データモデルの設計とベストプラクティス(第2部)
データモデルとは何を指すのでしょうか。毎日データモデルに接して熟知しているTalendの開発者は、以下のようにデータモデルを定義しています。
- ビジネスシステムデータの構造的定義
- ビジネスデータのグラフィカルな表現
- ビジネスソリューションを構築するためのデータ基盤
これらはいずれも真実かもしれません。しかしあえて言うなれば、いずれも本質的な定義ではありません。それぞれ単独では、データモデルが本来実現すべき核心/目的あるいは目標に到達するものではなく、末梢的であるためです。
では、何が本当にデータモデルであると言えるのでしょうか。あれこれ思いつくものの、やはり一点に尽きるのではないでしょうか。私にとって、データモデルは、ビジネス情報システムをグラフィカルな方法で明確に特徴付けるものとして表現される構造基盤です。どう思われますか? 上記の定義と同一というわけではありませんね。この定義は、すべての要素を単一の目的に包含します。つまり、データだけでなく、構造的にビジネスのユースケースに関する情報を識別するための手段なのです。
このブログシリーズの第1部では、50年間のデータモデリングの歴史を4つの短い段落にまとめました。省いた部分もありますが、前任者から学んだ教訓と改善の結果として、データモデリングに関する私たちの知識や達成がどのように実現したのかを理解できるのではないでしょうか。今日、ほとんどの企業が要件を検証するために活用しているデータモデルには、真のビジネス価値があります。しかし、これらの企業が正しい方法を理解しているかどうかを疑問に思うことがよくあります。多くの場合、永続性のあるデータモデルに対する幻想は、とりあえずモデルが存在するという事実のみによって推定され、それが正しいかどうかは確認または検証されていないのです。
私は、データアーキテクチャーとデータベース設計の実務家として、あまりにも多くの粗悪なデータモデルを目にしてきたため、ほとんどのデータモデルには何らかの問題があると言わざるを得ません。その一方で優れたモデルも多く見てきましたが、それではデータモデルの良し悪しをどのように判断できるのでしょうか。それは重要なことなのか、データの出入りに問題がなければ十分ではないのか、と疑問に思われるかもしれません。しかし、データモデルの良し悪しは明らかに重要なのです。データモデルを基盤として/データモデルと協調して運営されるビジネスシステムを確実に成功させるためには、データモデル自体が優れたものである必要があります。データモデルはビジネスの本質です。したがって、包括的であり、非の打ちどころがなく、回復力のあるものでなければなりません。
このことから、優れたデータモデルを使用する動機は明らかです。Talend StudioのようなETL/ELTツールを使ってデータを出し入れし始めると、それが明らかになります(ほとんどの人には)。どのようなソフトウェアプロジェクトでも、データモデルは欠かすことのできない3つの技術的要素の1つです。ほかの2つの要素は、アプリケーションコードとユーザーインターフェイスです。
本シリーズの第1部では、私が設計するすべてのデータモデルで採用されているデータベース開発ライフサイクル(DDLC)の方法論を取り上げましたが、お読みいただいたでしょうか。この方法論は私にとって役立つものであり、データベース開発に本気で取り組んでいるすべてのチームはぜひとも採用すべきです。このプロセスを理解して採用することで、データモデルの実装と保守を合理化/自動化/改善できます。しかし、このプロセスについては、ほかの事柄も検討する必要あります。ビジネスに貢献する信頼性、柔軟性、正確性を備えたデータモデルを促進できる、追加のベストプラクティスをご紹介します。
データモデリングのベストプラクティス
多くのデータモデルは、モデラーが論理モデルを作成してから物理モデルを作成するプロセスによって設計されます。通常、論理モデルは実体と属性、および両者を結び付ける関係を記述して、データのビジネス目的を明確に表現します。続いて、物理モデルは論理モデルを実装します(論理モデルは、テーブル、列、データ型、索引として、簡潔なデータ整合性規則と共に実装されます)。これらの規則は、プライマリーキーと外部キー、およびデフォルト値を定義します。さらに、必要に応じて実装をサポートするために、ビュー、トリガー、ストアドプロシージャーが定義されることがあります。物理モデルは、ほとんどのホストシステム(Oracle、MS SQL Server、MySQLなど)が提供する特定の構成オプションに基づいて、ディスク上のストレージ割り当ても定義します。
納得できることですね。それにもかかわらず、私は論理モデルと概念モデルの違いをめぐる激しい議論を何度も経験してきました。多くの人は、これら2つは同じであり、どちらもビジネスデータの実体と属性を提示するものであると言います。私も同意見です!概念モデルは、データに対するビジネス上の理解(技術的な理解ではありません)についてコンテキストを提供することを目的とします。概念モデルはすべてのステークホルダーが理解できるものであり、多くの人が実体と属性に取り組んでいます。適切な概念モデルは、すべての関係者にとってビジネスデータのコミュニケーションのために最善のツールになります。統一モデリング言語(UML)(英語)の側面を使用することで、概念モデルを図解して、細かい事柄にとらわれずにシンプルに保持できます。詳細は論理モデルと物理モデルで不可欠ですが、それぞれで洗練させればよいでしょう。
一般的に多くのアプリケーションシステムを使用しているエンタープライズビジネスでは、データのモデル化で高次の懸念が生じます。概念モデル、論理モデル、物理モデルだけでは十分ではありません。そこで登場するのが、全体論的データモデル(少なくとも、私がそれを改造したモデル)です!
全体論的データモデルの目的は、企業全体でデータサイロを識別・抽象化することです。これにより、データサイロが存在する場所、必要な場所、相互に関連する場所、そして最も効果的に使用するために体系づける方法を大局的に説明します。
データモデリングプロセスの4つの階層
企業内に4タイプの異なるデータモデルが存在する可能性を考慮して、定義、理解の洗練化、および具体的な設計のために、「階層」としてトップダウン型で従うデータモデリングプロセスを次のように提案します。各レベルの主要な役割については、プロセスのどこで誰が関与したかを明確にします。
全体論的データモデル:
全体論的な層は、全社的なデータサイロの抽象的な環境を表します。このデータモデルは、広範なビジネスデータガバナンスを確立する機会を生み出し、それによって企業に固有のすべてのデータ関係に対する理解を深めることができます。それらのサイロは、社内外のアプリケーションからのデータを取り込むことを目的としています。バブルチャートを使用すると、全体論的データモデルを図解できます。以下のように設計します。
バブルチャート – データサイロ
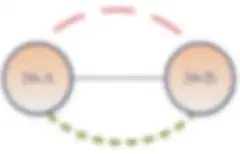

バブルの周囲を、より大きいバブルが囲むことがあります。大きい方のバブルは、そのデータサイロに固有の分類を体系化するオントロジーが存在する(または存在すべきである)ことを意味します。オントロジーとその分類メタデータは、それが囲むサイロへの有意義なマッピングを提供します。これは、データを高度に検索可能にするのに大いに役立つものであり、この層で識別されるべきです。
ここに示したのは、完全に定義された全体論的データモデルの図解の一例です。プリンターで大きく印刷して壁に貼り、皆で検討することで、活発で生産的な会話が生まれ、それがビジネスにとって効果的で価値ある資産になります。
概念データモデルとは:

UML情報アーキテクチャー
各要素オブジェクトは、データサイロの特定部分と、2つ(やはり2つだけ)の要素間の関係を定義する接続線(「リンク」)をカプセル化します。特定の要素項目(「特性」)は、オブジェクトの理解と目的をさらに支援するために定義され、以下のいずれかになります。
- 保護(値は事前に決定)
- パブリック(値は可変)
- プライベート(値の使用が制限)
直接的に相互接続された要素オブジェクトは、グレーの実線のリンクと意図的なラベルによって示される「関連付け」を持つと見なされます。これらの関連付けは、親要素に付けられた菱形により、次のいずれかの関係を表します。
- 単純(菱形なし)
- 共有(塗りつぶしのない菱形)
- 複合(塗りつぶされた菱形)
子要素が「ナビゲート可能」な場合は、矢印と関係基数(0.* = ゼロから多数、など)で示されます。
要素オブジェクトは、「一般化」を持つこともできます。つまり、オブジェクトのインスタンスは、特定または一意の特性や関係を持つことができます。この例では、オブジェクトは1つの親要素のサブクラスに似ており、親のすべての特性に加えて、関連する一意の特性をすべて追加的に含みます。サブクラス要素は、その名前と表現の両方で洗練化されることで、抽象化された全体論的データサイロの理解しやすい洗練化を提供します。要素オブジェクトに結合する一般化は、親オブジェクトに閉じた矢印が付いた青色の実線のリンクで示され、ラベルは不要です。
サブクラス間の結合は、それが表す概念データモデルの理解に役立つ関係をさらに定義します。同じ親オブジェクトのほかの一般化サブクラスに結合する一般化サブクラスは、緑色の実線のリンクと意図的なラベルで示された「関連付け」を持つと見なされます。これらの関係は任意に「ナビゲート可能」なこともあり、その場合は開いた矢印と関係基数(0.* = ゼロから多数、など)によって示されます。
UML図を完成させると、要素は、親オブジェクトの定義を拡張する特性である自己結合の関連付けや、具体的な特性間の「関連付け」を持つことができます。特定の拡張はクラスや一般化を表すものではありませんが、抽象化されたデータサイロをよりよく理解するために呼び出される関連の特性を識別します。特定の特性と要素の結合は、赤色の実線のリンクと意図的なラベルで示されます。さらに、要素特性は、同じ親オブジェクトのほかの要素特性に結合でき、関連する一般化と同様に緑色の実線のリンクで示されます。これらの関係は、オプションの開いた矢印と関係基数(0.* = ゼロから多数、など)により「ナビゲート可能」として示されることもあります。
概念データモデルは、クラスベースのメタファーを使用して特定のデータ要素を記述します。そのための図解に最も適したUMLは、抽象化された全体論的データサイロをさらに説明します。その目標は、ビジネス情報を定義、洗練化、緩和しながら、アプリケーション、実装ルール、または技術的詳細にとらわれず、さらに全体論的モデルから除外された詳細をカプセル化することです。
繰り返しますが、このモデルをプリンターで大きく印刷して共通のインターフェイスとすることで、後続の論理データモデルや物理データモデルを使用せずにアプリケーションコードを記述できます。この利点により、後続のデータモデルが作成される前の検証ポイントとしても利用できます。ソフトウェアエンジニアリングとステークホルダーの両方によるUMLモデルの検証は、データモデリングプロセスにおける重要なマイルストーンです。ここに示すのは、概念データモデルの一例です。
このモデルには、「主要素」の特定の側面を定義する「部分要素」があり、繰り返しのある独自の特徴を明確化します。
論理データモデルとは:
論理層は、ドメイン実体(論理データオブジェクト)、それらの属性、それらの間の特定の関係が体系づけられたセマンティック情報の抽象的な構造を表します。概念モデルの要素オブジェクトから派生したこのデータモデルは、特定のホストストレージテクノロジーに関係なく、関連する詳細(キー/属性)と実体間の関係を定義します。実体は、適切なデータ構造をカプセル化するために、必要に応じて単一の要素、要素の一部、または複数の要素を表します。論理データモデルは、概念モデルで識別された構造実体とレコードセットをカプセル化して特定の属性を追加し、関連するデータの理解を深めるよう支援します。以下のように設計します。
ERD
実体関連図(ERD)は、独立して存在できる固有に識別可能な実体について説明し、実体はプライマリーキー(PK)と呼ばれる固有の識別属性の最小セットを必要とします。子実体が何らかの親実体にリンクされている場合、参照データの整合性は、外部キー(FK)と呼ばれる親のプライマリーキー属性と一致する、子実体で識別属性を使用することによって強化できます(また、そうすべきです)。皆さんもよくご存じかと思います。
状況に応じて、実体を互いにリンクすることで、レコードセットの性質、または複数の実体間の基数関係を示すことができます。リンクを持つ実体は、実体関係図(ERD)に広く採用されているCrow's Foot(カラスの足)記法の手法を利用できます。青色の実線のリンクで示されたように、両側の適切なカラスの足の表記には、それが表すレコードセットを説明するための意図的なラベルも含める必要があります。これらの実体リンクは、レコードセットの許容レコード数を説明する特定の基数を表します。これらの記法は、0、1つまたは多数の行、あるいは何らかの強制的組み合わせのいずれかを指定します。
基数の規則は、実体に最も近い表記が最大カウントである関係に参加できる、各実体の行の最小数と最大数の2つだけです。レコードセットの基数の指定は、その関係がオプションであるか必須であることも示唆します。これは、物理データモデルの設計に役立ちます。
ERDは自己結合リンクを含む複数の実体へのリンクをサポートできます。実体をテーブルと混同しないでください。ただし、物理データモデルのテーブルにしばしば実体を直接マップできます(下記参照)。代わりに、論理実体は概念データモデルからの合理化された表現に焦点を合わせる構造的抽象化です。
論理データモデルは、概念データモデルのセマンティック抽象化を提示して、物理データモデルを設計できる詳細を提供します。このメリットは、抽象化されたデータ構造だけでなくデータトランザクションの要件についても理解するための基盤として、アプリケーションサービスエンジニアとデータベースエンジニアの両方に役立ちます。以下は、論理データモデルの選択の一例です。
ここで、いくつかの点に注意してください。多様な機能領域を表すために色分けしました。機能領域は概念モデルと全体論的モデルに対応できます。また、ENTITY_DとENTITY_Cの間に「仮想」の関係(ライトグレーのリンク)を組み入れました。これは、論理的な関係が存在することを示しますが、これら2つの実体間の構成体に加えてENTITY_Bは「循環参照」を示しており、これは物理モデルでは完全に避けるべきものです。また、値の配列を定義するいくつかの属性があります。論理モデルでは、モデルを単純化し合理化するので問題ありません。物理モデルで必ず正規化してください。
物理データモデル:
物理層は、論理データモデルから派生したホストシステムのアーティファクト(物理データオブジェクト)の構成と、期待されるストレージ構成を表します。このデータモデルは、テーブル、列、データ型、キー、制約、権限、索引、ビュー、データストアで利用可能な割り当てパラメーターの詳細を組み入れます(データストアの詳細については、私のブログ記事データボルトの先へをご覧ください)。これらのホストアーティファクトは、ソフトウェアアプリケーションを構築するための基盤となる実際のデータモデルを表します。物理データモデルは、論理データモデルで定義された実体および属性からの、これらすべてのアーティファクトをカプセル化し、最終的に実際のデータを保存/取得するためのアプリケーションアクセスを可能にします。以下のように設計します。
SDM
スキーマ(物理)設計モデル(SDM)は、データベース情報システムに関与する特定のオブジェクトを定義します。ほとんどの読者は、前の3つのデータモデルよりもこのデータモデルについて詳しいと思いますので、構成体については説明しません。物理データモデルではない、より広く使用されているERDという用語と混同しないように、SDMと呼びたいと思います。その代わりに、SDMが提供するエンジニアリング参照は、グラフィカルな図とデータ辞書ドキュメントの両方と一緒にしばしば記録されます。SDMで実装されているすべてのデータベースオブジェクトへの重要で詳細な参照を提供するこのドキュメントには、その目的、参照の整合性規則、意図された動作に関するその他の重要情報を組み入れるべきです。以下は私が使用している構造です。
- オブジェクト名と定義(テーブル/ビュー)
- SQLオブジェクト作成/変更ファイル名
- ビジネスドメインと機能活用
- バージョン/統合レベル
- 列/データ型/サイズ
- null許容性
- デフォルト値
- プライマリーキー
- 外部キー
- ナチュラルビジネスキー
- UNIQUE制約
- CHECK制約
- UNIQUE索引/非UNIQUE索引(クラスター化/非クラスター化)
- 制御フロー(余計な複雑な設計/使用が関与する場合)
- 有用なコメント
- 変更履歴
SDMデータ辞書は、使いやすさのためにオブジェクトを名前のアルファベット順で参照します。ほとんどの物理データモデルは高度に正規化されているため(本シリーズの第1回で述べています)、各テーブルについて参照整合性規則を呼び出す必要があります。これまで、特に既存のスキーマに対してSQLオブジェクトスクリプトを実行するときに、これらの規則のさまざまな対処法を目にしてきました。単に整合性チェックをオフにし、スクリプトを実行してから作業をオンに戻すだけでも機能します。この方法は簡単ですが、エラーが発生しやすいので私の好みではありません。
その代わりに、私は時間をかけて、すべてのテーブルへの特定の参照を理解し、それぞれに一定の整合性を割り当てます。テーブル「整合性レベル」は、親/子テーブルの関係の階層的な順序を識別します。つまり、「整合性レベル」という表は、親表に対する外部キーの参照に基づきます。たとえば次のようになります。
- 親テーブルを持たないテーブル:L0 - またはレベル0(最高レベル)
- 少なくとも1つの親テーブルを持つテーブル:L1またはレベル1
- 少なくとも1つの親テーブルを持つテーブル(ただし、その親テーブルはL0親テーブルを持つ):L2またはレベル2
- 異なるレベルの親テーブルを持つ複数の親テーブルを持つテーブル:最低レベル+1を使用
- つまり、親AはL0、親BはL1、したがって子テーブルはL2 または、親AはL1、親BはL4、したがって子テーブルはL5
- 以下同様
注記:L0は、親テーブルがないため最高レベルになります。最低レベルは物理データモデルによって決定されます。この方法では、循環参照(データモデル設計における不適切なプラクティス)が作成される可能性も排除されます。
物理データモデルは、実際に実装されるモデルです。SQLオブジェクト作成スクリプト(SOCS)を、この実装で使用することを好みます。この方法を使用して、物理データモデルのDDLCは独立したプロセスとして切り離すことができることを発見しました。これは非常に望ましく、また達成が困難です。その目的は、1つのプライマリーデータベースオブジェクト(テーブル、ビュー、トリガー、またはストアドプロシージャー)に対して1つのSOCSファイルを作成することです。これらのスクリプトには、適用するSQL文(drop、create、alterなど)を決定するためのインテリジェントなチェックが含まれています。以前のブログで説明した、ライフサイクルを考慮して渡されたスイッチと引数を通じて、次のことができます。
- 新規インストール:スキーマの現行バージョンに基づく
- アップグレードの適用:データベースオブジェクトをドロップ/作成/変更し、あるバージョンから次のバージョンへとアップグレード
- データ移行:中断を伴う「アップグレード」が発生(テーブルやプラットフォームの分割など)
これらのSOCSファイルには、次のようなベストプラクティスも含まれています(皆さんのベストプラクティスと同一ではないこともあります)。
- 一貫した命名規則
- テーブル名はすべて大文字
- 列名はすべて小文字
- ビュー名はすべてキャメルケース
- SOCSファイル名はオブジェクト名を含む
- 適切なサイズの整数を使用した単一列プライマリーキー
- 冗長/重複データの排除(タプル)
- すべての循環キー参照の削除(親 > 子 > 親の参照が発生する可能性がある場合)
- オブジェクトごとに単一のSOCSファイル
- SOCSファイルは、このデータ辞書と一致する一貫したヘッダー/目的/履歴セクションを含む
- SQLフォーマットは読みやすさと保守性を提供
私のSOCS実装の詳細は、このブログの範囲外です。別の機会に書くかもしれません。皆さんからのフィードバックや質問をお待ちしています。
データモデルを求める理由とは?
これらの階層について簡単にまとめることで、目的、およびモデリングプロセスでのサポートや相違を理解するのに役立ちます。以下の表を参考にしてください。
| データモデルの側面 | 全体論的 | 概念 | 論理 | 物理 |
|---|---|---|---|---|
| データサイロ | √ | |||
| データサイロの関係 | √ | |||
| 要素の名前 | √ | |||
| 要素の関係 | √ | |||
| 要素の一般化 | √ | |||
| 要素項目 | √ | |||
| 実体の名前 | √ | |||
| 実体の関係 | √ | |||
| 実体のキー | √ | |||
| 実体の属性 | √ | |||
| 実体の制約 | √ | |||
| テーブル名/ビューの名前 | √ | |||
| 列の名前 | √ | |||
| 列データ型 | √ | |||
| 列のデフォルト値 | √ | |||
| プライマリーキー/外部キー | √ | |||
| 索引の名前 | √ | |||
| 索引のプロパティ | √ | |||
| ストレージの構成 | √ |
まとめ
読み進めていただき、ありがとうございました。ここまでで重要事項はほとんど取り上げました。皆さんにとって有益な情報となることを願います。優れたTalend開発者がデータモデルを把握することで、ジョブ設計パターンとベストプラクティスが明らかになってきます。このトピックに関する私のブログをまだ読んでいない場合は、第4部をご覧ください。第1部~第3部のリンクもその中に記載されています。また、クラウドにおける「管理されたデータレイク」もご覧ください。Talendの重要パートナーであるSnowflake Computing社のKent Graziano氏と私が共同で執筆した記事です。
