クラウドにおける「管理されたデータレイク」
投稿者:Dale T. Anderson(Talend、リージョナルマネージャー、カスタマーサクセスアーキテクト)、Kent Graziano(Snowflake社、シニアテクニカルエバンジェリスト)
ここでは、データレイクの構築について取り上げます。データレイクを使用すると、データウェアハウスが不要になり、ビジネスユーザー全員がビジネス分析を簡単に引き出せるようになるのでしょうか。また、Hadoopのようなビッグデータテクノロジーにすべて放り込むだけで、データの課題をすべて解決し、Sparkで高速データ処理を実現し、機械学習の高度な洞察から魔法のように競争力を得られるのでしょうか。あるいは、NoSQLを使えばデータモデルは不要になるのでしょうか。
そのような認識は、大半が根拠のない誇大宣伝です。新しいデータレイクが実際にはデータスワンプとなっている場合、あらゆるソースから集められたデータで汚染され、有意義な情報をどこにも提供できない状態であるなどと、上司に説明しても理解してもらえないのではないでしょうか。そのような状況に陥らないためにも、TalendとSnowflake Elastic Data Warehouseを使用して、より良いソリューションを構築することを検討してください。
データレイクの構築を成功させるには、取り組みを始める前に、いくつかのよくある誤解を解く必要があります。
- データレイクとは(あるべき姿)
- すべてのビジネスデータを一元的に格納
- リネージと履歴を管理する公開のデータ辞書(または用語集)
- ソースデータと有意義なメタデータモデルの融合
- ビジネス運営/報告上の多数のニーズに使用可能
- ほぼすべてのビジネスニーズに適したスケーラビリティ、適応性、堅牢性
- データレイクではないもの(または、避けるべき状態)
- 「新しい」エンタープライズデータウェアハウス
- HadoopまたはNoSQLベースであることが必要
- すばやく簡単にアクセスできる、追加のデータサイロ
- データ統合と処理の必要性を排除できる
- 非常に現実的な価値のある最新トレンド
- IoT/アナリティクス/AI機能専用
それでは、なぜ「データレイク」を構築する必要があるのでしょうか。データレイクの主な目的は、多様で(場合によっては)限られたデータセットを散在した異種のデータサイロに格納する代わりに、生の(フィルタリングされていない)組織データへの完全かつ直接的なアクセスを提供することです。たとえば、1つのデータマートにERPデータがあり、別のファイルサーバーにウェブログがある場合、それらを結合するクエリーでは複雑なフェデレーションスキーム(および追加のソフトウェア)が必要になることがよくあり、大きな労力が伴います。理想的には、データレイクを使用することで単一の大規模なリポジトリにすべてのデータが格納されるので、データに簡単にアクセスして、どのようなクエリーでも実行できます。
適切に設計され管理されたデータレイクを使用すると、すべての必要なデータをまとめてロードでき、それぞれのビジネスユースケースを簡単かつシームレスにサポートできます。従来のビジネスインテリジェンスのレポート作成やアナリティクスから、データサイエンスチームによるデータの探索、ディスカバリー、実験まで、すべてを提供できるので、上司から一目置かれるようになるでしょう。
目標とするメリットを実現する「データレイク」を構築するには、何が必要でしょうか。大量のデータが関与する複雑なソフトウェアプロジェクトと同様に、最初にやるべきことは真剣に検討することです。適切に設計されたデータレイクには、構築の労力をはるかに上回る潜在的メリットがあります。したがって、何を期待すべきかを適切に設定することが非常に重要です。測定可能な結果はすぐには現れないかもしれません。時間をかけて、取り組みとタイムラインを編成/設計/計画する必要があります。「アジャイル」のアプローチも効果的でしょうが、長期的な目標を設定し、チームがサポート/調整/順応できる歩調で進めることで、必ず達成できます。
さらに、大量のデータを伴う複雑なソフトウェアプロジェクトと同様に、以下の3つの重要事項を慎重に検討する必要があります。
- 人
- 「すべての」ビジネスステークホルダーを巻き込みます。これらの人々のデータなのですから!
- 必要に応じて技術専門家の関与を仰ぎます。あるいは、専門知識を習得します!
- プロセス
- 適切で柔軟なガイドラインを作成し、それに従います。文書化しましょう!
- 後付けではなく、ルールとしてデータガバナンスを確立します。
- 適切な方法論(SDLCとデータモデリング)を取り入れます。
- ベストプラクティスを使用します。一貫性を保ちましょう。
- テクノロジー
- 適切なツールを使用し、それらの使用方法を把握します!
アーキテクチャーとインフラストラクチャ
データレイクに関しては、その優れた機能を理解すると同時に、何を期待すべきかを適切に設定することが重要です。新しく登場した用語と同様に、データレイクが何であるか、いかに活用すべきかについて、誤って解釈/表現されがちです。ステークホルダーは独自の考えを持っていることがあり(非現実的な期待感を呼び起こす業界の誇大宣伝によって、しばしば偏った考えに陥る可能性もあります)、問題のあるコミュニケーション、間違ったテクノロジー、不適切な方法論といった破滅的な事態がもたらされる可能性があります。これを避ける必要があります。
「管理されたデータレイク」を実現するには、本質的に、データを格納するための堅牢なデータ統合プロセスと共に、データを取得するための適切なデータ系列(ロード日とソースなど)を含む有意義なメタデータが必要です。これらの重要な属性がなければ、「データスワンプ」が発生する可能性が非常に現実的になります。これを念頭に置いて、2つの重要なエコシステムを見てみましょう。
- オンプレミス
- これに関与するものとしては、RDBMSやビッグデータインフラストラクチャがあります。
- 通常は、制御された/安全なアクセスによって自己管理されます。
- ソースのデータとなる可能性が高いですが、排他的ではありません。
- 従来のITサポート、制約、遅延を伴います。
- クラウド
- これに関与するのはSaaSアプリケーションです。
- 通常、アクセスのためのユーザーロール/権限を使用してホストされます。
- プロセスは、クラウドからクラウド、クラウドからオンプレミス、またはオンプレミスからクラウドです。
- TCOが低く、弾力的な柔軟性、そしてグローバルなユーザビリティがあります。
オンプレミスとクラウド
アーキテクチャーとインフラストラクチャの構築方法は、要件に応じて異なります。データレイクプロジェクトの初期段階での選択肢が、直接得られるメリットに反映されます。TalendとSnowflakeが連携することで、これら両方のエコシステムが可能になります。この点について見ていきましょう。
オプション1 — オンプレミスのTalendとクラウドのSnowflake
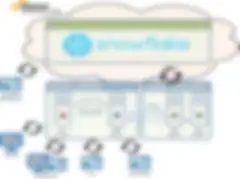
この最初のオプションは、Talendがローカルでデータセンターにインストールされて実行され、SnowflakeがホストされたAWSプラットフォームで実行されます。実行サーバーはTalendジョブを実行し、ジョブは必要に応じてSnowflakeに接続し、データを処理します。
これは、「データレイク」関連ばかりではない、ソース/ターゲットデータの広範なユースケースでTalendサービスをサポートしたい場合に適したオプションです。
オプション2 - クラウドのTalendとSnowflake
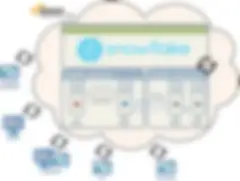
2番目のオプションはTalendのインストールをクラウドに移します(たとえば、AWSでホスト)。実行サーバーは、AWSプラットフォームの弾力的な使用を制御するジョブ用に現在使用可能な新しいAWSコンポーネントをいくつか使用するなどして、クラウドでジョブを実行します。これらのジョブは、Snowflakeや、クラウドのエコシステムから入手可能な任意のソース/データに接続できます。これは、クラウドに保存されているファイルからデータレイクに直接データを取り込む場合や、Talendへのアクセスを必要とするユーザーが世界中に分散している場合に最適な選択肢です。
データの統合と処理
データレイクにデータを投入する際はどうしても力任せになります。データを引き出すのはさらに大きな労力を要します。したがって、強力なETL/ELTデータ統合および処理の機能は明らかに不可欠です。これらの要件を満たすためにTalendのソフトウェアプラットフォームで自在にコーディングできる点を、すでに理解していると仮定しましょう。Java生成ツールとして堅牢なプロセスと効率的なデータフローを作成するTalendの機能は、すでに実証済みです。Talendソフトウェアは、プロジェクト統合、共同開発、システム管理、スケジューリング、モニタリング、ロギングなど、多くの機能をサポートしています。
Talend Winter ’17リリース(v6.3.1)では1,000以上のコンポーネントを利用でき、データレイクへのデータ投入や処理のためのソリューションの作成がはるかに簡単になっています。追加の製品機能は、データクオリティ、ガバナンス、およびプレパレーションのツールをビジネスアナリストに提供します。Talendのメタデータ管理ツールは、データの詳細を用語集にまとめることで、スキーマが変化しても履歴のリネージを維持でき、必要に応じてTalendジョブの生成をサポートします。
Talendが最近リリースした新しいSnowflakeコンポーネントは、ジョブに役立ちます。新しいコンポーネントフレームワーク(TCOMP)を使用して記述されているので、互換性があるのはTalend v6.3.1以降のみになります。したがって、使用する前に必ず正しいインストールを使用していることを確認してください。
クラウドでのサービスとしてのデータウェアハウス(DWaaS)
サービスとしてのデータウェアハウス(DWaaS)とは、何を指しているのでしょうか。まず、データウェアハウスに関連するタイプのクエリー、つまり分析クエリーや集計をサポートするために特別に設計されたRDBMSプラットフォームを対象にしています。そうは言っても、標準SQLを主言語として使用するツールをサポートする必要があります。データレイクのすべてのデータニーズをサポートするには、「ビッグデータ」システムと同様に、取り込みと半構造化データのクエリー機能もサポートする必要があります。
さらに、それはクラウドで「サービスとして」提供されるものでなければなりません。つまり、SaaSと同様に、セットアップ対象のインフラストラクチャがありません。構成と管理はすべてベンダーが管理します。また、弾力的な「従量制」モデルを使用する必要があります。これは、DWaaSの場合は、使用していないコンピューティング/ストレージリソースに対して費用負担が発生しないことを意味します。
真のDWaaSを使用することで、組織がすべての必要なデータに簡単にアクセスできるようになるという(DWaaS本来の)目標を達成するのに役立つことから、この点を重視する必要があります。実際には、構造化データと非構造化データをすばやくロードできるだけでなく、そのデータに簡単にアクセスして、現実のビジネスの問題をタイムリーかつ費用対効果の高い方法で解決できます。これがクラウドの弾力性を利用するように設計されている場合、オンデマンドでスケールアップ/スケールダウンし、必要に応じてすべてのユーザーの同時実行性をサポートできます。
Snowflakeは、クラウド向けにサービス専用として構築された唯一のデータウェアハウスです。Snowflakeは、組織のすべてのデータを一元的に格納して分析するために必要とされるパフォーマンス、同時実行性、およびシンプルさを実現します。Snowflakeのテクノロジーは、データウェアハウジングに本来備わった力、ビッグデータプラットフォームの柔軟性、そしてクラウドの弾力性を融合して、従来のソリューションに比べてわずかなコストで提供します。
Snowflakeを優れたデータレイクプラットフォームにしている特長の1つは、ストレージとコンピューティングの革新的な分離であり、これはマルチクラスター共有データアーキテクチャーと呼ばれます。現在のオンプレミスのレガシーアーキテクチャーと異なり、Snowflakeを使用すると、コンピューティングノードに関係なくストレージのフットプリントを動的に拡大できます。同様に、より大きなコンピューティング能力が必要な場合は、ディスクドライブを追加購入することなく、コンピューティングクラスターを動的にサイズ変更してリソースを追加できます。この分離により、ウェアハウスクラスターの規模を気にせずに、テラバイトやペタバイトの単位での生データのストリーミングを実現できます。
コンピューティングとストレージを分離することで、同一の中央データストアにアクセスする複数の独立したコンピューティングクラスター(仮想ウェアハウスと呼ばれます)を構成できます。効果的に構築されたマルチテラバイトのデータレイクを使用して、データサイエンティストは完全に独立した専用のコンピューティングクラスターを自由に活用できます。このクラスターを使用して、システム上の他のユーザーに影響を与えることなく、機械学習やSparkを使用するTalendジョブを強化できます。これらの機能については、以下のページで紹介しています。
もう1つの素晴らしいSnowflake機能は「タイムトラベル」です。Snowflakeは、Type 2のSCD(Slowly Changing Dimension)のように、背後で起こるデータの経時的な変化をセットアップ/管理なしに自動追跡します。これにより、データレイクを最初から時間変数として活用できます。過去90日間のどの時点のデータオブジェクトに対してもクエリーを実行できるので、大規模で動的なデータセットの比較に最適です。
このようなツールを使えば、再びハンドコーディングしようなどと思う人はいなくなるでしょう。
SDLCとベストプラクティス
これにどのように取り組むかについて追及する余地は十分にありますが、短いブログで詳細を取り上げるには無理があるので、今回は差し控えます。
- SnowflakeとTalendによるアジャイルの実現
- Sparkによるデータレイクのロードと検索の手法
- 予測分析のための機械学習モデル
今後、これらのトピックに関してフォローアップの記事を書く機会があるかもしれません。データレイクを成功させるには、これらの詳細が検討に値します。現時点では、Talendの「ジョブ設計パターン」とベストプラクティスに関する4回シリーズをご覧ください。また、Snowflake社のブログ記事、時間とスペースを節約:高速クローン作成によるDevOpsの簡素化や、クエリーの自動最適化も参考になります。インフラストラクチャへのアプローチとデータレイクの実装については、慎重に検討しましょう。数年前には存在すらしなかった選択肢を、これらのテクノロジーによって現在利用できるようになっているのです。
データボルトのモデリング
データレイクで採用される可能性のあるデータモデリング方法論は、議論する重要性の高いトピックです。これは見過ごされがちであり、無視されることもありますが、長期的な成功を実現するための鍵となります。データボルトのアプローチについては、さまざまなブログページで説明しています。「データボルト」とは?その必要性とは?では、この革新的ソリューションの概念と価値を紹介しています。詳細な解説は、Talendとデータボルト、データボルトのモデリングとSnowflake、またはデータボルトの主要リソース一覧をご覧ください。これらの記事が皆さんの参考になることを願っています。
データモデリングとビジネスインテリジェンスに対するデータボルトのアプローチは、エンタープライズデータエコシステムを構築するうえで、非常に柔軟で適応性があり、高度に自動化可能な手法を提供し、それを非常に俊敏な方法で実現することを可能にします。データボルトのアーキテクチャーを支える要素の1つは、生のソースデータを保持するためのステージング領域の使用です。これは、再起動可能なロードプロセスを持つというデータボルトの原則をある程度サポートするものであり、データを再取得するためにソースシステムに戻る必要がなくなります。最近のあるプレゼンテーションでは、データレイクにかなり近いものであると指摘されました。
すべての行に常に「ロード日」と「レコードソース」を記録するというデータボルトの推奨事項に従うと、「管理されたデータレイク」の概念が浮かび上がってきます。次のステップは、それを永続的なステージング領域にして、「チェンジデータキャプチャー」の手法をロードプロセスに適用することです(これによって重複を防ぎます)。これで、本当の意味で「管理データレイク」を実現できました。データレイクは、有用な情報を区別/簡単に検索するための有意義なメカニズムなしで、ソースデータの完全なコピーをロードしていく傾向があります。これに対して、通常のデータレイクよりもかなり少ないストレージを使用するという追加的メリットを持つメタデータを、生のソースデータと組み合わせます。

ここに示すモデルに基づくTalendのデータボルトのチュートリアルを、ご確認ください。チュートリアルでは、完全にインサートのみのデータレイクをTalendジョブで処理する方法を説明しています。ソースコードが含まれており、将来のリリースでは上記の新しいSnowflakeコンポーネントを使用したクラウド実装が組み込まれる予定です。
まとめ
データスワンプの状態は回避しなければなりません。最新のクラウドベースのDWaaS(Snowflake)と最先端のデータ統合ツール(Talend)を使用して構築した「管理されたデータレイク」は、最新のエンタープライズデータアーキテクチャーの基盤となります。率直に言って不釣り合いな従来のスタースキーマの代わりに、適応性が非常に高いデータボルトデータのモデリング手法を使用して、迅速、効率的、効果的に構築しましょう。適切に設計/構築/展開されたデータレイクには真の価値を実現する潜在力があり、大きな成功のための機会をもたらします。この点を上司にも伝えてください!
今年5月には、第4回の年次World Wide Data Vault Consortiumが米国バーモント州ストウで開催されます。TalendとSnowflakeはどちらもこのイベントのスポンサーであり、私たちも参加しますので、海上でこの記事の内容について直接お話しできます。参加枠が限られているので、すぐに登録しましょう!
著者紹介:Kent Graziano
Kent Grazianoは、Snowflake Computing社のシニアテクニカルエバンジェリストであり、データモデリング、データアーキテクチャー、およびデータウェアハウジングの分野で受賞歴のある著作を持ち、講演者およびトレーナーとしても活動しています。認定のData Vault MasterおよびData Vault 2.0プラクティショナー(CDVP2)、エキスパートデータモデラー、ソリューションアーキテクトであり、20年にわたってデータウェアハウジングおよびビジネスインテリジェンスに(複数の業界で)携わったを実績を含め、30年以上の経験を有します。Oracle SQL Developer Data Modelerおよびアジャイルデータウェアハウジングの領域で国際的に認められた専門家です。複数のアジャイルDW/BIチームを含む多くのソフトウェア/データウェアハウス実装を開発し、チームを主導して成功を収めてきました。多くの記事と3冊の電子書籍(Amazon.comで入手可能)を執筆し、4冊の書籍を共同執筆するとともに、米国内外で何百ものプレゼンテーションを行ってきました。また、『Super Charge Your Data Warehouse』(DV 1.0の主要技術書)の出版に際しては技術編集者を務めました。Twitterの@KentGraziano、および自身のブログ「The Data Warrior」(http://kentgraziano.com)で情報発信しています。
