Datenmodellierung und Best Practices: Teil 2
Was ist ein Datenmodell? Als Entwickler bei Talend haben wir täglich mit Datenmodellen zu tun und denken daher zu wissen, was sich hinter dem Begriff verbirgt:
- Eine strukturelle Definition der Daten in einer Unternehmenslösung
- Eine grafische Darstellung von Geschäftsdaten
- Eine Datengrundlage für die Entwicklung von Unternehmenslösungen
Diese Aussagen mögen zwar alle korrekt sein, doch meiner Meinung nach ist jede dieser Definitionen irrelevant und belanglos, da sie für sich genommen nicht den Kern bzw. den Zweck eines Datenmodells erfassen.
Was IST denn dann ein Datenmodell? Ich würde behaupten, dass es vieles sein kann und doch etwas sehr spezifisches ist. Für mich ist ein Datenmodell die strukturelle Grundlage eines Unternehmens-Informationssystems in der Form einer klar definierten grafischen Darstellung. Ist das nicht dasselbe wie oben? Nein, eigentlich nicht. Diese Definition vereint alle oben genannten Elemente und macht aus einem Dantemodell ein Hilfsmittel, um strukturelle Informationen zu einem Business Use Case – nicht bloß zu den enthaltenen Daten – zu ermitteln.
Im ersten Teil dieser Blog-Reihe habe ich 50 Jahre der Datenmodellierung in etwa vier kurzen Absätzen zusammengefasst. Auch wenn ich dabei sicher ein paar Informationen ausgelassen habe, bin ich davon überzeugt, dass wir uns bewusst machen sollten, dass unser heutiges Wissen zum Thema Datenmodellierung auf die Erkenntnisse und Verbesserungen unserer Vorgänger zurückzuführen ist. Heutige Unternehmen nutzen Datenmodelle in der Regel zur Validierung von Anforderungen, was einen echten Nutzen für das Unternehmen darstellt. Doch ich frage mich, ob sie die Modelle richtig einsetzen. Oft wird durch das bloße Vorhandensein eines Datenmodells davon ausgegangen, dass es sich um ein robustes Modell handelt – ohne es genau zu wissen oder diese Annahme zu bestätigen.
Als Fachmann für Datenarchitektur und Datenbankdesign habe ich schon viele schlechte Datenmodelle gesehen. Ich würde fast behaupten, dass die meisten Modelle in irgendeiner Hinsicht unzureichend sind. Ich habe auch viele gute Modelle gesehen. Doch woran erkennt man eigentlich, ob ein Datenmodell gut oder schlecht ist? Warum sollten wir uns damit überhaupt befassen? Reicht es nicht, wenn wir Daten einpflegen können und Ergebnisse erhalten? Die Antwort ist ein klares NEIN. Datenmodelle müssen gut bzw. hervorragend funktionieren, um den Erfolg der Unternehmenslösungen sicherzustellen, die mit einem Datenmodell abgeglichen oder ausgeführt werden. Das Datenmodell spiegelt die Essenz des Unternehmens und sollte deshalb umfangreich, absolut zuverlässig und ausfallsicher sein.
Ein gutes Datenmodell hat offensichtliche Vorteile. Das wird (für die meisten von uns) noch deutlicher, wenn man beginnt, Daten mit ETL/ELT-Tools wie Talend Studio einzupflegen und auszugeben. Jedes Softwareprojekt besteht aus drei unerlässlichen technischen Elementen – eins davon ist das Datenmodell. Die anderen beiden sind der Anwendungscode und die Benutzeroberfläche.
In Teil 1 haben wir auch über die DDLC-Methodik (Database Development Life Cycle) gesprochen, die ich bei jedem von mir entwickelten Datenmodell einsetze. Ich habe mit dieser Methodik bisher sehr gute Erfahrungen gemacht und kann sie für die professionelle Datenbankentwicklung wärmstens empfehlen. Wenn Sie das Verfahren verstanden haben und anwenden, können Sie jede Implementierung und Wartung eines Datenmodells vereinfachen, automatisieren und verbessern. Allerdings gibt es noch einige Aspekte dieses Verfahrens, auf die wir eingehen sollten. Deshalb möchte ich Ihnen ein paar zusätzliche Best Practices vorstellen, die bei der Entwicklung eines zuverlässigen, flexiblen und präzisen Datenmodells für Ihr Unternehmen von Vorteil sein können.
Best Practices bei der Datenmodellierung
Bei der Erstellung von Datenmodellen nutzen Entwickler häufig ein Verfahren, bei dem ein logisches und ein physisches Modell erstellt wird. Normalerweise beschreiben logische Modelle Entitäten und Attribute und die wechselseitigen Beziehungen. Dabei wird eine übersichtliche Abbildung des geschäftlichen Zwecks der Daten bereitgestellt. Die logischen Modelle werden dann in physischen Modellen implementiert, als Tabellen, Spalten, Datentypen und Indexe mit präzisen Regeln in Bezug auf die Datenintegrität. In diesen Regeln werden Primär- und Fremdschlüssel sowie Standardwerte festgelegt. Zusätzlich können Ansichten, Trigger und gespeicherte Vorgänge definiert werden, die die Implementierung nach Bedarf unterstützen. Im physischen Modell wird außerdem die Speicherzuweisung auf dem Datenträger bestimmt. Diese basiert auf den spezifischen Konfigurationsoptionen, die die meisten Hostsysteme bieten (Oracle, MS SQL Server, MySQL usw.).
So weit, so gut – sollte man meinen. Ich durfte jedoch schon viele intensive Diskussionen über den Unterschied zwischen einem logischen Modell und einem semantischen Datenmodell führen. Oft wollte man mir dabei weismachen, dass es sich um ein und dasselbe Modell handelt und das in beiden Fällen Entitäten und Attribute der Unternehmensdaten abgebildet werden. Da bin ich anderer Meinung. Das Ziel des semantischen Datenmodells besteht darin, einen Kontext für das geschäftliche – nicht das technische – Verständnis der Daten bereitzustellen. Alle Beteiligten können ein semantisches Modell verstehen, aber viele haben Probleme mit Entitäten und Attributen. Meiner Meinung nach ist das semantische Modell, wenn es richtig umgesetzt wird, für alle Beteiligten das BESTE Tool, um sich über die Unternehmensdaten zu verständigen. Ich selbst ziehe es vor, Aspekte der Modellierungssprache Unified Modeling Language (UML) zu verwenden, um ein einfaches, semantisches Datenmodell zu schematisieren und nicht zu sehr ins Detail gehen zu müssen. Das hebe ich mir für das logische und das physische Modell auf, in denen Details unerlässlich und besser ausgearbeitet sind.
Die meisten Unternehmen nutzen in der Regel viele verschiedene Anwendungssysteme, was die Modellierung von Daten zusätzlich erschwert. Meiner Erfahrung nach reichen hier selbst die semantischen, logischen und physischen Modelle nicht aus. An dieser Stelle kommt das ganzheitliche Datenmodell ins Spiel – zumindest meine angepasste Variante.
Der Zweck des ganzheitlichen Datenmodells besteht darin, Datensilos in einem Unternehmen zu ermitteln und zu abstrahieren, um auf oberster Ebene zu beschreiben, welche Daten vorhanden sind oder benötigt werden, inwiefern sie miteinander zusammenhängen und wie sie am effektivsten organisiert werden können.
Die 4 Schichten der Datenmodellierung
Da in einem Unternehmen vier verschiedene Arten von Datenmodellen eingesetzt werden können, schlage ich vor, den folgenden Modellierungsprozess in Schichten (Layers) von oben nach unten zu befolgen – zur Definition, zum besseren Verständnis und für spezifische Designmerkmale. Anhand wichtiger Rollen wird angegeben, wer an welchem Punkt im Prozess involviert ist.
Ganzheitliches Datenmodell:
Die ganzheitliche Schicht (Holistic Layer) stellt eine abstrakte Landschaft von Datensilos in einem Unternehmen dar. Mit diesem Datenmodell lässt sich eine weitreichende Unternehmensdaten-Governance etablieren und so ein besseres Verständnis aller Datenbeziehungen im Unternehmen erzielen. Diese sollte sich auf alle Daten beziehen, intern wie extern und egal aus welcher Anwendung. Zur schematischen Darstellung des ganzheitlichen Datenmodells verwende ich ein Blasendiagramm. Dabei gehe ich folgendermaßen vor:
Blasendiagramme – Datensilos

Manchmal wird eine Blase von einer größeren Blase umgeben. Diese größeren Blasen weisen darauf hin, dass eine Ontologie vorhanden ist (oder sein sollte), die eine Taxonomie für das entsprechende Datensilo vorgibt. Ontologien und ihre Taxonomie-Metadaten liefern aussagekräftige Zuordnungen für das Silo, das sie umgeben. Das ist sehr nützlich, um Daten durchsuchbar zu machen, und sollte in dieser Schicht gekennzeichnet werden.
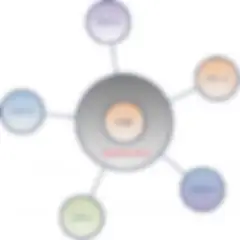
Im Folgenden sehen Sie ein Beispiel für ein vollständig definiertes ganzheitliches Datenmodell. Ich empfehle Ihnen, die Grafik in einem großen Format auszudrucken und an die Wand zu hängen. Sie kann für viele produktive Diskussionen herangezogen werden und eine wirkungsvolle, wertvolle Ressource für Ihr Unternehmen darstellen.
Semantisches Datenmodell:

UML-Informationsarchitektur
Jedes Objekt steht für einen bestimmten Teil eines Datensilos. Linien (auch Verknüpfungen genannt) legen die Beziehungen zwischen zwei Elementen fest (nur zwei, wie oben). Spezielle Elementmerkmale (sogenannte Eigenschaften) werden definiert, um den Zweck eines Objekts zu verdeutlichen. Dafür gibt es folgende Optionen:
- Geschützt (Werte sind vorbestimmt)
- Öffentlich (Werte sind veränderbar)
- Privat (Wertezugriff ist eingeschränkt)
Direkt miteinander verbundene Objekte weisen auf eine Art von Assoziation hin, die mit einer durchgezogenen GRAUEN Verknüpfung und einer entsprechenden Bezeichungen angezeigt wird. Diese Asoziationen (mit oder ohne Rautensymbol am übergeordneten Element) können verschiedene Beziehungen darstellen:
- Einfache Beziehung (keine Raute)
- Aggregation (nicht ausgefüllte Raute)
- Komposition (ausgefüllte Raute)
Ein untergeordnetes Element kann auch navigierbar sein. Dies wird durch ein Pfeilsymbol mit einer relationalen Kardinalität gekennzeichnet (0.* = 0:N usw.).
Objekte können auch Generalisierungen aufweisen. Das bedeutet, dass die Instanz eines Objekts über bestimmte oder eindeutige Eigenschaften bzw. Beziehungen verfügt. In dieser Darstellung verhält sich das Objekt mehr wie eine Unterklasse eines übergeordneten Elements mit all dessen Eigenschaften UND allen zusätzlichen eindeutigen Eigenschaften. Das Element der Unterklasse stellt durch seinen Namen und seine Abbildung eine nachvollziehbare Präzisierung für das abstrahierte ganzheitliche Datensilo bereit. Mit Objekten verbundene Generalisierungen werden durch durchgezogene BLAUE Verknüpfungen mit einem geschlossenen Pfeil am übergeordneten Objekt dargestellt. Ein Label ist nicht erforderlich.
Verbindungen zwischen Unterklassen sorgen für eine genauere Beschreibung von Beziehungen, die das Verständnis des abgebildeten semantischen Datenmodells erleichtern. Generalisierte Unterklassen, die mit anderen generalisierten Unterklassen desselben übergeordneten Objekts verbunden sind, werden als „assoziiert“ betrachtet und mit durchgezogenen GRÜNEN Verknüpfungen und entsprechenden Labels dargestellt. Diese Beziehungen können optional navigierbar sein, was durch ein offenes Pfeilsymbol angezeigt wird, das zusätzlich mit einer relationalen Kardinalität gekennzeichnet ist (0.* = 0:N usw.).
Vervollständigt wird das UML-Diagramm durch sogenannte reflexive Assoziationen zwischen Elementen. Dies sind spezifische Eigenschaften, die die Definition eines übergeordneten Objekts bzw. Assoziationen zwischen spezifischen Eigenschaften erweitern. Spezifische Erweiterungen stellen keine Klasse oder Generalisierung dar, sondern dienen der Kennzeichnung relevanter Eigenschaften, die für ein besseres Verständnis des abstrahierten Datensilos hervorgehoben werden. Die Verbindung von spezifischen Eigenschaften mit einem Element wird durch eine durchgezogene ROTE Verknüpfung und einem entsprechenden Label angezeigt. Elementeigenschaften können außerdem mit anderen Elementeigenschaften desselben übergeordneten Objekts verbunden sein. Dies wird mit durchgezogenen GRÜNEN Verknüpfungen dargestellt, ähnlich wie bei zusammenhängenden Generalisierungen. Auch diese Beziehungen können navigierbar sein, worauf ein optionaler offener Pfeil mit einer relationalen Kardinalität hinweist (0.* = 0:N usw.).
Im semantischen Datenmodell werden bestimmte Datenelemente mithilfe einer klassenbasierten Metapher beschrieben. Dies lässt sich am besten mit der Modellierungssprache UML abbilden, die eine genauere Erklärung abstrahierter ganzheitlicher Datensilos bietet. Das Ziel besteht darin, Geschäftsinformationen zu bestimmen, zu verfeinern und zu steuern – immer noch unabhängig von Anwendungen, Implementierungsregeln oder technischen Aspekten – und Details zu erfassen, die im ganzheitlichen Modell ausgelassen wurden.
Auch bei diesem Modell lohnt sich ein großformatiger Ausdruck. Beachten Sie außerdem, dass es eine gemeinsame Schnittstelle darstellt, für die unabhängig vom folgenden logischen und physischen Datenmodell Anwendungscode geschrieben werden kann. Dieser Vorteil kann auch als Prüfpunkt vor dem Erstellen der nachfolgenden Datenmodelle genutzt werden. Die Prüfung des UML-Modells unter Einbeziehung der Softwareentwickler und Stakeholder ist ein wichtiger Meilenstein im Datenmodellierungsprozess. Nachfolgend ist ein Ausschnitt eines semantischen Datenmodells beispielhaft dargestellt.
Dieses Modell enthält Unterelemente (SubElements), die bestimmte Aspekte des Hauptelements (MainElement) definieren, um eindeutige und wiederkehrende Eigenschaften zu erläutern.
Logisches Datenmodell:
Die logische Schicht (Logical Layer) stellt eine abstrakte Struktur semantischer Informationen dar, die nach Domain-Entitäten (logischen Datenobjekten), ihren Attributen und ihren spezifischen Beziehungen organisiert sind. Dieses Datenmodell wird von Objekten des semantischen Datenmodells abgeleitet und definiert relevante Details (Schlüssel/Attribute) und Beziehungen zwischen Entitäten, ohne Berücksichtigung einer spezifischen Hostspeichertechnologie. Entitäten können je nach Bedarf einzelne Elemente, Teile eines Elements oder mehrere Elemente abbilden, um geeignete Datenstrukturen zu beschreiben. Im logischen Datenmodell werden die strukturellen Entitäten und Datensätze zusammengefasst, die im semantischen Modell identifiziert wurden. Zusätzliche spezifische Attribute erleichtern das Verständnis der involvierten Daten. Ich gehe folgendermaßen vor:
ERD
Entity-Relationship-Diagramme (ERD) beschreiben eindeutig identifizierbare Entitäten, die unabhängig voneinander existieren können und deshalb eine sehr geringe Anzahl an eindeutigen identifizierenden Attributen erfordern, als Primärschlüssel (PK, Primary Key) bezeichnet. Wenn eine untergeordnete Entität mit einer übergeordneten Entität verknüpft ist, kann und sollte die referentielle Datenintegrität mithilfe eines identifizierenden Attributs in der untergeordneten Entität durchgesetzt werden, das dem Primärschlüssel der übergeordneten Entität entspricht. Diese Attribute werden als Fremdschlüssel (FK, Foreign Key) bezeichnet. Dieser Begriff ist Ihnen wahrscheinlich schon bekannt.
Bei Bedarf können Entitäten verknüpft werden, um auf die Art einer Datensatzgruppe oder die Kardinalitätsbeziehung zwischen zwei oder mehr Entitäten hinzuweisen. Für Entitäten mit Verknüpfungen kann die Martin-Notation eingesetzt werden, eine gängige Methode beim Erstellen von Entity-Relationship-Diagrammen (ERD). Die entsprechende Martin-Notation, dargestellt durch durchgezogene BLAUE Verknüpfungen, sollte an beiden Enden ein entsprechendes Label zur Beschreibung der dargestellten Datensätze enthalten. Diese Entitätsverknüpfungen weisen eine spezifische Kardinalität auf, die die zulässige Anzahl von Datensätzen in einer Datensatzgruppe angeben. In diesen Notationen werden null, eine, oder beliebig viele Zeilen oder eine verbindliche Kombination dieser Werte angegeben.
Bei der Kardinalität gelten lediglich zwei Regeln: die minimale und maximale Anzahl der Zeilen jeder Entität, die an einer Beziehung beteiligt sein können, wobei die Notation, die der Entität am nächsten ist, die maximale Anzahl darstellt. Die Angabe der Kardinalität für eine Datensatzgruppe setzt außerdem voraus, dass die Beziehung optional oder obligatorisch ist, was die Entwicklung des physischen Datenmodells erleichtert.
Ein ERD kann Verknüpfungen zu mehreren Entitäten unterstützen, einschließlich reflexiven Verknüpfungen. Entitäten sollten nicht mit Tabellen verwechselt werden, können jedoch häufig direkt auf Tabellen in einem physischen Datenmodell verweisen (siehe unten). Logische Entitäten sind vielmehr strukturelle Abstraktionen, die sich auf vereinfachte Darstellungen aus dem semantischen Datenmodell konzentrieren.
Das logische Datenmodell präsentiert die inhaltliche Abstraktion des semantischen Datenmodells und stellt Details bereit, auf deren Basis ein physisches Datenmodell entwickelt werden kann. Dank dieses Vorteils können Entwickler von Anwendungsdiensten und Datenbankentwickler grundlegende Erkenntnisse sowohl zur abstrahierten Datenstruktur als auch zu den Anforderungen für Datentransaktionen gewinnen. Nachfolgend ist ein Ausschnitt eines logischen Datenmodells beispielhaft dargestellt.
Ein paar Anmerkungen: Ich habe verschiedene Farben verwendet, um verschiedene funktionale Bereiche zu markieren, die dem semantischen und dem ganzheitlichen Modell zugeordnet werden können. Außerdem habe ich eine „virtuelle“ Beziehung zwischen ENTITY_D und ENTITY_C eingebaut (dargestellt als HELLGRAUE Verknüpfung), die auf eine logische Beziehung hindeutet. Das Konstrukt zwischen diesen beiden Entitäten plus ENTITY_B stellt jedoch einen Zirkelbezug dar, der im physischen Modell gänzlich vermieden werden sollte. Beachten Sie zudem, dass ein paar Attribute vorliegen, die ein Array aus Werten definieren. Im logischen Modell ist diese Angabe zulässig, da sie das Modell vereinfacht und optimiert. Im physischen Modell müssen diese Werte jedoch normalisiert werden.
Physisches Datenmodell:
Die physische Schicht (Physical Layer) ist eine Komposition von Artefakten des Hostsystems (physische Datenobjekte), die aus einem logischen Datenmodell abgerufen wurden, kombiniert mit der gewünschten Speicherkonfiguration. Dieses Datenmodell umfasst Tabellen, Spalten, Datentypen, Schlüssel, Einschränkungen, Berechtigungen, Indexe, Ansichten und Details zu den Verteilungsparametern, die im Datenspeicher verfügbar sind (weitere Informationen zu Datenspeichern finden Sie in meinem Blog-Eintrag Beyond the Data Vault („Jenseits des Data-Vault-Modells“). Die Hostartefakte stellen das eigentliche Datenmodell dar, auf dessen Grundlage Softwareanwendungen entwickelt werden. Das physische Datenmodell führt alle diese Artefakte aus Entitäten und Attributen zusammen, die im logischen Modell definiert wurden. Hier erhalten Anwendungen endlich den Zugriff, um tatsächliche Daten zu speichern und abzurufen. Meine Vorgehensweise sieht folgendermaßen aus:
SDM
Ein (physisches) Schemadesign-Modell (SDM) definiert spezifische Objekte in einem Datenbank-Informationssystem. Ich gehe davon aus, dass die meisten Leser mit diesem Datenmodell besser vertraut sind als mit den drei bisher beschriebenen Modellen. Deshalb werde ich auf die Ausführung der Konstrukte verzichten. Ich spreche in diesem Kontext vorzugsweise von einem SDM, um die Verwechslung mit dem weiter verbreiteten Begriff ERD zu vermeiden, der KEIN physisches Datenmodell beschreibt. Das SDM stellt eine technische Referenz dar, die oft mithilfe des grafischen Diagramms und im Rahmen eines Data-Dictionary-Dokuments aufgezeichnet wird. Dieses Dokument, das detaillierte Bezüge zu allen im SDM implementierten Datenbankobjekten bereitstellt, sollte ihren jeweiligen Zweck, ihre referentiellen Integritätsregeln und weitere wichtige Informationen zu den beabsichtigten Verhaltensweisen enthalten. Nachfolgend eine bewährte Struktur, die ich verwende:
- Objektname und -definition (Tabellen/Ansichten)
- Dateiname SQL-Objekterstellung/-änderung
- Geschäftsbereich und funktionale Verwendung
- Version/Integritätsstufe
- Spalten/Datentypen/Größe
- Nullbarkeit
- Standardwerte
- Primärschlüssel
- Fremdschlüssel
- Natürliche Schlüssel im Unternehmen
- Eindeutige Einschränkungen
- Prüfeinschränkungen
- Eindeutige und nicht eindeutige Indexe (Clustered und Non-Clustered)
- Kontrollflüsse (bei Design/Nutzung mit erhöhter Komplexität)
- Nützliche Kommentare
- Änderungsverlauf
Ein SDM-Data-Dictionary listet Objekte der Einfachheit halber alphabetisch nach Namen auf. Da die meisten physischen Datenmodelle stark normalisiert sind (siehe Teil 1 dieser Blog-Reihe), sollten referentielle Integritätsregeln für jede Tabelle angegeben werden. Meiner Erfahrung nach gibt es viele Möglichkeiten für den Umgang mit diesen Regeln, insbesondere beim Ausführen von SQL-Objekt-Skripts für ein vorhandenes Schema. Sie können einfach die Integritätsprüfung deaktivieren, die Skripts ausführen und die Prüfung wieder aktivieren. Ich bin zwar kein Fan dieser Methode, da sie zu Fehlern führen kann, aber sie ist leicht umzusetzen.
Ich nehme mir stattdessen die Zeit, mich mit bestimmten Referenzen zu allen Tabellen vertraut zu machen, und weise ihnen jeweils eine Integritätsstufe zu. Eine Tabelle mit der Bezeichnung „Integritätsstufe“ gibt die hierarchische Reihenfolge der Beziehung von übergeordneten und untergeordneten Tabellen an. Kurz gesagt: die Tabelle „Integritätsstufe“ basiert auf einer Fremdschlüsselreferenz zu übergeordneten Tabellen. Beispiel:
- Eine Tabelle ohne übergeordnete Tabellen: L0 (Level 0) bzw. Stufe 0 (höchste Stufe)
- Eine Tabelle mit mindestens einer übergeordneten Tabelle: L1 bzw. Stufe 1
- Eine Tabelle mit mindestens einer übergeordneten Tabelle, die jedoch eine übergeordnete L0-Tabelle hat: L2 bzw. Stufe 2
- Eine Tabelle mit mehreren übergeordneten Tabellen, die übergeordnete Tabellen unterschiedlicher Stufen haben: niedrigste Stufe +1
- Beispiel 1: Tabelle A ist L0, Tabelle B ist L1 > die untergeordnete Tabelle ist L2 Beispiel 2: Tabelle A ist L1, Tabelle B ist L4 > die untergeordnete Tabelle ist L5
- Und so weiter …
Hinweis: L0 ist die höchste Stufe, da eine L0-Tabelle keine übergeordneten Tabellen haben kann. Die niedrigste Stufe wird durch das physische Datenmodell bestimmt. Diese Methode beugt zudem Zirkelbezügen vor (m. E. eine schlechte Datenmodellierungspraxis).
Das physische Datenmodell ist das einzige Modell, das tatsächlich implementiert wird. Ich führe diese Implementierung vorzugsweise mit SQL-Skripts zur Objekterstellung (SOCS, SQL Object Creation Scripts) durch. Bei der Verwendung dieser Methode habe ich herausgefunden, dass der Database Development Life Cycle (DDLC) für ein beliebiges physisches Datenmodell entkoppelt und als unabhängiger Prozess durchgeführt werden kann, was sehr vorteilhaft, aber schwer zu erreichen ist. Der Grundgedanke ist die Erstellung einer SOCS-Datei für ein primäres Datenbankobjekt (Tabelle, Ansicht, Trigger oder gespeicherte Vorgänge). Die Skripts enthalten intelligente Prüfungen, um zu bestimmen, welche SQL-Anweisungen angewendet werden sollen (drop, create, alter usw.), und können mithilfe von übergebenen Switches und Arguments den Lebenszyklus berücksichtigen, den ich im vorherigen Blog-Eintrag beschrieben habe. Dieser beinhaltet:
- Neuinstallation: Basierend auf der aktuellen Version des Schemas
- Upgrade: Entfernen/Erstellen/Ändern von Datenbankobjekten durch ein Versionsupgrade
- Datenmigration: Durch ein radikales „Upgrade“ (Teilen von Tabellen oder Plattformwechsel)
Diese SOCS-Dateien beinhalten zudem Best Practices wie folgende (können variieren):
- Einheitliche Namenskonventionen
- Tabellennamen in GROSSBUCHSTABEN
- Tabellennamen in KLEINBUCHSTABEN
- Ansichtsnamen in Höckerschreibweise
- SOCS-Dateinamen beinhalten den Objektnamen
- Eine Primärschlüssel-Spalte mit entsprechend angepassten Ganzzahlwerten
- Entfernung redundanter/duplizierter Daten (Tupel)
- Entfernung aller Zirkelbezüge bei Schlüsseln (sodass übergeordneter Schlüssel > untergeordneter Schlüssel > übergeordneter Schlüssel auftreten kann)
- Eine SOCS-Datei pro Objekt
- SOCS-Dateien enthalten konsistente Header-/Zweck-/Verlaufsabschnitte, die dem verwendeten Data-Dictionary entsprechen
- SQL-Formatierung sorgt für Lesbarkeit und Wartbarkeit
Ich schlage vor, hier zunächst zu stoppen, da weitere Details zu meiner SOCS-Implementierung den Rahmen dieses Blogs sprengen würden. Ich komme eventuell ein anderes Mal darauf zurück. Ihr Feedback und Ihre Fragen sind jendefalls mehr als willkommen.
Übersicht der verschiedenen Datenmodelle
Hier eine kurze Übersicht der Schichten zum besseren Verständnis ihres jeweiligen Zwecks für die Modellierung sowie der Art und Weise, wie sie sich gegenseitig unterstützen und voneinander unterscheiden:
| DATENMODELLPERSPEKTIVE | GANZHEITLICH | SEMANTISCH | LOGISCHL | PHYSISCH |
|---|---|---|---|---|
| Datensilos | √ | |||
| Datensilo-Beziehungen | √ | |||
| Elementnamen | √ | |||
| Elementbeziehungen | √ | |||
| Elementgeneralisierungen | √ | |||
| Elementmerkmale | √ | |||
| Entitätsnamen | √ | |||
| Entitätsbeziehungen | √ | |||
| Entitätsschlüssel | √ | |||
| Entitätsattribute | √ | |||
| Entitätseinschränkungen | √ | |||
| Tabellen-/Ansichtsnamen | √ | |||
| Spaltennamen | √ | |||
| Spaltendatentypen | √ | |||
| Spaltenstandardwerte | √ | |||
| Primär-/Fremdschlüssel | √ | |||
| Indexnamen | √ | |||
| Indexeigenschaften | √ | |||
| Speicherkonfigurationen | √ |
Fazit
Ich bedanke mich für Ihre Aufmerksamkeit und freue mich, dass Sie bis zum Ende durchgehalten haben. Die gute Nachricht ist: wir haben es geschafft. Hurra! Ich hoffe, dass Ihnen diese Informationen geholfen haben. Wenn gute Talend-Entwickler sich wirklich mit ihren Datenmodellen auskennen, entstehen Designvorlagen und Best Practices. Sollten Sie meine Blogs zu diesem Thema noch nicht gelesen haben, finden Sie hier den Link zu Teil 4. Dort finden Sie auch die Links zu den Teilen 1, 2 und 3. Außerdem möchte ich Ihnen den Blog mit dem Titel Building a Governed Data Lake in the Cloud (Aufbau eines verwalteten Data Lake in der Cloud) ans Herz legen, den ich mit meinem guten Freund Kent Graziano von Snowflake Computing verfasst habe, einem geschätzten Partner von Talend.
