機械学習を生かしたデータクオリティ
前回のブログでは、ビッグデータにおけるデータガバナンスの課題と、データクオリティ(DQ)がデータガバナンスの大きな部分を占めていることについて説明しました。このブログでは、ビッグデータがDQの手法をどのように変えているかに焦点を当てます。
ビッグデータによって機械学習(ML)が主流になりました。DQがMLに影響を与えたように、MLもDQの実装のあり方を変えています。DQは従来、IT内のタスクであり、アナリストはデータを調べ、パターンを理解し(プロファイリング)、そしてデータのクレンジングとマッチングのルールを確立します(標準化)。ルールが確立され本番化された後、定期的に各データセットの品質が測定されます。
DQでMLを使用する理由
従来のDQプロセスの制約
従来のデータマッチングにおけるアプローチの限界について検討してみましょう。今まで、選択基準はブロッキングと適切な重みの選択に大きく依存していました。これらの活動は、その性質上、主に手動で行われるため、多くのエラーが生じる可能性があります。マッチングルールの定義も非常に時間のかかるプロセスです。組織は、マッチングルールを定義して微調整するのに何か月もかける必要があります。
もう1つの制限は、各データブロックのサイズです。ブロックのサイズが大きすぎると、マッチングプロセスのパフォーマンスに大きな影響を与える可能性があります。データセット間で品質に大きな変動がある場合も、ルールが非効率になります。このため、組織は通常、データマッチングに厳密なガイドラインを使用しており、エラーを起こしやすい手作業でのアルゴリズムの使用には消極的です。企業の全体像を把握するために抽出・照合する必要があるデータソースの数が日々増加しているため、この問題はさらに困難になる可能性があります。
MLの台頭は、DQの手法に劇的な影響を与える可能性があります。標準化プロセスの一部、特にデータマッチングは、MLモデルを「学習」させて定型タスクとして一致を予測させることにより自動化できます。ラベルをセットアップするための最初の手作業の後、MLモデルは標準化のために提出された新しいデータから学習を開始できます。モデルに提供されるデータが多いほど、MLアルゴリズムのパフォーマンスが高くなり、より正確な結果を提供できるようになります。したがって、MLは従来のアプローチと比較して、より優れた拡張性を持ちます。企業は、マッチングルールを識別するためにデータの量やソースの数を制限する必要はありません。ただし、MLモデル自体のパフォーマンスを測定するために設計されたシステムも必要です。
機械学習が主流に
いくつかの調査によると、企業の22%はすでにデータ管理プラットフォームに機械学習アルゴリズムを実装しています。たとえばNASAは、通常とは異なるデータ値の検出や異常検出など、科学データの品質の評価で機械学習に多くの用途を見出しています。
MLが主流になりつつあるのは、Sparkのようなビッグデータ処理エンジンによって開発者がコードの処理にMLライブラリーを使用できるようになったためです。現在Sparkを通じて利用可能なMLライブラリーのそれぞれはTalend開発者にも利用可能です。Winter ’17のリリースのTalend Data Fabricでは、データマッチング用のMLコンポーネントも導入されました(tMatchpairing、tMatchModel、tMatchPredict)。以下は、これらのコンポーネントを使用してマッチング結果を予測するために必要なプロセスの概要です。
4つの簡単なステップで機械学習をデータマッチングに活用
- ステップ1:tMatchpairingコンポーネントを使用してデータセットを事前分析します。これにより、一致スコアがしきい値と一致スコアの間にある疑わしいデータが発見されます。一致スコアもデータセットの一部になります
- ステップ2:データスチュワードが、疑わしい一致レコードに「一致」と「不一致」のラベルを付けます。これは手動のプロセスであり、Talend Stewardshipコンソールを利用すると、このラベリングを合理化できます。
- ステップ3:ステップ2からの結果セットのサンプルが、「学習」のためにtMatchModelに供給され、出力はML分類モデルになります。モデル検証は、ここではtMatchPredictコンポーネントを使用して自動的に行われます。
- ステップ4:新しいデータソースの一致を予測するために、ステップ3で生成されたモデルを使用する準備が整います。
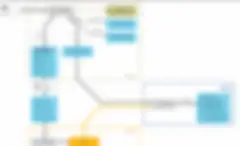
要約すると、MLの能力とSparkおよびデータクオリティプロセスを組み合わせることで、このワークフローを使用してデータセットの一致を自動的に予測できます。Apache Sparkの分散処理フレームワークを利用して、ビッグデータクラスターのノード上でプロセスが自動的に実行されるため、データ量に制限はありません。したがって、すでにデータサイエンティストを抱えている企業は、このワークフローを分析だけでなくデータ管理プロジェクトにも使用できます。しかし、データ管理でのMLの使用がまだ初期段階にあることは明らかです。MDMやデータスチュワードシップなど、より高度なデータ管理でMLを活用する方法については、さらに研究を進める必要があります。
参考文献:
