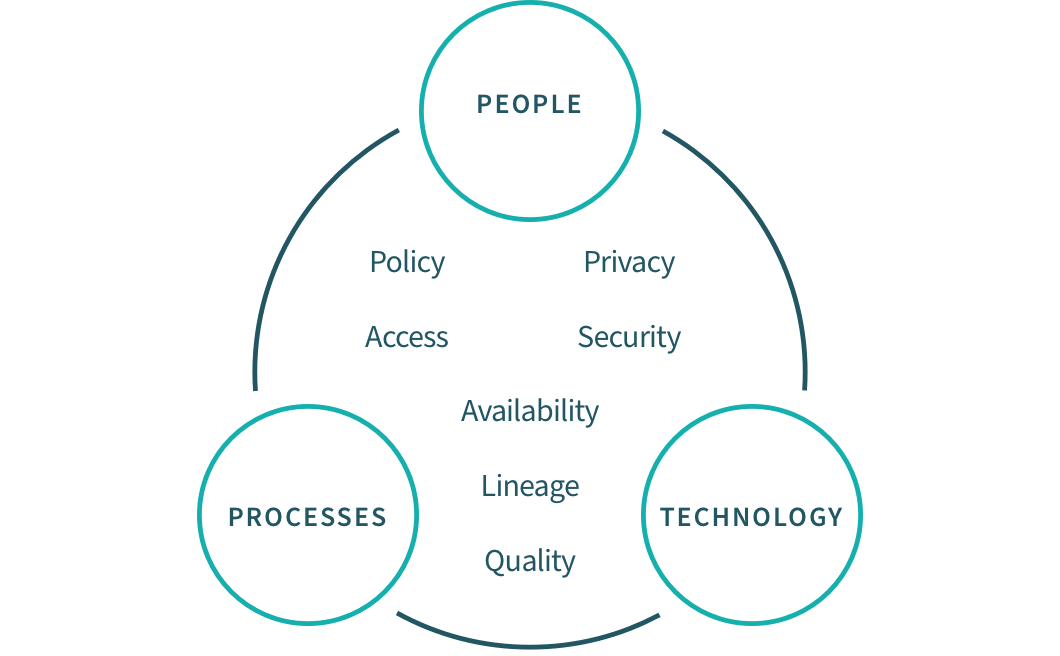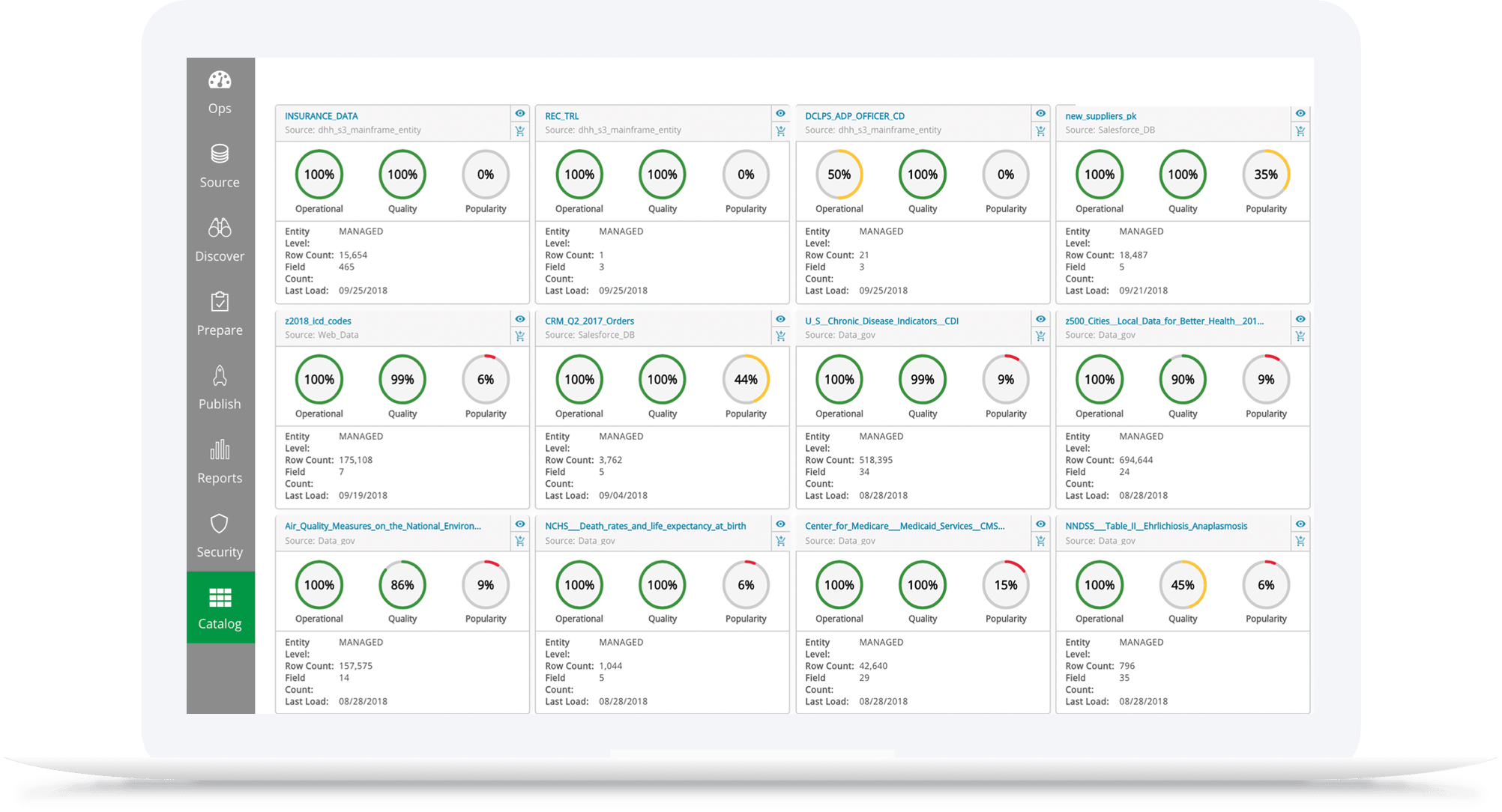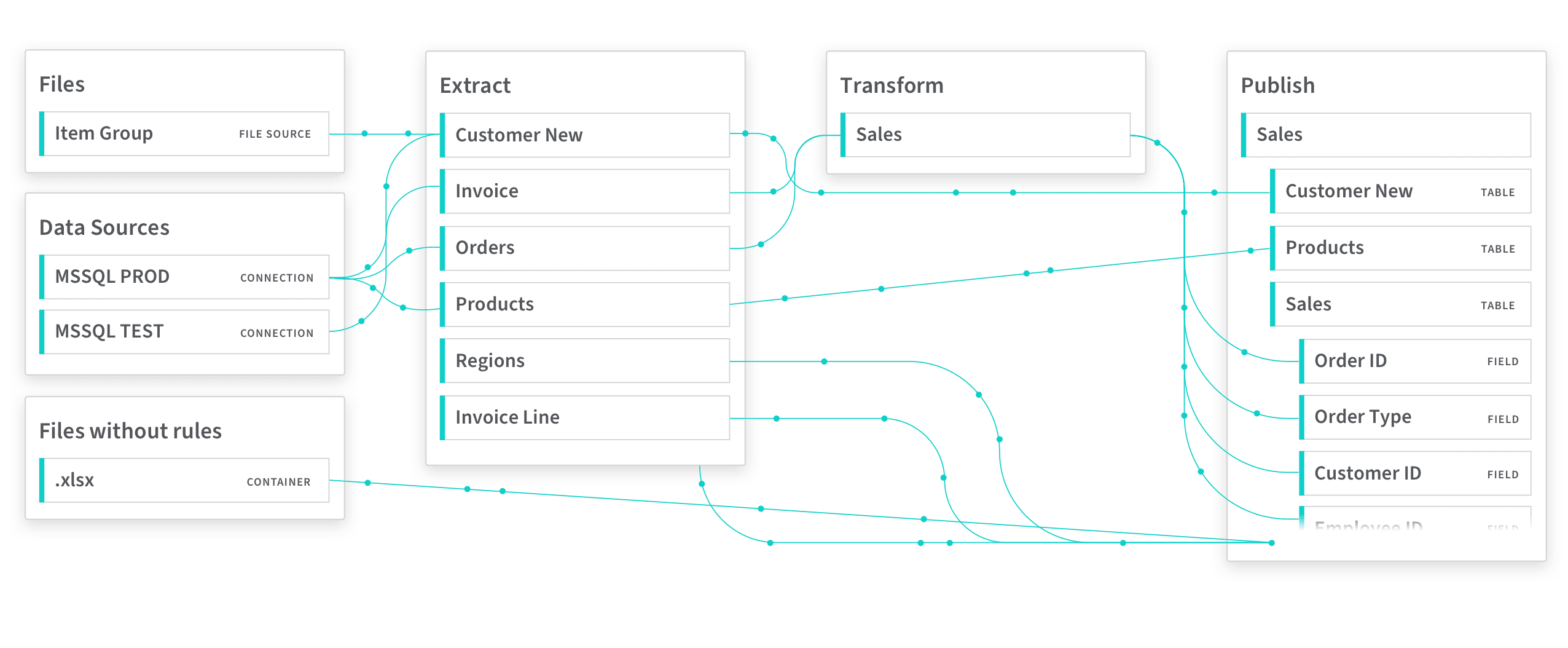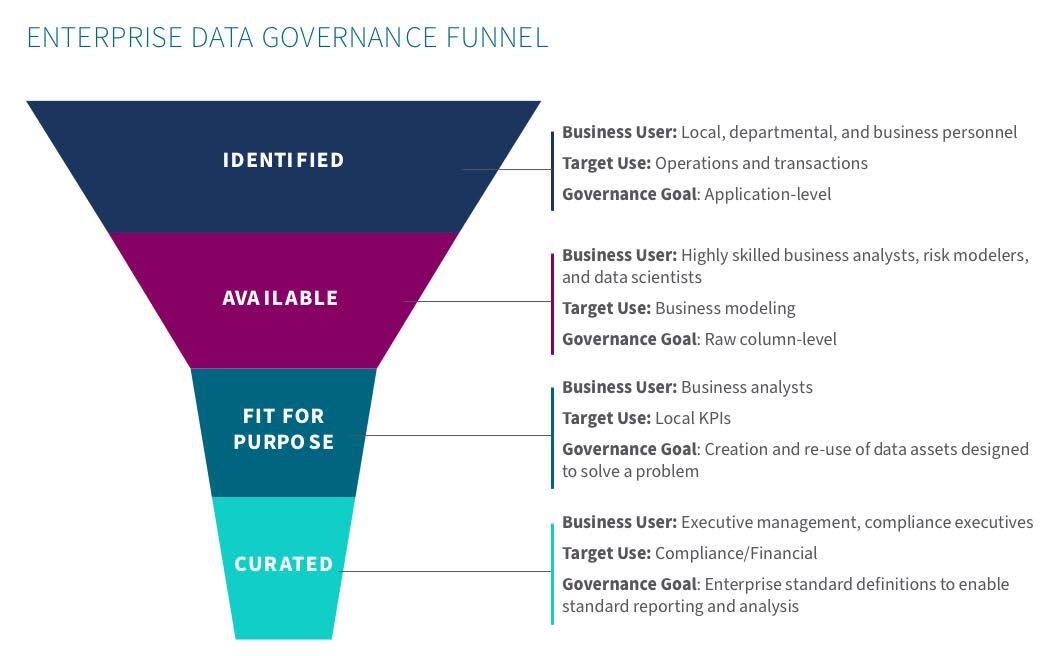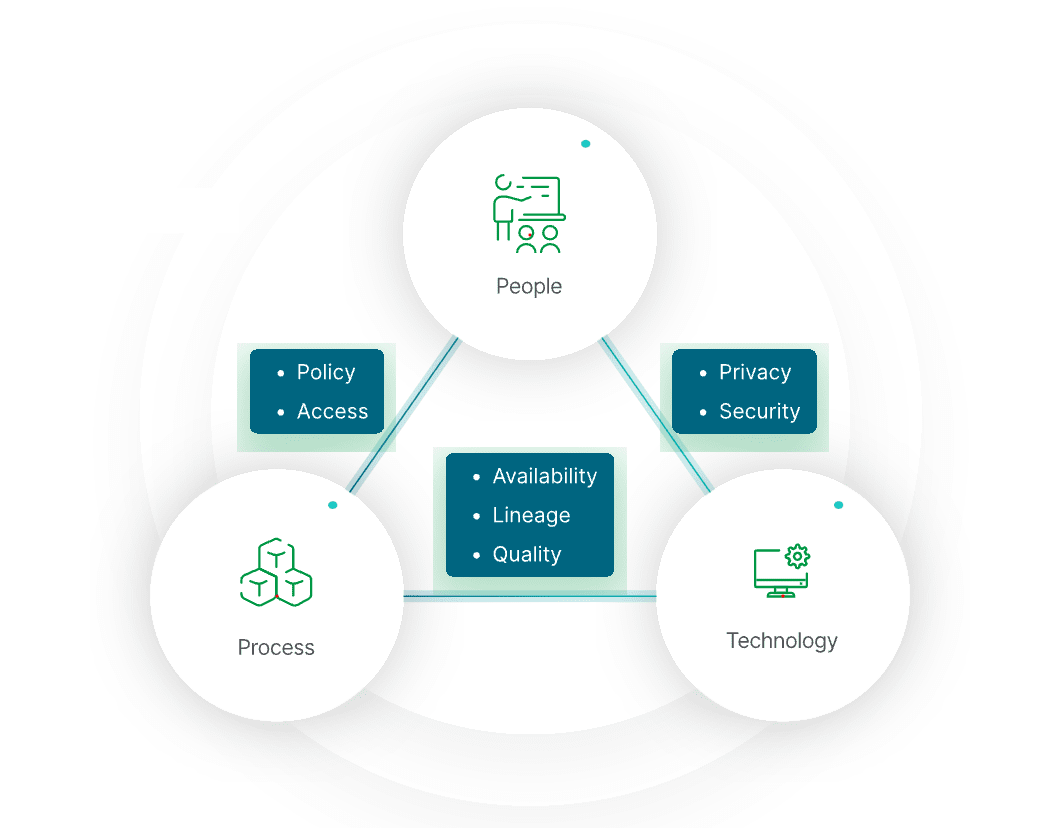
Why is it Important?
The primary benefit of data governance is providing the high-quality data necessary for data analytics and BI tools. The insights gained from these tools result in better business decisions and improved performance. Additional benefits include:
Improved data accuracy, completeness, and consistency
Prevention of data misuse
Agreement on common data definitions
Removal of data silos between departments and systems
Increased trust in data for analytics and decision making
Easier to locate data making all data more available
Better compliance with data privacy laws and other government regulations such as the EU General Data Protection Regulation (GDPR) and the US Health Insurance Portability and Accountability Act (HIPAA)
In addition, one of the top 10 BI and data trends this year is that regulations are now combining data management, security, privacy, and identity and access management. So, security and governance have become a top priority, especially as you share APIs and data with partners.