Einsatz von maschinellem Lernen für Data Quality
In meinem letzten Blogeintrag ging es um die wichtigsten Big Data-Governance-Herausforderungen und die große Rolle, die Data Quality (DQ) für Data Governance spielt. In diesem Blogeintrag möchte ich mich darauf konzentrieren, wie Big Data die Vorgehensweise beim Datenqualitätsmanagement verändert.
Big Data hat maschinelles Lernen (ML) zum Mainstream gemacht und genauso wie DQ ML beeinflusst hat, so verändert auch ML die Vorgehensweise bei der DQ-Implementierung. Für DQ sind traditionell die IT und ihre Analysten zuständig: Sie schauen sich die Daten an, untersuchen Muster (Profiling) und legen Regeln für die Datenbereinigung und den Datenabgleich (Standardisierung) fest. Nach der Erstellung und Implementierung der Regeln wird versucht, die Qualität der einzelnen Datensätze in regelmäßigen Abständen zu messen.
Was bringt ML im Bereich DQ?
Nachteile traditioneller DQ-Prozesse
Schauen wir uns zunächst einmal an, welche Nachteile die traditionelle Vorgehensweise beim Datenabgleich hat. Bisher hingen die Auswahlkriterien stark von der Blockbildung und Auswahl korrekter Gewichtungen ab. Das ist naturgemäß ein ziemlich manueller Prozess, der anfällig für gravierende Fehler ist. Abgleichsregeln zu definieren ist außerdem sehr zeitaufwändig. Organisationen brauchen Monate für die Festlegung und Feinabstimmung von Abgleichsregeln.
Ein weiterer Nachteil ist die Größe der einzelnen Datenblöcke. Ist der Block zu groß, kann dies die Performance beim Abgleich erheblich beeinträchtigen. Weisen die Datensätze große Unterschiede bei der Qualität auf, macht auch dies die Regeln ineffizient. Aus diesem Grund haben Organisationen üblicherweise strenge Richtlinien für den Datenabgleich und nutzen nur ungern manuelle Algorithmen, die anfälliger für Fehler sind. Dieses Problem kann zu einer enormen Herausforderung werden. Denn täglich kommen mehr Datenquellen hinzu, die extrahiert und abgeglichen werden müssen, um ein vollständiges Bild vom Unternehmen zu erhalten.
Der Siegeszug von ML könnte die Vorgehensweise beim Datenqualitätsmanagement nachhaltig beeinflussen. Im Rahmen der Standardisierung könnte speziell der Datenabgleich automatisiert werden, indem ein ML-Modell dazu gebracht wird, die Treffer zu „erlernen“ und routinemäßig vorherzusagen. Nachdem die Labels am Anfang manuell eingerichtet wurden, können die ML-Modelle anfangen, von den neuen Daten zu lernen, die zur Standardisierung gesendet wurden. Je mehr Daten das Modell erhält, desto besser kommt der ML-Algorithmus zurecht und desto genauere Ergebnisse kann er liefern. Daher ist ML im Vergleich zu traditionellen Ansätzen skalierbarer. Unternehmen müssen weder die Datenmenge noch die Anzahl der Quellen einschränken, um Abgleichsregeln zu identifizieren. Allerdings werden auch Systeme gebraucht, um die Performance des ML-Modells selbst zu messen.
Maschinelles Lernen wird Mainstream
Gemäß mehreren Umfragen haben 22 Prozent der befragten Unternehmen bereits ML-Algorithmen in ihren Datenmanagementplattformen implementiert. Die NASA zum Beispiel hat zahlreiche ML-Anwendungen für sich entdeckt, mit denen sie die Qualität der wissenschaftlichen Daten bewertet (z. B. durch die Erkennung ungewöhnlicher Datenwerte und Anomalien).
ML wird Mainstream, weil Entwickler mit Big Data-Verarbeitungsengines wie Spark jetzt ML-Bibliotheken zur Codeverarbeitung nutzen können. Jede der aktuell über Spark verfügbaren ML-Bibliotheken steht auch Talend-Entwicklern zur Verfügung. Mit dem Winter ’17-Release von Talend Data Fabric wurden auch Komponenten für den Datenabgleich eingeführt: tMatchpairing, tMatchModel und tMatchPredict. Im Folgenden finden Sie eine Übersicht der Prozesse, die Sie benötigen, um mit diesen Komponenten Abgleichsergebnisse vorherzusagen.
Datenabgleich mit maschinellem Lernen in 4 einfachen Schritten
- Schritt 1: Führen Sie mit der tMatchpairing-Komponente eine Voranalyse des Datensatzes durch. So werden verdächtige Daten ermittelt, deren Abgleichswert zwischen dem Schwellen- und Abgleichswert liegt. Die Abgleichswerte wären auch der Teil des Datensatzes.
- Schritt 2: Data-Stewards kennzeichnen anschließend den verdächtigen Abgleichseintrag als „Treffer“ und „kein Treffer“. Diese manuelle Tätigkeit lässt sich mit der Talend Stewardship-Konsole optimieren.
- Schritt 3: Ein Muster des Ergebnissatzes aus Schritt 2 wird in das tMatchModel zum „Lernen“ eingespielt. Die Ausgabe würde ein ML-Klassifizierungsmodell sein. Die Modellvalidierung erfolgt automatisch hier mit der tMatchPredict-Komponente.
- Schritt 4: Das in Schritt 3 generierte Modell kann nun eingesetzt werden, um Treffer für neue Datenquellen vorherzusagen.
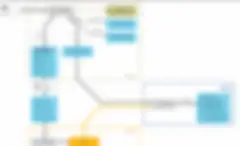
Kurz gesagt: Wenn die Vorteile von ML mit Spark und Datenqualitätsprozessen kombiniert werden, lassen sich mit diesem Workflow Treffer für Datensätze automatisch vorhersagen. Damit ist die Datenmenge kein Nachteil, denn der Prozess würde automatisch auf den Knoten der Big Data-Cluster laufen und das verteilte Verarbeitungsframework von Apache Spark nutzen. Daher können Unternehmen, die bereits Data Scientists beschäftigen, diesen Workflow nicht nur für Analysen, sondern auch für ihre Datenmanagementprojekte nutzen. Aber es ist klar, dass wir beim Einsatz von ML für das Datenmanagement noch ganz am Anfang stehen. Hier muss noch genauer untersucht werden, wie ML bei anspruchsvolleren Datenmanagementkonzepten wie MDM und Data Stewardship helfen kann.
Quellenangaben:
The Blueprint for Becoming Data-Driven (Das Konzept für datengestützte Unternehmen)

Weitere Artikel zu diesem Thema
- Data-Profiling: Definition, Tools und Nutzen
- Datenintegrität: Bedeutung, Arten & Risiken
- Durch hohe Datenqualität richtige Entscheidungen treffen
- Was ist Datenredundanz?
- Datensynchronisation: Definition, Methoden, Herausforderungen
- Leistungsstarkes Datenqualitätsmanagement mit Talend
- Data Quality Tools richtig auswählen und Datenqualität sichern