Déployer un data lake gouverné dans le cloud
Publié par Dale T. Anderson, responsable régional chez Talend, Customer Success Architect et Kent Graziano, évangéliste technique principal chez Snowflake
Vous voulez mettre en place un data lake ? Très bien, parlons-en. Vous pensez peut-être qu'un data lake vous dispensera de créer un data warehouse et que tous vos utilisateurs métiers n'auront qu'à en extraire l'analytique métier. Vous pensez peut-être aussi que tout miser sur des technologies Big Data telles qu'Hadoop résoudra tous vos problèmes de données et permettra un traitement rapide de vos données avec Spark, tout en vous donnant des informations intéressantes sur le machine learning qui, comme par magie, vous permettront d'avoir une longueur d’avance sur la concurrence. Et, de toute façon, avec NoSQL, plus personne n'a besoin d'un modèle de données, pas vrai ?
Dans la réalité, il s'agit surtout d'un engouement médiatique. C'est pourquoi nous avons une question à vous poser : comment expliquerez-vous à votre patron que votre tout nouveau « lac de données » n'est en fait qu’un bourbier, encombré de données provenant de partout et ne vous permettant pas d'en extraire des données pertinentes ? Nous vous suggérons donc d'éviter ce scénario et d'envisager à la place d'utiliser Talend et Snowflake Elastic Data Warehouse pour une meilleure solution.
Avant de commencer à mettre en place votre data lake, corrigeons quelques idées fausses:
- Un data lake est (ou devrait être)
- un emplacement où sont regroupées toutes les données métiers ;
- un dictionnaire (ou glossaire) des données exposées qui régit le linéage et l'historique ;
- une fusion des données sources avec des modèles de métadonnées pertinents ;
- utilisable pour répondre à de nombreux besoins opérationnels et de reporting ;
- évolutif, adaptable et robuste, adapté à presque tous les besoins métiers.
- Un data lake n'est pas (ou doit éviter d'être)
- le « nouveau » data warehouse d'entreprise ;
- nécessairement basé sur Hadoop ou NoSQL ;
- un silo de données comme les autres, avec un accès simple et rapide ;
- en mesure d'éviter l'intégration et le traitement des données ;
- la tendance du moment, l'intérêt qu'il présente peut être bien réel ;
- destiné uniquement à l'« Internet des objets », à l'analytique et à l'intelligence artificielle.
Mais, dans ce cas, pourquoi devriez-vous mettre en place un « data lake » ? Nous pensons que l'objectif principal d'un« data lake » est d'offrir un accès direct et sans restriction à des données organisationnelles brutes (non filtrées) en lieu et place d’un stockage de datasets divergents et parfois limités dans des silos de données épars et disparates. Par exemple, imaginons que vous ayez des données de planification des ressources de l'entreprise (ERP) dans un « data mart » et des blogs sur un serveur de fichiers différent. L'utilisation d'une requête pour leur regroupement implique souvent un modèle de fédération complexe (ainsi que des logiciels complémentaires) : c'est un vrai casse-tête, non ? Dans l'idéal, le data lake vous permettrait de réunir l'ensemble de ces données dans un grand référentiel, les rendant ainsi accessibles à n'importe quelle requête.
Avec un data lake bien conçu et gouverné, vous pourriez en effet regrouper l'ensemble des données qui vous sont importantes pour qu'elles puissent appuyer facilement et en toute transparence tous vos cas d'usage métiers. La capacité à vous occuper de tout, de l'analytique et du reporting traditionnels de l'informatique décisionnelle à l'exploration et la découverte des données, en passant par l'expérimentation de votre équipe de science des données, pourrait vous conférer le statut de héros aux yeux de votre patron.
Très bien, me diriez-vous, que faut-il pour mettre en place un « data lake » performant ? Comme pour la plupart des projets logiciels complexes impliquant d'énormes quantités de données, la première chose à faire est de prendre cette question au sérieux. Et c'est notre cas ! Les avantages qui pourraient découler d'un data lake bien construit sont largement supérieurs au travail de mise en place. Il est donc primordial de définir des attentes réalistes. Des résultats mesurables ne se feront peut-être pas sentir immédiatement. Vous devrez prendre le temps de structurer, de concevoir et de planifier ce travail et le calendrier, et veiller à avoir recours à une approche « agile » : elle peut donner des résultats positifs ! Mais définissez des objectifs à moyen terme et adoptez une cadence que votre équipe peut suivre et à laquelle elle peut s'adapter au fur et à mesure. Vous y parviendrez.
Et, comme pour tout projet logiciel complexe impliquant d'énormes quantités de données, vous devrez bien réfléchir à trois aspects importants :
- LES COLLABORATEURS
- Impliquez « toutes » les parties prenantes métiers, ce sont après tout leurs données !
- Faites participer des experts techniques au besoin, ou jouez ce rôle !
- LES PROCESSUS
- Élaborez des orientations souples et adéquates et suivez-les. N'oubliez pas d'en conserver une trace écrite !
- Érigez la gouvernance des données en règle, qu'elle ne soit pas une considération de dernière minute !
- Intégrez des méthodologies adaptées : SDLC et modélisation des données !
- Ayez recours à de bonnes pratiques. Soyez cohérent !
- LA TECHNOLOGIE
- Optez pour les bons outils, et sachez les utiliser !
Architecture et infrastructure
Il est important d'être conscient de l'atout que représentent les data lakes, tout en définissant des attentes réalistes. Comme avec tout nouveau lexique, il est facile de mal interpréter et/ou de dénaturer ce que sont les data lakes et/ou comment ils doivent être exploités. Les parties prenantes peuvent avoir leur propre idée sur la question (souvent influencée par le discours en vigueur dans le secteur qui peut susciter des attentes irréalistes), ce qui peut se traduire par une combinaison catastrophique de mauvaise communication, de mauvaises technologies et de méthodologies inadaptées. Nous voulons vous éviter cet écueil.
Pour obtenir un « data lake gouverné », vous avez essentiellement besoin d'un processus d'intégration des données rigoureux pour stocker les données, associé à des métadonnées pertinentes contenant un linéage adapté (p. ex., dates de chargement et source) pour récupérer les données. Si votre « lac de données » ne présente pas ces caractéristiques, il est très probable qu'il se transforme en bourbier. Ces principes étant posés, étudions maintenant deux écosystèmes importants :
- « On-premise »
- Cet environnement pourrait comporter des infrastructures RDBMS et/ou de big data
- Généralement autogéré avec un accès contrôlé/sécurisé
- Représente probablement les données SOURCES mais pas uniquement
- Support, limites et retards traditionnels de l'informatique
- Cloud
- Cet environnement pourrait comporter des applications de logiciel en tant que service (SaaS)
- Généralement hébergé avec un accès géré par des rôles/autorisations d'utilisateur
- Le traitement peut se faire en « cloud-to-cloud », « cloud-to-ground » ou « ground-to-cloud » (autrement dit, de cloud à cloud, de cloud à site ou de site à cloud)
- Faible TCO, flexibilité élastique et accessibilité globale
Environnements « on-premise » et cloud
La façon dont vous créez votre architecture et votre infrastructure peut varier en fonction de vos besoins. Les avantages que vous pourrez en retirer sont le reflet direct des choix que vous aurez faits dès le début de votre projet de data lake. Vous pouvez faire coexister ces deux écosystèmes en associant Talend et Snowflake. Jetons un coup d'œil aux possibilités qui s'offrent à vous :
Option 1 — Talend on-premise et Snowflake dans le cloud
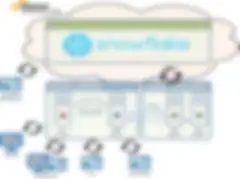
Dans cette première option, Talend est installé et exécuté localement dans votre data center, tandis que Snowflake est exécuté sur une plateforme AWS hébergée. Les serveurs d'exécution exécutent vos jobs Talend qui se connectent alors à Snowflake et traitent les données selon les besoins.
Cette option peut constituer une solution valable si vous préférez utiliser les services Talend dans un large éventail de cas d'usage de données sources/cibles, où tout n'est pas axé sur le « data lake ».
Option 2 — Talend et Snowflake dans le cloud
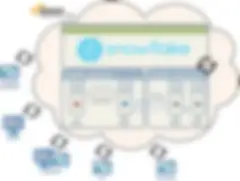
Dans cette seconde option, Talend est installé dans le cloud et éventuellement hébergé sur AWS. Les serveurs d'exécution exécutent vos jobs dans le cloud et utilisent éventuellement certains des nouveaux composants AWS disponibles pour les jobs et qui permettent une utilisation en toute souplesse de la plateforme AWS. Ces jobs peuvent se connecter à Snowflake et/ou à toute autre source/donnée disponible dans l'écosystème cloud. Cette option peut constituer la meilleure solution lorsque les données sont ingérées directement dans votre data lake depuis des fichiers stockés dans le cloud et lorsque les utilisateurs ayant besoin d'accéder à Talend sont répartis dans le monde entier.
Intégration et traitement des données
Vous ne pourrez pas éviter un passage en force lors de l'intégration de vos données dans votre data lake. Leur extraction pourra être encore plus pénible. Il est par conséquent clair que de solides capacités d'intégration et de traitement des données ETL/ELT sont indispensables. Partons du principe que vous savez déjà que la plateforme logicielle Talend offre la toile sur laquelle vous pouvez peindre votre code pour satisfaire à ces exigences. Les capacités de Talend, en tant qu'outil de génération Java, à élaborer des flux de processus robustes et des flux de données efficaces ne sont plus à démontrer. Le logiciel Talend prend en charge l'intégration des projets, le développement collaboratif, l'administration du système, la planification, la surveillance et la journalisation : la liste est longue.
Avec plus de 1 000 composants disponibles dans la version hiver 2017 de Talend (v. 6.3.1), il est désormais beaucoup plus facile de créer une solution qui remplit et manipule votre data lake. D'autres produits proposent des outils de gestion de la qualité, de gouvernance et de préparation des données destinés aux analystes. L'outil Talend Metadata Management encapsule des informations sur vos données dans un glossaire vous permettant de conserver le linéage historique à mesure que les schémas évoluent, et prenant en charge la génération des jobs Talend en fonction des besoins.
Talend a récemment lancé un *NOUVEAU* composant Snowflake que vous pouvez utiliser dans vos jobs. Ce composant ayant été créé à l'aide du nouveau Component Framework (TCOMP), il n'est compatible qu'avec les versions 6.3.1 et supérieures de Talend. Il vous faut donc vérifier que la bonne version est installée avant de commencer à l'installer
« Data warehouse-as-a-service » (DWaaS) dans le cloud
À quoi faisons-nous référence lorsque nous parlons d'un « data warehouse-as-a-service » (ou data warehouse en tant que service) ? Tout d'abord, il est question d'une plateforme RDBMS conçue spécialement pour prendre en charge le type de requêtes associé à un data warehouse (requêtes analytiques, agrégations). Cela étant, il doit prendre en charge des outils basés sur SQL standard comme langage principal. Afin de répondre à tous les besoins en données de votre data lake, il doit également prendre en charge l'ingestion et la possibilité d'interroger des données semi-structurées comme le font les systèmes de « big data ».
En outre, il doit être proposé « en tant que service » dans le cloud. C’est-à-dire que, tout comme un SaaS, aucune infrastructure ne doit être mise en place et la configuration et l'administration sont gérées par le fournisseur. Il doit utiliser un modèle de paiement à l'utilisation (« pay as you go ») souple, ce qui, dans le cas du DWaaS, signifie que vous ne payez pas pour les ressources de calcul et de stockage que vous n'utilisez pas !
Nous pensons que c'est une question dont vous devriez vous soucier car un véritable DWaaS vous sera utile pour offrir à votre entreprise un accès aisé à toutes les données dont elle pourrait avoir besoin (c'est à cela que sert un data lake en définitive, non ?). En effet, pour y parvenir, il s'appuie sur sa capacité à charger rapidement des données structurées et non structurées et un accès aisé à ces données pour résoudre de manière rapide et rentable des problèmes métiers concrets. S'il est structuré de façon à tirer parti de l'élasticité du cloud, il vous permettra de vous adapter à la demande afin de prendre en charge n'importe quel nombre d'utilisateurs simultanés.
Snowflake est le seul data warehouse conçu pour le cloud et proposé exclusivement en tant que service. Snowflake offre les performances, la concurrence et la simplicité nécessaires pour stocker et analyser l'ensemble des données de votre entreprise en un seul et même emplacement. Sa technologie combine la puissance brute du data warehousing, la flexibilité des plateformes de big data et l'élasticité du cloud à un coût très inférieur à celui des solutions traditionnelles.
L'une des caractéristiques qui font de Snowflake une plateforme de data lake idéale est la séparation du stockage et du calcul (aussi appelée architecture de données partagée en multi-clusters). Contrairement aux architectures legacy on-premise actuelles, avec Snowflake, vous pouvez augmenter vos volumes de stockage de façon dynamique, sans tenir compte des nœuds de calcul. De même, lorsque vous avez besoin d'une plus grande puissance de calcul, vous pouvez redimensionner de façon dynamique vos clusters de calcul pour ajouter des ressources sans avoir à acheter d'autres lecteurs de disque. Du fait de la séparation, vous pouvez transmettre des téraoctets, voire des pétaoctets, de données brutes, sans avoir à vous soucier de la taille de votre groupement d'entrepôt.
Grâce à la séparation du calcul et du stockage, vous pouvez configurer plusieurs clusters de calcul indépendants (appelés entrepôts virtuels) qui accéderont au même magasin de données central. Avec un data lake performant de plusieurs téraoctets, laissez la main libre à vos data scientists en leur attribuant un cluster de calcul dédié. Ils pourront l'utiliser pour alimenter le machine learning et/ou les jobs SPARK Talend, sans craindre que cela n'ait des répercussions sur les autres utilisateurs du système. Vous pouvez découvrir ces fonctionnalités ici :
Autre fonctionnalité intéressante de Snowflake : Snowflake conserve automatiquement une trace des changements apportés aux données au fil du temps (comme une dimension à évolution lente de type II) en arrière-plan, sans configuration ni administration. Votre data lake est ainsi variable dans le temps dès le premier jour : vous pouvez interroger n'importe quel objet de données à n'importe quelle date jusqu'à 90 jours en arrière. C'est idéal pour comparer des ensembles de données dynamiques de grande taille.
Avec de tels outils, qui pourrait avoir envie d'effectuer à nouveau un codage manuel ?
SDLC et bonnes pratiques
Nous avons ici une excellente occasion d'approfondir la question. Et nous aimerions le faire. Pourtant, pour l'heure, gardons-nous de céder à cette tentation, car il serait impossible d'expliquer en détail les poins suivants dans notre petit blog :
- Implémentation agile avec Snowflake et Talend
- Techniques de chargement et de récupération d'un data lake avec Spark
- Modèles de machine learning destinés à l'analytique prédictive
Revenez plutôt consulter notre site. Nous publierons d'autres blogs sur ces thèmes dans quelques temps. Nous pensons que ces informations sont dignes d'intérêt si vous souhaitez créer un data lake performant. Dans l'intervalle, vous pourrez trouver intéressante la lecture de la série de 4 articles Modèles de conception de jobs Talend et bonnes pratiques ou des articles Saving Time and Space: Simplifying DevOps with Fast Cloning et Automatic Query Optimization rédigés par Snowflake (en anglais). Quoi qu'il en soit, réfléchissez bien à l'approche à adopter pour votre infrastructure et l'implémentation d'un data lake. Certaines options offertes aujourd'hui n'existaient pas il y a encore quelques années.
Modélisation de data vault
Un thème qu'l est important d'aborder à ce stade, selon nous, est la méthodologie de modélisation des données que vous pourriez employer dans votre data lake. Souvent négligée, voire ignorée, cette considération est essentielle pour garantir votre succès dans la durée. Nous avons tous les deux rédigé des articles sur l'approche de data vault à adopter dans différentes pages de blog : « What is The Data Vault and why do we need it? » vous présente les concepts et l'intérêt de cette solution innovante. Pour plus d'informations, lisez « Data Vault Modeling and Snowflake » ou « List of top Data Vault Resources » (en anglais). Nous espérons que vous les trouverez utiles et instructifs.
L'approche de data vault appliquée à la modélisation des données et à l'informatique décisionnelle offre une méthode très souple, adaptable et éminemment automatisable de création d'un écosystème de données d'entreprise. Le tout dans un cadre très agile. L'un des fondements architecturaux du data vault est l'utilisation d'une zone de simulation intermédiaire destinée aux données sources brutes. Ceci appuie, en partie, le principe du data vault selon lequel des processus de chargement redémarrables permettent d'éviter de retourner aux systèmes sources pour récupérer à nouveau les données. Une récente présentation a fait remarquer que cela ressemblait beaucoup à un data lake. Et bien...
Si nous suivons les recommandations pour les data vaults préconisant de toujours enregistrer la date de chargement et la source de l'enregistrement sur chaque ligne, nous commençons à entrevoir notre concept de « data lake gouverné ». L'étape suivante consiste à en faire une zone intermédiaire permanente et à appliquer des techniques de « capture des données des modifications » au processus de chargement (pour empêcher tout doublon). Nous avons maintenant bel et bien un « data lake gouverné » ! Des données sources brutes, associées à des métadonnées qui présentent l'avantage supplémentaire d'être beaucoup moins gourmandes en espace de stockage qu'un data lake classique (qui tend à charger des copies complètes des données sources au fil du temps, sans mécanisme efficace permettant de repérer ou de récupérer facilement les informations utiles).

Prenez le temps de consulter le tutoriel Talend Data Vault Tutorial qui est basé sur le modèle présenté ici. Ce tutoriel indique comment un data lake EN INSERTION INTÉGRALE SEULE peut être traité à l'aide de jobs Talend. Le code source est inclus et une version future intègrera un déploiement dans le cloud utilisant le NOUVEAU composant Snowflake indiqué plus haut.
Conclusion
Prenez garde à ne pas créer un bourbier pour vos données ! Utilisez un DWaaS cloud moderne (Snowflake) et l'outil de pointe Data Integration (Talend) pour créer un data lake gouverné qui sera le socle de votre architecture de données d'entreprise moderne. Mettez-le en place rapidement et efficacement à l'aide de la méthodologie hautement adaptable de modélisation des données pour data vault, plutôt que des schémas en étoile traditionnels qui essaient de concilier l'inconciliable. Un data lake bien conçu, construit et déployé pourrait présenter un véritable intérêt pour votre entreprise, ouvrant ainsi la voie à un succès sans faille. Dites-le à votre patron !
Si vous souhaitez discuter en personne des idées présentées ici, vous pourrez rencontrer Dale et Kent lors du 4e Annual World Wide Data Vault Consortium à Stowe dans le Vermont au mois de mai. Talend et Snowflake sont tous les deux parrains de cet événement. Inscrivez-vous rapidement car le nombre de places est limité !
À propos des auteurs : Kent Graziano
Kent Graziano est évangéliste technique principal chez Snowflake Computing et un écrivain primé, un orateur et un formateur dans les domaines de la modélisation des données, de l'architecture des données et du data warehousing. C'est un spécialiste Data Vault certifié et un CDVP2 (Certified Data Vault 2.0 Practitioner) certifié, un expert de la modélisation des données et un architecte de solutions avec plus de 30 années d'expérience, dont deux décennies dans les domaines du data warehousing et de la business intelligence (dans plusieurs secteurs). C'est également un expert mondialement reconnu en Oracle SQL Developer Data Modeler et dans le domaine du data warehousing agile. M. Graziano a mis en place et dirigé de nombreuses équipes performantes d'implémentation de logiciels et de data warehouses, y compris plusieurs équipes spécialisées dans les data warehouses agiles/la business intelligence. Il a rédigé de nombreux articles, écrit trois livres Kindle (disponibles sur Amazon.com), co-écrit quatre livres et fait des centaines de présentations, aux États-Unis et à travers le monde. Il a été l'éditeur technique de Super Charge Your Data Warehouse (le principal livre technique pour Data Vault 1.0). Vous pouvez suivre Kent sur Twitter @KentGraziano ou sur son blog : The Data Warrior (http://kentgraziano.com).
