Data Model Design and Best Practices: Part 1
Geschäftsanwendungen, Datenintegration, Masterdaten-Management, Data Warehousing, Big Data, Data Lakes und Machine Learning – sie alle haben (oder sollten) einen gemeinsamen und wesentlichen Bestandteil: ein Datenmodell. Diese Tatsache wird oft vergessen oder schlichtweg ignoriert, was ich schon häufiger erlebt habe!
Fast jede kritische Geschäftslösung basiert auf einem Datenmodell – sei es in den Bereichen Onlinehandel und Point-of-Sale, Finanzen, Produkt- und Kundenmanagement, Business Intelligence oder IoT. Das dies so ist, verwundert wenig, denn ohne ein geeignetes Datenmodell haben geschäftliche Daten schlicht keinen Wert!
In meiner erfolgreichen Blog-Reihe zu Talend Job Design Patterns und Best Practices (siehe Teil 1, Teil 2, Teil 3 und Teil 4 ), in denen ich 32 Best Practices und die effizienteste Methode zur Joberstellung in Talend vorstelle, hatte ich schon angedeutet, dass ich als nächstes auf die Datenmodellierung eingehen würde. Und hier sind wir!
Datenmodelle und Verfahren zur Datenmodellierung gibt es seit Anbeginn der Zeit. Ok – sagen wir, zumindest seit Anfang des Computerzeitalters. Daten brauchen eine Struktur, ohne diese ergeben sie keinen Sinn und Computer können sie nicht als Bits und Bytes verarbeiten. Klar, heute haben wir es auch mit unstrukturierten und semistrukturierten Daten zu tun. Für mich aber heißt das nur, dass wir uns mit mehr Komplexität herumschlagen müssen, als sich unsere digitalen Vorfahren vorstellen konnten. Das Datenmodell wird jedenfalls auf absehbare Zeit die Grundlage für Geschäftsanwendungen bleiben. Wie die Talend-Best-Practices müssen wir auch unseren Datenmodelle und Modellierungsmethoden immer ernst nehmen.
Herunterladen >> Talend Open Studio for Data Integration
Ein kurzer Blick zurück in die Geschichte der Datenmodellierung bringt vielleicht ein wenig Licht ins Dunkel. Deshalb habe ich mich selbst noch einmal schlau gemacht.
Eine kurze Geschichte der Datenmodellierung


Ende der 1960er Jahre erstellte der IBM-Mitarbeiter E. F. Codd gemeinsam mit C. J. Date (Autor von An Introduction to Database Systems) wegweisende Theorien zur Datenmodellierung, die 1970 in der Veröffentlichung des Fachartikels A Relational Model of Data for Large Shared Data Banks mündeten. Codd, dem es ungemein wichtig war, dass Hersteller seine Methoden korrekt implementierten, veröffentlichte 1985 mit Twelve Rules of the Relational Model seine berühmteste Arbeit. Eigentlich sind es sogar 13 Regeln, von 
Die nächste bedeutende Datenmodellierungsmethode ließ bis 1996 auf sich warten. Ralph Kimball (heute im Ruhestand) beschrieb sie gemeinsam mit Coautorin Margy Ross in seinem aufsehenerregenden Buch The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling. Das von Kimball propagierte Sternschema-Datenmodell ist heute 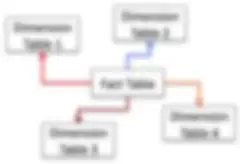

Datenmodelle – eine Übersicht
Es folgt eine Übersicht der verschiedenen Datenmodellierungstechniken in chronologischer Reihenfolge:
- Flaches Datenmodell: Eine zweidimensionale Matrix aus Datenelementen.
- Hierarchisches Modell: Daten werden in einer baumähnlichen Struktur gespeichert. Jeder Eintrag hat eine übergeordnete Einheit oder einen Stamm.
- Netzwerkmodell: Dieses Modell baut auf dem hierarchischen Modell auf. Es erlaubt 1:n-Beziehungen; deren Zuordnung erfolgt über eine Verknüpfungstabelle.
- Relationales Modell: Eine Prädikatsammlung über einen finiten Satz an Prädikatvariablen, für deren möglichen Werte oder Wertkombinationen Beschränkungen gelten.
- Sternschema-Modell: Normalisierte Fakten- und Dimensionstabellen entfernen Attribute mit niedriger Kardinalität für Datenaggregierungen.
- Data-Vault-Modell: Einträge mit langfristig gespeicherten historischen Daten aus verschiedenen Datenquellen, die in Hub-, Satelliten- und Link-Tabellen angeordnet sind und darüber in Beziehung stehen.
Database Development Life Cycle – DDLC
Spricht man heute über Daten, geht es meist um ihre Komplexität und Menge. Beides wichtige Punkte, klar, aber ich bin der Ansicht, dass darüber das Datenmodell nicht vergessen werden darf. Das Schema (also das Datenmodell) muss zur Aufgabe passen oder sogar mehr leisten als gefordert. Auf jeden Fall muss es verwaltet werden, und hier kommt der Database Development Life Cycle ins Spiel!
Entwickler müssen in jeder Umgebung (DEV/TEST/PROD) ihren Code auf die unvermeidliche strukturelle Veränderung der beteiligten Daten vorbereiten. Für Datenbanken gibt es analog zum Software Development Life Cycle (SDLC) Leitlinien zur Datenmodellierung und Best Practices. Ich selbst habe schon viele Datenmodelle entworfen und für mich daraus einige klare Regeln abgeleitet:
- Anpassbarkeit: Ein Schema sollte Verbesserungen und Korrekturen standhalten.
- Erweiterbarkeit: Ein Schema sollte nicht auf die momentan geforderten Aufgaben beschränkt sein.
- Fundamentalität: Ein Schema muss die geforderten Merkmale und Funktionen bereitstellen.
- Portierbarkeit: Es sollte möglich sein, ein Schema auf verschiedenen Systemen zu hosten.
- Ausnutzung: Ein Schema sollte die Hosttechnologie vollständig ausnutzen.
- Speichereffizienz: Das Schema sollte so gestaltet sein, dass es wenig Speicherplatz belegt.
- Hohe Leistung: Ein Schema sollte leistungsoptimiert sein.
Diese Designregeln spiegeln die Grundprinzipien jeder Modellierungstechnik wider, auch wenn einige davon in Widerspruch zueinander stehen. Ungeachtet dieses Widerspruchs hat ein Datenmodell meiner Erfahrung nach nur drei Lebensphasen:
- Neuinstallation: Basierend auf der aktuellen Version des Schemas
- Upgrade: Entfernen/Erstellen/Ändern von Datenbankobjekten durch ein Versionsupgrade
- Datenmigration: Durch ein radikales „Upgrade“ (Teilen von Tabellen oder Plattformwechsel)
Der Entwurf eines Datenmodells ist eine hochkomplexe Angelegenheit, die einen genauen Blick fürs Detail und die Fähigkeit zur Abstraktion von Mehrdeutigkeiten voraussetzt. Ich liebe diffizile Aufgaben und fuchse mich gerne in komplexe Probleme hinein, die sich mir auf die verschiedensten Arten offenbaren. Hier einige Tipps:
- χ Zusammengesetzte Primärschlüssel – generell vermeiden, nur selten effektiv oder geeignet; nur wenige Ausnahmen je nach Datenmodell
- χ Ungeeignete Primärschlüssel – Datum/Uhrzeit oder Zeichenfolgen (außer eine GUID oder ein Hash) sind in der Regel ungeeignet
- χ Schlechte Indizierung – entweder zu viel oder zu wenig
- χ Spalten-Datentypen – kein Long (oder Big Integer) verwenden, wenn lediglich ein Integer benötigt wird, vor allem nicht als Primärschlüssel
- χ Speicherzuteilung – Falscheinschätzung der Datengröße oder des Wachstumspotenzials
- χ Zirkelbezüge – wenn Tabelle A in Beziehung zu Tabelle B steht, Tabelle B in Beziehung zu Tabelle C und Tabelle C wieder zu Tabelle A, dann ist das einfach nur schlechtes Design (IMHO)
Sprechen wir nun über Best Practices beim Datenbankdesign, konkret über den Design- und Release-Prozess für ein Datenmodell. Hierfür empfehle ich eine feste Abfolge wie nachfolgend beschrieben:

Auch wenn sie wahrscheinlich selbsterklärend ist, möchte ich doch betonen, wie wichtig es ist, diese Abfolge einzuhalten. Schemaänderungen lassen sich nicht vermeiden, weshalb schon frühzeitig in der Entwicklung der Software ein robustes Datenmodell vorliegen muss. Nicht minder wichtig ist es, die Auswirkungen auf den Anwendungscode so gering wie möglich zu halten. Schemaänderungen können teure Anpassungen nach sich ziehen, weshalb sie den Datenbanklebenszyklus und seine Rolle genau kennen müssen. Nutzen Sie die Versionierung für Ihr Datenbankmodell. Veranschaulichen Sie das Design mit Diagrammen. Erstellen Sie ein Datenwörterbuch oder ein Glossar und protokollieren Sie alle Änderungen. Das alles erfordert Disziplin, aber es funktioniert!
Datenmodellierungstechniken
Sie kennen jetzt die Geschichte der Datenmodellierung und die beste Methode, ein Datenmodell zu erstellen. Das ist aber erst der Anfang. Als Datenbankarchitekt von transaktionalen (OLTP) und analytischen (OLAP) Modellen habe ich die Erfahrung gemacht, dass die ersten drei oben genannten Schritte 80 % der Arbeit ausmachen. Darauf komme ich jetzt zu sprechen.
Manchmal ist das Datenmodell das kleinste Problem, zum Beispiel wenn es einfach aufgebaut und überschaubar ist. Datenmodelle können aber auch unglaublich aufwendig sein, zum Beispiel aufgrund der Komplexität, Diversität, Größe und Form der Daten oder wenn sie an vielen Stellen im Unternehmen genutzt werden. Es sollte daher so früh wie möglich bekannt sein, um welche Art von Daten es sich handelt, wo sie sich befinden und in welcher Wechselwirkung sie zu den Anwendungen und Systemen stehen, von denen sie genutzt werden. Es schadet auch nicht zu wissen, warum es die Daten überhaupt gibt. Zu wissen, wer die Daten in welcher Form braucht, ist schon die halbe Miete. Dann können Sie auch ein solides Datenmodell erstellen. Höchstes Gebot ist aber die Auswahl der passenden Datenmodellierungstechnik.
Geschäftlicher Nutzen eines Datenmodells
Talend ETL/ELT-Jobs lesen und schreiben Daten, vornehmlich, um einem Unternehmen irgendeine Form von geschäftlichen Nutzen zu bieten. Wozu dient das Datenmodell? Welchen Zweck hat es? Könnten wir die Daten nicht einfach verarbeiten und fertig? Das Datenmodell gibt den Daten eine Struktur, die wir brauchen, um den Datenfluss zu steuern. Der Lebenszyklus eines Datenmodells hat direkte Auswirkung auf Jobdesign, Performance und Skalierbarkeit. Das ist technisch gesehen aber nur die Spitze des Eisbergs. Aus geschäftlicher Perspektive sieht das ganze ein wenig abstrakter aus. Das Datenmodell validiert die geschäftlichen Anforderungen. Es liefert die Definition für die Systemintegration und die strukturelle Steuerung der Daten, die das Unternehmen benötigt, um verschiedene Funktionen oder Aufgaben wahrzunehmen bzw. durchzuführen. Ohne Datenmodell wäre das Unternehmen also vollständig handlungsunfähig. Stimmen Sie mir zu?
Fazit
Ohne ein Datenmodell und Tools wie Talend lässt sich aus Daten nur selten ein geschäftlicher Nutzen erzielen. Im Gegenteil: durch Ungenauigkeiten, Missbrauch oder Missverständnisse kann sich sogar ein negativer Effekt ergeben. In meiner Praxis habe ich gelernt, dass ein gut definiertes Datenmodell und ein DDLC den geschäftlichen Wert von Daten steigert und die Wertschöpfung beschleunigt.
Im zweiten Teil dieser Reihe gehe ich auf die Grundlagen und Vorteile des logischen und physischen Datenmodells ein. Außerdem werde ich über die Datendifferenzierung sprechen, erst allgemein, dann detailliert über verschiedene Konzepte, bevor wir uns überhaupt an ein logisches oder physisches Modell wagen. Das hilft uns, die Daten besser zu verstehen, die Daten zu modellieren und das Modell unserer Datenbankdesigns zu überprüfen.
Herunterladen >> Talend Open Studio for Data Integration
