Talendのジョブ設計パターンとベストプラクティス(第2部)
前回掲載した、Talendのジョブ設計パターンとベストプラクティスの第1部は、非常に好評をいただきました。読んでくださった方、ありがとうございます。まだ読んでいない方は、ぜひお読みください。第2部では、第1部の内容をもとに、さらに詳細な内容を解説していきます。また、さらに高度な内容についてもいくつかご紹介しようと思います。
はじめに
私は、Talendの開発に長年携わってきましたが、他の開発者がジョブを作成する方法に対して常に興味を持っています。機能を正しく使用しているか、一般的なスタイルを使用しているか、それとも私が知らないスタイルなのか、他にはない優れたソリューションを開発しているか、キャンバス/コンポーネントデータ/ワークフローが持つ抽象的な特性に苦労しているのではないか。答えがどうであれ、重要なのは、設計の意図に沿ってツールを使用することです。これこそが、このブログでジョブ設計のパターンとそのベストプラクティスを解説している理由です。Talendの機能をすべて理解しただけでは十分ではなく、ジョブを作成する最適な方法を理解する必要がある、と私は考えています。
論理的には、「ビジネスユースケース」はあらゆるTalendジョブの基本的な推進要素です。実際には、同じワークフローでもさまざまなバリエーションがありますし、ワークフローにもさまざまなタイプが存在します。このような「ユースケース」のほとんどは、「データソースからデータを抽出して処理し、そのデータを変換した後、最終的には別のターゲットにロードする」という最もシンプルな形式で行われるデータ統合ジョブ、という大前提からスタートします。この点で、ETL/ELTコードは私たちの作業の活力源であると言えます。これは、Talendで日々コーディングに取り組んでいる開発者の皆さんがよくご存じなので、ここでは扱いません。第2部では、皆さんの視野を広げる内容をご紹介したいと思います。
Talendの最新リリース(v6.1.1)は、これまでで最高のバージョンだと思います。ビッグデータ、Spark、機械学習、UIのモダナイゼーション、継続的な統合と展開の自動化(他にも多彩な機能が実装されています)において、コンポーネントが新たに加わりました。今日販売されているデータ統合テクノロジーの中で最も優れた堅牢性と機能性を誇るバージョンです。少々手前味噌かもしれませんが、ユーザーの皆さんも私と同じ評価をしてくださると思います。ぜひ、ご自分で実感してみてください。
DIプロジェクトを成功へと導く3つの基本的指針
では、始めましょう。椅子が立つには、脚が少なくとも3本は必要です。これは、ソフトウェア開発にも当てはまります。データ統合プロジェクトの作成とデリバリーを成功させるには、3つの基本的な要素が存在します。
- ユースケース - 明確に定義されたビジネスデータ/ワークフロー要件
- テクノロジー - ソリューションを構築、展開、実行するツール
- 手法 - 一般的に合意された実行方法
上記を念頭に、明確に定義された「開発ガイドライン」ドキュメント(このシリーズの第1部を読んでいただけたでしょうか? プロジェクト用のドキュメントは作成されていますか?)に沿って、前提となる条件を構築していきましょう。
基本的指針の拡張
Talendの「ジョブ」が「ユースケース」ワークフロー内のテクノロジーであれば、ジョブ設計パターンはそれを構築するベストプラクティスの「手法」です。このブログの内容で最も重要なことは、一貫した方法でジョブを作成する、という点です。もしもより良い方法が見つかり、それがうまく機能しているのであれば、そのまま進んでください。ただし、パフォーマンス、再利用性、保守性の向上に苦戦している方や、変化を続ける要件に合わせてコードのリファクタリングを続けている方には、これらのベストプラクティスが役立ちます。
さらに検討すべき9つのベストプラクティス:
ソフトウェア開発ライフサイクル(SDLC)
億万長者のMarcus Leminos氏が提供する番組、「The Profit」(CNBC)によれば、「人、製品、プロセス」は、あらゆるビジネスの成否を分ける3大要素です。これには、私も同意します。SDLCプロセスは、ソフトウェア開発チームの要です。このプロセスを適切に行うことが非常に重要であり、それを無視すれば、プロジェクトに深刻な影響を及ぼし、プロジェクトは失敗に陥ってしまいます。TalendのSDLCベストプラクティスガイドには、Talendが開発者に提供する継続的統合と展開に関する概念、原則、仕様、詳細な説明が記載されています。前のブログ記事でご紹介した「開発ガイドライン」ドキュメントにSDLCベストプラクティスを反映することを、すべてのソフトウェア開発チームにお勧めします。
ワークスペースの管理
Talend StudioをノートPC/ワークステーションにインストールすると(管理者権限があるものとします)、デフォルトの[Workspace]ディレクトリがローカルディスクドライブ上に作成されます。多くのソフトウェアインストールと同様に、このデフォルトディレクトリは、実行可能ファイルと同じディレクトリ内に作成されます。私は、これは良いプラクティスだとは思いません。なぜでしょうか。
プロジェクトファイル(ジョブ、リポジトリメタデータ)のローカルコピーは、この[Workspace]に格納されます。これを、ソースコード管理システム(SVN、GIT)にTalend Administration Center(TAC)を介してアタッチすると、プロジェクトをオープンまたは保存するたびに同期が行われます。このようなファイルは、簡単に識別および管理できる場所に格納すべきです。ディスク(または別のローカルドライブ)上に格納するのがよいでしょう。
ワークスペースは、Talend Studioで接続を作成する際に使用されます。接続は、「ローカル」と「リモート」のいずれかです。この2つの相違点は、「ローカル」接続がTACで管理されないのに対して、「リモート」接続はTACで管理される、という点です。一般的に、サブスクリプションユーザーは「リモート」接続のみを使用します。
チーム全員が使用する「開発ガイドライン」ドキュメントでディレクトリ構造を明確に定義することで、最適なコラボレーションを実現できます。ここで重要なのは、チームの同意を得て、規範を徹底し、一貫性を維持することです。
参照プロジェクト
皆さんは、参照プロジェクトを使用していますか。参照プロジェクトをご存知でしょうか。参照プロジェクトは、シンプルであるにもかかわらず生産性を高める機能なのですが、使用していないユーザーが数多く存在します。再利用可能な汎用コードを作成し、複数のプロジェクトで共有することは、開発者共通のニーズです。開発者は、プロジェクトを開始する際、コードの一部をコピーし、別の(または同じ)プロジェクトやジョブに貼り付ける、という作業をよく行います。または、あるプロジェクトのオブジェクトをエクスポートし、別のプロジェクトにインポートすることもあるでしょう。かつては、私もこの方法を使用していました。このような方法に問題はないのですが、お勧めはしません。このプロセスには、保守において深刻な問題が発生する危険が潜んでいます。そこでお勧めなのが、参照プロジェクトです。私は、参照プロジェクトを見つけたとき、とても嬉しかったことを憶えています。
TACを使用してプロジェクトを作成している方は、ひっそりと存在する[Reference]チェックボックスに気付き、「これは何だろう?」を思ったことがあるのではないでしょうか。プロジェクトを作成し、このチェックボックスを選択して「参照プロジェクト」を作成すると、他のプロジェクトを「含める」設定や「リンク」することが可能になります。「参照プロジェクト」で作成したコードは、リンクしたプロジェクト内で使用できるようになるため(読み取り専用)、再利用可能性が非常に高まります。このプロジェクトには、共通のオブジェクトやコードをすべて格納すべきです。

ただし、「参照プロジェクト」は最小限に留める必要があります。ベストプラクティスでは、参照プロジェクトの数は1つに限定してください。場合によっては、2つまたは3つでも問題ありません。注意:「参照プロジェクト」の数が多すぎると、その効果が損なわれてします。参照プロジェクトでは、慎重な管理が非常に重要になります。その用途とルールを「開発ガイドライン」ドキュメントに明記し、チーム全体が順守することにより、最適なコラボレーションを実現できます。
オブジェクトの命名規則
「名前が何だというのか。どのような名で呼ばれようと、薔薇は美しく香る」という有名な台詞がありますね。
そうはいっても、やはり「命名規則」は重要です。どの開発チームも命名規則に関して検討し、プラクティスを確立すべきです。Talendオブジェクトの名前、命名のタイミング、命名方法にかかわらず、一貫性が必要不可欠です。Talendのオブジェクトの命名規則を「開発ガイドライン」ドキュメントに明記し、チーム全体が順守することで、最適なコラボレーションを実現できます(次第にパターンが見えてきたことにお気付きでしょうか)。
プロジェクトリポジトリ
Talend Studio(Eclipse IDE:Integrated Development Environment。簡単に言えば、ジョブエディターです)でジョブを開くと、左のパネルにプロジェクトリポジトリが表示されます。ここに、プロジェクトオブジェクトが格納されています。ここには、極めて重要なセクションがいくつか存在します。その1つが[job Designs]セクションであり、v6.1.1では3つのタイプのジョブ(データ統合、バッチ、ストリーミング)を作成できるように拡張されました。これ以外にも、知っておくべき重要なセクションがあります。
- コンテキストグループ - 組み込みのジョブコンテキスト変数を作成するのではなく、リポジトリのコンテキストグループ内に作成します。これにより、ジョブ全体で再利用可能になります(参照プロジェクトに含めた場合は、プロジェクト内でも使用可能)。そのためには、グループを効果的に編成する必要があります。SBX/DEV/TEST/UAT/PRODの環境ごとにグループを作成するのがベストプラクティスです。「デフォルト」のコンテキストは削除してください。

この例では、「SysENVTYPE」というコンテキスト変数が追加されています。この変数には、選択した環境内の動的なプログラマビリティで使用する値が格納されています。つまり、ジョブ内でこの変数を使用することによって現在の実行環境を特定できるため、条件付きロジックを使用してフローをプログラムで変更することが可能になります。
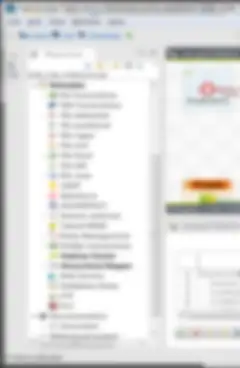
- メタデータ - メタデータはさまざまな形態を取ります。DB接続やテーブルスキーマも、多岐にわたるフラットファイル構造(.csv、.xml、.jsonなど)も、すべて活用してください。さらに、常に有用な汎用スキーマは、ここに書き切れないほどさまざまな用途に活用できます。
- ドキュメント - プロジェクトWikiを作成し、チームに公開します。役立つ情報など、プロジェクトに関するhtmlファイル群が作成されます。簡単に操作でき、わずか数分しかかかりません。
チームに役立つベストプラクティスをいくつか「開発ガイドライン」ドキュメントに掲載し、順守します。必要に応じて調整が必要ですが、この作業にはチーム全員が参加するようにしてください。
バージョン管理(ブランチとタグ付け)
ジョブのプロパティタブには、バージョン番号スキーマとして、「メジャー」と「マイナー」を指定する場所があります。さらに、ステータスを設定することも可能です。「development」、「test」、「production」といった値をデフォルトで設定できます。警告:これは、SVN/GITリポジトリで共同開発やソースコード管理(SCC)機能を利用しない単独の開発者(TOS:Talend Open Studio)向けに設計されています。この場合、内部ジョブプロパティが変わるたびに、ジョブの完全なコピーがローカルワークスペースに作成され、SCCシステムと同期する、という点に注意してください。私は、内部バージョンが10回以上変更され、ジョブがコピーされたプロジェクトを見たことがあります。ジョブのコピーがコピーされて増殖し、すべてがSCCと同期されます。その結果、プロジェクトは巨大になり、プロジェクトのオープンとクローズ時にパフォーマンスが大幅に低下する可能性があります。このような現象が発生している場合には、最新バージョンのみをエクスポートおよびインポートすることでワークスペースを消去する必要があります。面倒な作業ですが、やる価値はあります。
有料サブスクリプション環境のバージョン管理では、SCCネイティブのブランチおよびタグ機能を使用することがベストプラクティスです。SCCは保存したジョブの差分のみを保持するため、プロジェクトバージョンリリースの最適な管理方法です。これには、ジョブ履歴に必要なスペースを大幅に削減する効果もあります。数字や日付などを使用したバージョンスキーマを考え、「開発ガイドライン」ドキュメントに記載し、チーム全体が順守してください。
メモリ管理
ジョブの実行では、さまざまな項目を考える必要があります。どの程度のメモリ容量が必要になるか、データフローで膨大な数の行を処理するか、カラムやtMapのルックアップの数、ジョブを実行する「ジョブサーバー」で他のジョブも同時実行するか、「ジョブサーバー」に搭載されているコアやRAM、tMap結合は、[Load Once]と[Row by row]のどちらを設定するか、ジョブで子ジョブを呼び出すか、親ジョブに呼び出されるか、ネスト構造の数、子ジョブを別のJVM上で実行するか、ESBジョブを記述する場合、作成されるルートの数はいくつあるか、並列処理(下を参照)を使用するか、などがあります。いかがでしょうか。このような項目をすべて検討している人はいないでしょう。
デフォルト設定は、設定可能な基本値です。メモリ割り当てなど、ジョブにはいくつかのデフォルト値が設定されています。ところが、デフォルト値が常に適切であるとは限らず、実際には問題の原因になる可能性もあるのです。[Use Case Job Design]、[Operational Ecosystem]、[Real Time JVM Thread Count]がメモリ使用量を決定します。メモリ使用量は管理する必要があります。

JVMメモリ設定は、プロジェクトレベルや個々のジョブで指定が可能です(上記参照)。
[Preferences] > [Talend] > [Run]
すぐに作業を開始して問題を解決しましょう。メモリ管理は見落とされがちな作業ですから、開発と運用の両面で、チームのガイドラインに記載して順守する必要があります。このシリーズの第1部をまだ読んでいない方は、ぜひ読んでください。
動的SQL構文
多くのデータベース入力コンポーネントでは、SQL構文を[Basic Settings]タブで正しく指定する必要があります。もちろん、tMyDBInputコンポーネントに構文を直接入力することもできますが、ジョブや親ジョブを制御するロジックに基づいて、実行時に複雑なSQLクエリーを動的に作成することを考えると、こちらの方が簡単です。SQLクエリーの基本構成に使用する「コンテキスト変数」を作成し、tMyDBInputコンポーネントに到達する前のジョブフローで設定し、ハードコードクエリーの代わりにコンテキスト変数を使用します。
たとえば、「コンテキストグループ」を「参照」プロジェクトリポジトリに作成し、「SystemVARS」という名前を付けたとします。ここには、再利用可能な幅広い変数が含まれています。動的SQLのパラダイムには、次の「文字列」変数を定義し、初期値を「null」としました。

この変数をtJavaコンポーネントに設定し、次のように、tMyDBInputクエリーフィールドに組み込みます。
“SELECT “ + Context.sqlCOLUMNS + Context.sqlFROM + Context.sqlWHERE
変数値の連結では、値の後ろに「スペース」を入力することで見やすくなります。さらにきめ細かい制御が必要な場合には、「sqlSYNTAX」変数を使用し、SQL構文の句を連結する条件を制御して、Context.sqlSYNTAXをtMyDBInputクエリーフィールドに入力します。データベースホストから見ると動的SQLではありませんが、ジョブから見るとSQLは動的に生成されます。
以上の内容すべてをガイドラインに記載し、チーム全員が順守してください。
オプションの並列化
Talendは、コードを並列化するメカニズムをいくつか提供しています。適切かつ効率的に使用し、CPUコアやRAMへの影響をしっかりと検討することにより、優れたパフォーマンスを発揮するジョブ設計パターンを生成できます。では、オプションをご紹介しましょう。
- 実行計画 - 複数のジョブ/タスクをTACから並列実行する設定が可能です。
- 複数のジョブフロー - 1つのジョブ内で複数のデータフローを作り、同じスレッドを共有します。フロー間に依存関係がない場合、稀なユースケースシナリオのための手法となります。一般的に私はこの方法を使用せず、ジョブを個別に作成します。
- 親/子ジョブ - tRunJobコンポーネント内で子ジョブを呼び出すとき、[Use an independent process to run subjob]ボックスを選択することにより、別のJVMヒープ/スレッドが確立され、そこで子ジョブを実行できます。ただしこれは、厳密に言うと並列化ではありません。
- コンポーネント - tParallelizeコンポーネントは複数のデータフローにリンクします。tPartitioner、tDepartitioner、tCollector、tRecollectorコンポーネントは、データフローの並列スレッドの数を直接制御します。
- DBコンポーネント - ほとんどのDB入出力コンポーネントは、特定のSQLステートメントでスレッド数の並列化を有効にする高度な設定が可能です。大幅な効率化が可能ですが、値が大きすぎると逆効果です。ベストプラクティスとしては、2~5を指定してください。
上記の並列化手法を組み合わせてネスト化する場合にも、注意が必要です。メモリ使用スタックを把握し、ジョブ設計パターンの実行フローに細心の注意を払ってください。この並列化オプションは、高度な機能としてTalend Platformのみで提供されています。並列化のガイドラインはドキュメントから削除しましょう...というのは冗談です!
Talendジョブを成功させる秘訣
ジョブ設計パターンのベストプラクティスは、Talendジョブを作成する最善の方法を検討する際の参考になるはずです。ジョブの作成を成功へと導く基本は、ガイドラインの作成、規範、一貫性です。実践すること決定し、順守してください。データ/ワークフローのコーディングでは、次の点を留意してください。
「行動がすべての成功の鍵だ!」- パブロ・ピカソ
最後に、Talendジョブの作成を成功へと導く秘訣として、注意事項をまとめます。
- - tPreJobコンポーネントとtPostJobコンポーネントの両方を使用する
- キャンバスを煩雑にしない。コンポーネントを過剰にグループ化せず、少し広げる
- コードを見やすくレイアウトする。上から下へ、左から右へ
- 初回のコーディングでうまくいくと期待しない
- メインのジョブループを特定し、修了を制御する
- エラー処理手法を無視しない
- コンテキストグループを幅広く(DEV/QA/UAT/PROD)賢く使う
- 1つのジョブレイアウトを巨大にしない
- 小さなジョブモジュールを作成する
- 複雑にせず、シンプルにする
- 汎用スキーマを必ず使用する(単一カラムのスキーマを例外とすることも可能)
- オブジェクトに名前を付ける
- 必要に応じて(わずかではあるが)ジョブレットを使用する
- tJavaFlexコンポーネントの使いすぎに注意する。tJavaまたはtJavaRowで十分な場合がある
- プロジェクトドキュメントを作成して公開する
- 実行時メモリヒープの設定を省略しない
まとめ
いかがだったでしょうか。このシリーズはまだまだ続きますので、どうぞお楽しみに。次回は「ユースケースのサンプル」をお届けします。このブログ記事では、
基本的な概念を拡張し、より高度な内容をいくつかご紹介しました。ぜひ参考にしてください。皆さんが実践しているベストプラクティスに関するコメントをお寄せください。有意義なディスカッションになることを期待しています。では、次のブログ記事をお楽しみに。
関連リソース
Talend Open Studio for Data Integrationの紹介
この記事で取り上げている製品
