データモデルの設計とベストプラクティス(第1部)
ビジネスアプリケーション、データ統合、マスターデータ管理、データウェアハウジング、ビッグデータデータレイク、機械学習といったものは、いずれもデータモデルが共通の基本的要素となります(または、そうあるべきです)。この点を常に念頭に置きましょう。あるいは、(よく見られることですが)完全に無視することがないように注意してください。
データモデルこそが、Eコマースから、PoS、財務、製品、顧客管理、ビジネスインテリジェンス、IoTまで、Talendの高価値でミッションクリティカルのビジネスソリューションのほとんどすべての支柱です。適切なデータモデルがなければ、ビジネスデータはおそらく失われてしまうでしょう!
Talendのジョブ設計パターンとベストプラクティスについて取り上げたブログシリーズ(第1部、第2部、第3部、第4部)では、32のベストプラクティスを紹介し、Talendでジョブを構築する最善の方法について述べました。その中で予告したデータモデリングについて、以下に述べたいと思います。
データモデルとデータモデリングの方法論は、ずっと以前(コンピューティングが始まった頃)からありました。構造は、データが意味を成すために必要であり、コンピューターが実際に処理するうえでの一手段を提供します。確かに、今日では非構造化データや半構造化データも処理されるようになっています。しかし、それは単に、一層洗練された規範へとデータ処理が進化したことを意味するだけではないでしょうか。したがって、データモデルの意義は現在も変わるものではなく、高度なビジネスアプリケーションを構築するための基盤となっています。Talendのベストプラクティスと同様、データモデルとデータモデリングの手法にも真剣に向き合う必要があります。
ダウンロード >> Talend Open Studio for Data Integration
新たな洞察を得るべく、データモデリングの歴史を振り返ってみましょう。
データモデルの進化


1960年代末、当時IBM社の社員だったエドガー・F・コッドは、クリス・J・デイト(『An Introduction to Database Systems』の著者)と協力し、自身の革新的なデータモデリング理論を確立して、1970年に「A Relational Model of Data for Large Shared Data Banks(大規模共有データバンクのデータ関係モデル)」という論文を発表しました。コッドは、ベンダーが方法論を正しく実装できるよう推進するため、1985に有名な「Twelve Rules of the Relational Model(リレーショナルモデルの12の規則)」を発表しました。これは、実際に
次に登場した画期的なデータモデリング方法論は、1996年にラルフ・キンボール(現在は引退)によって、「The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling(データウェアハウスツールキット:多次元モデリングのための完全ガイド)」(マーギー・ロスとの共著)で提唱されました。広く採用されたキンボールのスタースキーマモデルは、1970年にビル・インモン(2007年にComputerworldがコンピューティング史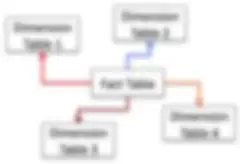

データモデルの概要
これまでに提唱されてきたデータモデリングの方法論は、次のように簡単にまとめることができます。
- フラットモデル — データ要素の単一の2次元配列
- 階層型モデル — フィールドとセットを含むレコードが、親子の階層を定義
- ネットワーク型モデル — 階層型モデルに似ており、分岐の「リンク」テーブルのマッピングを使用して1対多の関連を許可
- リレーショナルモデル — とりうる値と値の組み合わせへの制約を記述する、有限の述語変数を超える述語の集合
- スタースキーマモデル — 正規化されたファクトテーブルとディメンションテーブルが、データ集約のためにカーディナリティ度の低い属性を排除
- データボルトモデル — ハブ、サテライト、リンクテーブルを使用して、複数のデータソースから長期の履歴データを記録
データベース開発ライフサイクル — DDLC
今日の議論は、データの複雑さと非常に大きなボリュームに集中しています。それも確かに重要なことですが、データモデルも重要トピックとして討議すべきであることを改めて強調したいと思います。要件の進化に伴ってスキーマ(データモデル)の進化や主導が求められており、いずれの場合も管理が必要とされます。そこで役立つのがデータベース開発ライフサイクルです。
データが関与するそれぞれの環境(開発/テスト/実稼働のような)向けに、開発者はコードをその必然的構造変化に対応/適応させる必要があります。ソフトウェア開発ライフサイクル(SDLC)と同様、データベースも適切なデータモデル設計とベストプラクティスを取り入れるべきです。私は、これまで多くのデータモデルを設計する中で、以下のような明確な教訓を得ました。
- 適応性 — 機能強化や修正に対応するスキーマを作成すること
- 拡張性 — 予想以上に拡大するスキーマを作成すること
- 基本性 — 特性/機能性を実現するスキーマを作成すること
- 移植性 — 異なるシステムでホスト可能なスキーマを作成すること
- 活用 — ホストテクノロジーを最大限活用するスキーマを作成すること
- 効率的なストレージ — スキーマのディスクフットプリントを最適化すること
- 高いパフォーマンス — 優れたパフォーマンスを提供する最適化されたスキーマを作成すること
設計に関するこれらの教訓は、相反することもあるモデリング方法論のいずれを選択する場合も、それぞれの本質的要素に対応します。私の経験では、これらの違いにかかわらず、データモデルのライフサイクル全体を以下の3段階に分けることができます。
- 新規インストール — スキーマの現行バージョンに基づく
- アップグレードの適用 — データベースオブジェクトをドロップ/作成/変更し、あるバージョンから次のバージョンへとアップグレード
- データ移行 — 中断を伴う「アップグレード」が発生(テーブルやプラットフォームの分割など)
データモデルの設計には、代償を求めない自発性が求められることもあり、細心の注意と同時に曖昧さを抽象化する創造力を伴います。私は個人的に難解なスキーマに惹かれ、修正すべき部分を探しますが、これらの問題は以下のようにさまざまな形で顕在化します。
- χ 複合プライマリーキー:効果的であったり適切であったりすることはほとんどないため、避けましょう。データモデルによっては例外もあります。
- χ 不正なプライマリーキー:通常、日付時刻や文字列(GUIDやハッシュを除く)は不適切です。
- χ 不正な索引化:少なすぎる、または多すぎるのいずれかです。
- χ 列のデータ型:整数のみが必要な場合、特にプライマリーキーでは、長整数(または大整数)を使用しないでください。
- χ ストレージ割り当て:データサイズと成長の可能性を考慮しません。
- χ 循環参照:テーブルAがテーブルBと関係を持ち、テーブルBがテーブルCと関係を持ち、そしてテーブルCがテーブルAと関係を持つ状況であります。これは、単純に設計の問題であると思います。
次に、データベース設計のベストプラクティスとして、データモデルの設計とリリースのプロセスについて検討します。データモデルを作成する際は、次のような規定プロセスに従うべきでしょう。

多くの人にとっては自明のことでしょうが、このプロセスを採用することの重要性を強調しておきます。スキーマの変更は避けられませんが、ソフトウェア開発プロジェクトの早い段階で確実なデータモデルを確立することが肝心です。アプリケーションコードへの影響を最小限に抑えることは、ソフトウェアプロジェクトを成功させるためには間違いなく望ましいことです。スキーマの変更は大きなコストを伴う命題になることもあるため、データベースのライフサイクルとその役割を理解することが非常に重要になります。データベースモデルのバージョン管理は重要です。グラフィカルな図を使用して、設計を説明しましょう。「データ辞書」や「用語集」を作成し、経時的変更についてリネージを追跡します。これはより高次の規律ですが、役立ちます!
データモデリングの方法論
データモデルの進化、そして設計で採用するベストプラクティスを理解することは、ほんの始まりに過ぎません。トランザクション(OLTP)とアナリティクス(OLAP)の両方のモデルでデータベースアーキテクトとして活動した経験から、上記に挙げた最初の3つのステップが作業の約8割を占めることがわかりました。これについて、次に検討しましょう。
データモデルの構築は、簡素または小規模であるために容易なこともあれば、反対に複雑さ、多様性、データの規模や形状、企業内での使用場所などにより非常に困難になることもあります。データの内容と場所、データを使用するアプリケーション/システムとの相互の影響、そもそもデータがそこに存在する理由について、早期に理解するする必要があります。誰が何を必要としているか、それをどのように提供するかを見極めるのは簡単ではありません。堅実なデータモデルであることを確実に明らかにすることが目標となります。最適なデータモデリング方法論の選択は非常に重要です。
データモデルのビジネス価値
TalendのETL/ELTジョブはデータの読み書きのために記述されます。これは、明らかにビジネスに価値をもたらすためです。それでは、なぜデータモデルが必要となり、どのような目的で役立つのでしょうか。また、単純に処理するだけではいけないのでしょうか。技術的観点からは、データモデルはデータフローを操作するための構造を与えます。データモデルのライフサイクルは、ジョブ設計、パフォーマンス、およびスケーラビリティに直接影響します。しかも、厳密に言うと、これは氷山の一角にすぎません。また、ビジネスの観点はさらに抽象的です。何よりも、データモデルはビジネス要件を検証します。システム統合とビジネスで使用されるデータの構造的制御のための重要な定義を提供し、それによって多様な機能上/運用上の原則を保証します。データモデルなしでは、ビジネスの効率性が完全に損なわれると思いますが、皆さんはどのようにお考えでしょうか。
まとめ
データモデルとTalendのようなツールがなければ、データはビジネス価値を提供することに完全に失敗します。場合によっては、不正確さ、誤用、誤解によってビジネスの成功を妨げかねません。私の経験では、明確に定義されたデータモデルとDDLCのベストプラクティスを使用することで、データのビジネス価値が加速・増大します。
本シリーズの第2部では、論理データモデルと物理データモデルの基本と価値について説明します。また、まず全体論的な観点から、次に概念的な詳細を切り離して、データを区別する方法を拡張し、そのうえで論理的設計と物理的設計を検討します。これらは、データの理解を深め、データをモデル化し、データベース設計のモデルを検証するために役立ちます。
ダウンロード >> Talend Open Studio for Data Integration
