Talend Job Design Patterns and Best Practices: Part 1
Talend developers everywhere, from beginners to the very experienced, often deal with the same question: “What is the best way for me to write this job”? We know it should be efficient, easy to read, easy to write, and above all (in most cases), easy to maintain. We also know that the Talend Studio is a free-form ‘Canvas’ upon which we ‘Paint’ our code using a comprehensive and colorful pallet of Components, Repository Objects, Metadata, and Linkage Options. How then are we ever sure that we’ve created a job design using the Best Practices?
Job Design Patterns
Since version 3.4, when I started using Talend, job designs were very important to me. At first, I did not think of patterns while developing my jobs; I had used Microsoft SSIS and other similar tools before, so a visual editor like Talend was not new to me. Instead, my focus centered on basic functionality, code reusability, then canvas layout and finally naming conventions. Today, after developing hundreds of Talend jobs for a variety of use cases, I found my code becoming more refined, more reusable, more consistent, and yes patterns started to emerge.
After joining Talend in January this year I’ve had many opportunities to review jobs developed by our customers. It confirmed my perception that for every developer there are indeed multiple solutions for each use case.
This, I believe compounds the problem for many of us. We developers do think alike, but just as often we believe our way is the best or the only way to develop a particular job. Inherently we also know, quietly haunting us upon our shoulder, whispering in our ear, that maybe, just maybe there is a better way. Hence we look or ask for best practices: in this case — Job Design Patterns!
Formulating the Basics
When I consider what is needed to achieve the best possible job code, fundamental precepts are always at work. These come from years of experience making mistakes and improving upon success. They represent important principles that create a solid foundation upon which to build code and should be (IMHO) taken very seriously; I believe them to include (in no particular order of importance):
— Readability: creating code that can be easily figured out and understood
— Writability: creating straightforward, simple, code in the least amount of time
— Maintainability: creating appropriate complexity with minimal impact from change
— Functionality: creating code that delivers on the requirements
— Reusability: creating sharable objects and atomic units of work
— Conformity: creating real discipline across teams, projects, repositories, and code
— Pliability: creating code that will bend but not break
— Scalability: creating elastic modules that adjust throughput on demand
— Consistency: creating commonality across everything
— Efficiency: creating optimized data flow and component utilization
— Compartmentation: creating atomic, focused modules that serve a single purpose
— Optimization: creating the most functionality with the least amount of code
— Performance: creating effective modules that provide the fastest throughput
Achieving a real balance across these precepts is the key; in particular, the first three as they are in constant contradiction which each other. You can often get two, while sacrificing the 3rd. Try ordering all of these by importance, if you can!
Guidelines NOT Standards — It’s about Discipline!
Before we can really dive into Job Design Patterns, and in conjunction with the basic precepts I’ve just illustrated, let’s make sure we understand some additional details that should be taken into account. Often I find rigid standards in place which make no room for the unexpected situations that often poke holes into them. I also find, far too often, the opposite; unyielding, unkempt, and incongruous code from different developers doing basically the same thing; or worse, developers propagating confusing clutters of disjointed, unplanned, chaos. Frankly, I find this sloppy and misguided as it really does not take much effort to avoid.
For these and other fairly obvious reasons, I prefer first to craft and document ‘Guidelines’, not ‘Standards’.
These encompass the foundational precepts and attach specifics to them. Once a ‘Development Guidelines’ document is created and adopted by all the teams involved in the SDLC (Software Development Life Cycle) process, the foundation supports structure, definition, and context. Invest in this, and long-term, get results that everyone will be happy with!
Here is a proposed outline that you may utilize for yours (feel free to change/expand on this; heck it’s only a guideline!).
- Methodologies which should detail HOW you want to build things
- Data Modeling
- Holistic / Conceptual / Logical / Physical
- Database, NoSQL, EDW, Files
- SDLC Process Controls
- Waterfall or Agile/Scrum
- Requirements & Specifications
- Error Handling & Auditing
- Data Governance & Stewardship
- Data Modeling
- Technologies which should list TOOLS (internal & external) and how they interrelate
- OS & Infrastructure Topology
- DB Management Systems
- NoSQL Systems
- Encryption & Compression
- 3rd Party Software Integration
- Web Service Interfaces
- External Systems Interfaces
- Best Practices which should describe WHAT & WHEN particular guidelines are to be followed
- Environments (DEV/QA/UAT/PROD)
- Naming Conventions
- Projects & Jobs & Joblets
- Repository Objects
- Logging, Monitoring & Notifications
- Job Return Codes
- Code (Java) Routines
- Context Groups & Global Variables
- Database & NoSQL Connections
- Source/Target Data & Files Schemas
- Job Entry & Exit Points
- Job Workflow & Layout
- Component Utilization
- Parallelization
- Data Quality
- Parent/Child Jobs & Joblets
- Data Exchange Protocols
- Continuous Integration & Deployment
- Integrated Source Code Control (SVN/GIT)
- Release Management & Versioning
- Automated Testing
- Artifact Repository & Promotion
- Administration & Operations
- Configuration
- User Security & Authorizations
- Roles & Permissions
- Project Management
- Job Tasks, Schedules, & Triggers
- Archives & Disaster Recovery
Some additional documents I think should be developed and maintained include:
— Module Library: describing all reusable projects, methods, objects, joblets, & context groups
— Data Dictionary: describing all data schemas & related stored procedures
— Data Access Layer: describing all things pertinent to connecting to and manipulating data
Sure creating documentation like this takes time but the value, over its lifetime, far outweighs its cost. Keep it simple, direct, up-to-date, (it doesn’t need to be a manifesto) and it will make huge contributions to the success of all your projects that utilize it by dramatically reducing development mistakes (which can prove to be even more expensive).
Can We Talk About Job Design Patterns Now?
Sure! But first: one more thing. It is my belief that every developer can develop both good and bad habits when writing code. Building upon the good habits is vital. Start out with some easy habits, like always giving every component a label. This makes the code more readable and understandable (one of our foundational precepts). Once everyone is making a habit of that, ensure that all jobs are thoughtfully organized into repository folders with meaningful names that make sense for your projects (yes, conformity). Then have everyone adopt the same style of logging messages, perhaps using a common method wrapper around the System.out.PrintLn()function; and establish a common entry/exit point criterion with options for alternative requirements, for job code (both of these help realize several precepts all at once). Over time, as development teams adopt and utilize well defined Development Guideline disciplines, project code becomes easier to read, to write, and (my favorite) to maintain by anyone on the team.
Job Design Patterns and Best Practices
For me, Talend Job Design Patterns present us with a proposed template or skeleton layouts that involve essentail and/or required elements that focus on a particular use case. Patterns because often they can be reused again for similar job creation, thus jumpstarting the code development effort. As you might expect, there are also common use patterns that can be adopted over several different use cases which, when identified and implemented properly, strengthen the overall code base, condense effort, and reduce repetitive but similar code. So, let’s start there.
Here are 7 Best Practices to consider:
Canvas Workflow & Layout
There are many ways to place components on the job canvas, and just as many ways to link them together. My preference is to fundamentally start ‘top to bottom’, then work ‘left and right’ where a left bound flow is generally an error path, and a right and/or downward bound flow is the desired, or normal path. Avoiding link lines that cross over themselves wherever possible is good, and as of v6.0.1, the nicely curved link lines adopt this strategy quite well.
For me, I am uncomfortable with the ‘zig-zag’ pattern, where components are placed ‘left to right’ serially, then once it goes to the rightmost edge boundary the next component drops down and back to the left side edge for more of the same; I think this pattern is awkward and can be harder to maintain, but I get it (easy to write). Use this pattern if you must but it may indicate the possibility that the job is doing more than it should or may not be organized properly.
Atomic Job Modules — Parent/Child Jobs
Big jobs with lots of components, simply put, are just hard to understand and maintain. Avoid this by breaking them down into smaller jobs, or units of work wherever possible. Then execute them as child jobs from a parent job (using the tRunJob component) whose purpose includes the control and execution of them. This also creates the opportunity to handle errors better and what happens next. Remember a cluttered job can be hard to understand, difficult to debug/fix, and almost impossible to maintain. Simple, smaller jobs that have clear purpose jump off the canvas as to their intent, almost always easy to debug/fix, and maintenance, comparatively a breeze.
While it is perfectly acceptable to create nested Parent/Child job hierarchies, there are practical limitations to consider. Depending upon job memory utilization, passed parameters, test/debug concerns, and parallelization techniques (described below), a good job design pattern should not exceed 3 nested levels of tRunJob Parent/Child calls. While it is safe to perhaps go deeper, I think that with good reasons, 5 levels should be more than enough for any use case.
tRunJob vs Joblets
The simple difference between deciding between a child job versus using a joblet is that a child job is ‘Called’ from your job and a joblet is ‘Included’ in your job. Both offer the opportunity to create reusable, and/or generic code modules. A highly effective strategy in any Job Design Pattern would be to properly incorporate their use.
Entry and Exit Points
All Talend Jobs need to start and end somewhere. Talend provides two basic components: tPreJob and tPostJob whose purpose is to help control what happens before and after the content of a job executes. I think of these as ‘Initialize’ and ‘WrapUp’ steps in my code. These behave as you might expect in that the tPreJob executes first, then the real code gets executed, then finally the tPostJob code will execute. Note that the tPostJob code will execute regardless of any devised exit within the code body (like a tDie component, or a component checkbox option to ‘die on error’) is encountered.
Using the tWarn and tDie components should also be part of your consideration for job entry and exit points. These components provide programmable control over where and how a job should complete. It also supports improved error handling, logging, and recovery opportunities.
One thing I like to do for this Job Design pattern is to use the tPreJob to initialize context variables, establish connections, and log important information. For the tPostJob: closing connections and other important cleanup and more logging. Fairly straightforward, right? Do you do this?
Error Handling and Logging
This is very important, perhaps critical, and if you create a common job design pattern properly, a highly reusable mechanism can be established across almost all your projects. My job pattern is to create a ‘logPROCESSING’ joblet for a consistent, maintainable logging processor that can be included into any job, PLUS incorporating well defined ‘Return Codes’ that offers conformity, reusability, and high efficiency. Plus is was easy to write, is easy to read, and yes, quite easy to maintain. I believe that once you’ve developed ‘your way’ for handling and logging errors across your project jobs, there will be a smile on your face a mile wide. Adapt and Adopt!
Recent versions of Talend have added support for the use of Log4j and a Log Server. Simply enable the Project Settings>Log4j menu option and configure the Log Stash server in the TAC. Incorporating this basic functionality into your jobs is definitely a Good Practice!
OnSubJobOK/ERROR vs OnComponentOK/ERROR (& Run If) Component Links
It can be a bit confusing sometimes to any Talend developer what the differences between the ‘On SubJob’ or the ‘On Component’ links are. The ‘OK’ versus ‘ERROR’ is obvious. So what are these ‘Trigger Connections’ differences and how do they affect a job design flow?
‘Trigger Connections’ between components define the processing sequence and data flow where dependencies between components exist within a subjob. Subjobs are characterized by a component having one or more components linked to it dealing with the current data flow. Multiple subjobs can exist within a single job and is visualized by default as having a blue highlighted box (which can be toggled on/off on the toolbar) around all the related subjob components.
An ‘On Subjob OK/ERROR’ trigger will continue the process to the next ‘linked’ subjob after all components within the subjob have completed processing. This should be used only from the starting component in the subbjob. An ‘On Component OK/ERROR’ trigger will continue the process to the next ‘linked’ component after that particular component has completed processing. A ‘Run If’ trigger can be quite useful when the continuation of the process to the next ‘linked’ component is based upon a programmable java expression.
What is a Job Loop?
Significant to almost every Job Design Pattern is the ‘Main Loop’ and any ‘Secondary Loops’ in the code. These are the points where control of the potential exit of a job’s execution is made. The ‘Main Loop’ generally is represented by the top-most processing of a data flow result set that once complete, the job is finished. ‘Secondary Loops’ are nested within a higher-order loop and often require considerable control to ensure a jobs proper exit. I always identify the ‘Main Loop’ and ensure that I add a tWarn and a tDie component to the controlling comonent. The tDie usually is set to exit the JVM immediately (but note that even then the tPostJob code will execute). These top level exit points use a simple ‘0’ for success and ‘1’ for failure return code, but following your established ‘Return Codes’ guideline is best. ‘Secondary Loops’ (and other critical components in the flow) are great places to incorporate additional tWarn and tDie components (where the tDie is NOT set to exit the JVM immediately).
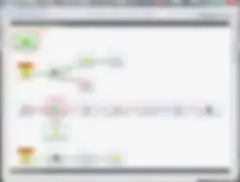
Most of the Job Design Pattern Best Practices discussed above are illustrated below. Notice, while I’ve adopted useful component labels, even I’ve bent the rules a bit on component placements. Regardless the result is a highly readable, maintainable job that was fairly wasy to write.
Conclusion
Well — I can’t say that all your questions about Job Design Patterns have been answered here; probably not in fact. But it’s a start! We’ve covered some fundamentals and proffered a direction and end game. Hopefully, it has been useful and provokes some insightful considerations for you, my gentle reader.
Clearly, I’ll need to write another Blog (or perhaps a few) on this topic to cover everything. The next one will focus on some valuable advanced topics and several Use Cases that we all are likely to encounter in some form. Additionally, the Customer Success Architecture team is working on some sample Talend code to support these use cases. These will be available in the Talend Help Center for subscribed customers fairly soon. Stay on the lookout for them.
Products Mentioned

More related articles
- What are Data Silos?
- What is Data Extraction? Definition and Examples
- What is Customer Data Integration (CDI)?
- Talend Job Design Patterns and Best Practices: Part 4
- Talend Job Design Patterns and Best Practices: Part 3
- What is Data Migration?
- What is Data Mapping?
- What is Database Integration?
- What is Data Integration?
- Understanding Data Migration: Strategy and Best Practices
- Talend Job Design Patterns and Best Practices: Part 2
- What is change data capture?
- Experience the magic of shuffling columns in Talend Dynamic Schema
- Day-in-the-Life of a Data Integration Developer: How to Build Your First Talend Job
- Overcoming Healthcare’s Data Integration Challenges
- An Informatica PowerCenter Developers’ Guide to Talend: Part 3
- An Informatica PowerCenter Developers’ Guide to Talend: Part 2
- 5 Data Integration Methods and Strategies
- An Informatica PowerCenter Developers' Guide to Talend: Part 1
- Best Practices for Using Context Variables with Talend: Part 2
- Best Practices for Using Context Variables with Talend: Part 3
- Best Practices for Using Context Variables with Talend: Part 4
- Best Practices for Using Context Variables with Talend: Part 1