitazioni alla quantità di dati, in quanto il processo viene eseguito automaticamente sui nodi dei cluster di big data, sfruttando il framework di elaborazione distribuita di Apache Spark. Pertanto, le aziende che già dispongono di data scientist possono avvalersi di questo flusso di lavoro non solo per le procedure analitiche ma anche per i progetti di gestione dei dati. È ovvio, però che, l'uso dell'apprendimento automatico nella gestione dei dati è ancora agli albori. Sono necessari ulteriori studi per scoprire se l'ML possa essere d’aiuto in concetti di gestione dei dati più avanzati, come il Master Data Management (MDM) e la stewardship dei dati.
Riferimenti:
