Talend Job Design Patterns and Best Practices: Part 2
What a delight to have had such a positive response to my previous blog on Talend “Job Design Patterns” & Best Practices. To all those who have read it, thank you! If you haven’t read it, I invite you to read it now before continuing, as ~Part 2 will build upon it and dive a bit deeper. It also seems appropriate for me to touch on some advanced topics now as well, so buckle your seatbelts! It’s about to get even more interesting.
Getting Started with Job Designs
As a seasoned Talend developer, I am always interested in how others build their Jobs. Are they using features correctly? Do they adopt a recognizable style or one I have not seen before? Have they come up with a unique and cool solution? Or is the abstract nature of the canvas/component data/work flow just a bit overwhelming leading some down a dark path to nowhere? Regardless of the answer to any of these questions, I feel it is very important to use the tool as it was designed to be used. To that end, I have embarked on this journey to discuss “Job Design Patterns” and the Best Practices that go with them. It seems to me that even after learning about all the features and functionality of Talend, the fundamental need remains: to understand the best way to build Jobs!
Logically the “Business Use Case” is the key fundamental driving factor for any Talend job. In fact, I’ve seen many different variations on the same workflow and many different varieties of workflows. Most of these ‘Use Cases’ start from the basic premise that a data integration job in its most simple form is extracting data from some source and processing it; perhaps transforming it along the way; eventually to load it into some target elsewhere. ETL/ELT code therefore, is our life blood. It is what we Talend developers do. So let me not bore you with what you already know. Let’s expand our perspective instead…
Without much debate, the latest Talend release (v6.1.1) is the best version I’ve ever worked with. With all the new components in Big Data, Spark, Machine Learning, the Modernized UI, and automated Continuous Integration/Deployment (just to name a few highlights), I feel that this is the most robust and feature-rich data integration technology available in the market today. OK, my bias is showing a bit, yet I am quite empathic to you, our customer, having been in your shoes, so I hope you can take this at face value and I’ll accept that you will judge for yourself.
3 Foundations of a Successful DI Project
OK, so you’d agree that a stool cannot stand without at least 3 legs; right? The same is true with developing software. There are three essential elements required to build and deliver a successful data integration project:
- Use Case - a well-defined business data/work flow requirement
- Technology - the tools with which we craft, deploy, and run the solution
- Methodology - a given way to do things that everyone agrees with
With this in mind, and having a well defined “Development Guidelines” document (did you read my previous blog? did you create one for your project?), let’s build upon these requisites.
Extending the Basics
If Talend ‘Jobs’ comprise the technology in a ‘Use Case’ workflow then ‘Job Design Patterns’ are the best practice ‘Methodology’ for building them. If nothing else I share in these blogs is of value to you, at least be consistent in how you build your jobs! If you have found a better way, and it works for you, great; don’t change anything. But if you struggle with performance, reusability, and maintainability or you constantly re-factor code to adapt to changing requirements, then these Best Practices are meant to help, you, the Talend Developer!
9 more Best Practices to consider:
Software Development Life Cycle (SDLC)
“People, Product, & Process”, according to billionaire Marcus Leminos “The Profit” (CNBC), are the 3 keys that determine any business success, or failure. I agree! The SDLC process is where the rubber hits the road for any software development team. Getting this right is essential and ignoring it severely impedes any project efforts often leading to a disastrous failure. Talend’s SDLC Best Practices Guide provides a deep look into the concepts, principles, specifications, and details on continuous integration and deployment features available to Talend developers. I highly recommend any software development team incorporate an SDLC Best Practice into their “Development Guidelines” document outlined in my previous blog in this series. Then Follow it!
Managing Workspaces
When you install the Talend Studio on your laptop/workstation (assuming you have admin rights) a default ‘Workspace’ directory typically is created on the local disk drive, and like many software installations this default location resides within the directory where the executables are placed. I truly don’t think this is a good practice. Why?
Local copies of project files (jobs and repository metadata) are stored in this ‘Workspace’ and when attached to a source code control system (ie: SVN or GIT) via the Talend Administration Center (TAC), they are synchronized when you open a project and when objects are saved. I believe that these files should reside somewhere you can easily identify and manage. Preferably this is elsewhere on the disk (or perhaps another local drive entirely).
To be clear, a workspace is utilized when you create any connection in Talend Studio. This can be a ‘local’ or a ‘remote’ connection; the difference being that a ‘local’ connection is not managed by the TAC and a ‘remote’ connection is. For our subscription customers the ‘remote’ connection is normally the only type used.
Organizing your directory structure should be clearly stated in your “Development Guidelines” document and adopted by the entire team for optimum cooperation and collaboration. The key is to agree on something that works for your team, instill the discipline, and be consistent.
Reference Projects
Do you use Reference Projects? Do you know what they are? I’ve found that many of our customers are not aware of this simple yet highly productive feature. We all want to create re-usable, common or generic code that can be shared across projects. Often I find developers opening up a project, copying a code fragment and then pasting it into a separate (sometime the same) project or job. Or alternatively they export objects from one project and then import them into another. I’m guilty! I’ve done both of these in the past. While these options basically work, doing so is not fine; a potential maintenance nightmare as any of you who have felt trapped in this process have discovered. SO WAIT! There is a better way: Reference Projects! Wow, was I happy when I discovered them.
If you have used the TAC to create projects you may have noticed an unobtrusive check box called ‘Reference’. Ever wondered what that was for? Well, if you create a project and check that box to make it a ‘Reference Project’ it then becomes available to ‘Include’ or ‘Link’ to any other project. Code created in this ‘Reference Project’ is available (as read only) in those linked projects becoming highly re-usable! This is the proper place to create any and all of your common objects and shared code.

Keep these ‘Reference Projects’ to a minimum however; we recommend having only 1 as a best practice, however in some debatable cases, having more (2 or 3) is possible. WARNING: creating too many ‘Reference Projects’ can defeat their purpose so don’t go overboard. Managing them carefully is very important; their use and rules should be clearly stated in your “Development Guidelines” document and adopted by the entire team for optimum cooperation and collaboration.
Object Naming Conventions
“What’s in a name? A rose by any other name is still a rose!” – Who said that anyway?
Never mind, it doesn’t matter. Yet ‘Naming Conventions’ do matter! Any development team worth its salt knows this and makes a practice of it. Regardless of when, what, and how Talend object names are applied, consistency is again central to any reasonable success. Conventions of Object Naming in Talend should be clearly stated in your “Development Guidelines” document and adopted by the entire team for optimum cooperation and collaboration (do you see a pattern formulating here?).
Project Repository
When you open your project with the Talend Studio (the Eclipse IDE: Integrated Development Environment, or simply: your job editor) the left panel represents the Project Repository. This is where all your project objects reside. There are several very important sections here. You should of course know about the ‘Job Designs’ sections which has been enhanced in v6.1.1 to accommodate the 3 different types of job you can create (data integration; batch; streaming), but there are other sections you should know and utilize.
- Context Groups - instead of creating built-in job context variables, create them in a Context Group in the repository and re-use them across jobs (and projects when included in a reference project); Align the groups effectively; best practice is to create groups for your different environments: SBX/DEV/TEST/UAT/PROD where DEV is the default; remove the existing ‘default’ context;

Notice I’ve added a context variable ‘SysENVTYPE’ that contains the value for dynamic programmability within a selected environment. In other words, I use this variable within a job to determine at runtime which environment is currently running so I can programmatically alter my flow using conditional logic.
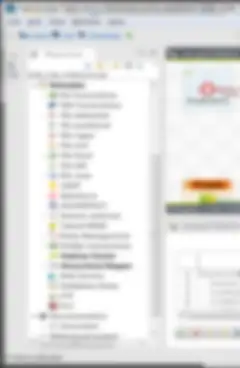
- Metadata - metadata comes in different forms; use them all! DB connections and their table schemas, flat file layouts of all sorts (.csv; .xml; .json; and more); plus the always useful Generic Schema which can be used in so many ways I can’t even begin to list them or this blog would never end
- Documentation - generate your own project Wiki and publish it to the team; this feature will produce a full set of html files about your project which can be easily navigated; such a useful thing, and it takes only a few minutes
Yes, include some Best Practices for your team in your “Development Guidelines” document and stick with it. Adjust as needed, but get everyone on the team involved.
Version Control (Branching & Tagging)
You may have noticed that each job properties tab has a place to set ‘M’ajor and ‘m’inor version numbering schemes. Additionally you can set a status of your own creation where the default possibilities include ‘development’, ‘test’, and ‘production’. WARNING: these are designed for the single developer (TOS: Talend Open Studio) who does not have the benefit of cooperative development and source code control (SCC) in SVN/GIT repositories. What you need to know is that every time you bump these internal job properties a full copy of the job is made in your local workspace and sync’d with the SCC system. I’ve seen some projects where copies of jobs were made after more than a dozen internal version bumps. ALL copies of that job are copied thus resulting in a mushrooming effect of subordinate files which all are sync’d with the SCC. This can bulk down the project and cause severe performance problems when opening and closing a project. If you are experiencing this you’ll need to clean out your workspace with an export and fresh import of only the top version of the job. Yes a chore, but worth it.
So instead, the best practice for version control in all paid subscription environments is to use the native SCC branching and tagging mechanisms. This is always the best way to manage project version releases as the SCC only maintains the delta information for each job save. This has a dramatic effect in the reduction of space required for a particular job’s history. Devise a versioning scheme using numbers, dates, or something useful, detail it in the “Development Guidelines” document and have the entire team adopt the process (you get the drill!).
Memory Management
So you want to run your job? Did you consider its memory needs? Is the data flow processing millions of rows and/or have many columns, and/or many lookups in the tMap? Did you consider when the job runs on the ‘Job Server’ that other jobs might be running simultaneously? Did you think about how many cores/ram that ‘Job Server’ has? How did you configure the tMap joins; ‘Load Once’ or ‘Row by row’? Does your job call child jobs or is your job called by a parent job, and how many levels of nested jobs are involved? Are the child jobs run in a separate JVM? If writing ESB jobs, do you know how many routes are being created? Are you using parallelization (see below) techniques? Well? Did you consider these? Huh? Bet not …
Default settings are meant to provide base values for configurable settings. Jobs have several, including the allocation of memory. But defaults are not always right, in fact they are likely wrong. Your ‘Use Case Job Design’, your ‘Operational Ecosystem’, and your ‘Real Time JVM Thread Count’ determine how much memory is utilized. This needs to be managed.

You can specify the JVM memory settings at a project level or for specific jobs (as above):
Preferences > Talend > Run
Get this right or suffer the pain! Memory management is often overlooked and as a team, both developmentally and operationally, guidelines should be well documented and followed. ~ Do you finally want to read that 1st blog now?
Dynamic SQL Syntax
Many of the database input components require proper SQL syntax to be included in its ‘Basic Settings’ tab. Of course one can simply enter the syntax directly in the tMyDBInput component, and that is OK; yet consider the requirement that when a complex SQL query needs to be dynamically constructed at runtime based upon some mitigating logic under the control of the job, or its parent job, an approach to this problem is fairly straight forward. Create ‘Context Variables’ for the basic constructs of the SQL query, set them in the job flow prior to arriving at the tMyDBInput component and then use the context variable in place of a hard coded query.
For example, I’ve developed a ‘Context Group’ in a ‘Referenced’ project repository that I call ‘SystemVARS’ which contain a variety of useful, and reusable variables. For the Dynamic SQL paradigm I define the following ‘String’ variables initialized to ‘null’:

I setup these variables in a tJava component as appropriate to my needs, and then stitch them together into the tMyDBInput query field, like this:
“SELECT “ + Context.sqlCOLUMNS + Context.sqlFROM + Context.sqlWHERE
Note that I always include a ‘Space’ at the end of the variable value so concatenation is clean. Where further control is needed, I utilize a ‘sqlSYNTAX’ variable as well and conditionally control how I concatenate the clauses of the SQL syntax and simply place the Context.sqlSYNTAX into the tMyDBInput query field instead. Voila! Ok, it’s not Dynamic SQL from the database host perspective, but it is dynamically generated SQL for your job!
All together now: document this guideline and everybody agree to do it the same way!
Parallization Options
Talend offers several mechanisms that enable code parallization. Used correctly, efficiently, and with serious consideration for the potential impact to CPU core and RAM utilization, highly performing job design patterns can be created. Let’s take a look at the option stack:
- Execution Plan - multiple job/tasks can be configured to run in parallel from the TAC
- Multiple Job Flows - multiple data flows can be fired up within a single job all sharing the same thread; when no dependencies exist between them this can be a technique for rare use case scenarios; generally I avoid doing this; I’d rather create separate jobs
- Parent/Child Jobs - when calling a child job with the tRunJob component you may check the ‘Use an independent process to run subjob‘ box which will establish a separate JVM heap/thread to run the child job in; while this is not exactly parallelization it factors in
- Components - the tParallelize component links multiple data flows for execution; the tPartitioner, tDepartitioner, tCollector, and tRecollector components offer direct control over the number of parallel threads for a data flow
- DB Components - most DB Input/Output components offer an advanced setting to enable parallelization thread counts on specific SQL statements; these can be highly efficient but setting the number too high can have the opposite effect; 2-5 is a best practice
It is possible to utilize all these parallelization methods in conjunction with each other, nested as it were, yet caution is advised; know your memory utilization stack! Be very aware of how the job design pattern execution flows. Note that these parallelization options are only available in the Talend Platform offerings as an advanced feature. Make sure to exclude any parallization guidelines from your document: NOT!
The Secret to Successful Talend Jobs
Hopefully these best practices for job design patterns will influence your thinking about the best way to create Talend jobs. Fundamentally building successful jobs is about having guidelines, discipline, and consistency. One simply has to decide to do it and follow through. As we paint our code onto the canvas of data/workflows, remember:
“Action is the foundational key to all success!”- Pablo Picasso
Finally, I submit to you an enumeration of Do’s and Don’ts that provide, what I believe to be the secrets to building successful Talend Jobs:
- - Do Use Both The tPreJob & tPostJob Components
- - Do Not Clutter Canvas With Tightly Grouped Components; Spread it out a bit
- - Do Layout Your Code Nicely; Top-2-Bottom & Left-2-Right
- - Do Not Expect To Get It Just Right The 1st Time You Code It
- - Do Identify Your Main Job Loop & Control Your Exit
- - Do Not Ignore Error Handling Techniques
- - Do Use Context Groups Extensively (DEV/QA/UAT/PROD) & Wisely
- - Do Not Create Massive Single Job Layouts
- - Do Create Atomic Job Modules
- - Do Not Force Complexity; Simplify
- - Do Use Generic Schemas Everywhere (arguable exception is the single column schema)
- - Do Not Forget To Name Your Objects
- - Do Use Joblets Where Appropriate (there may only be a few)
- - Do Not Over utilize The tJavaFlex Component; tJava or tJavaRow is likely enough
- - Do Generate/Publish The Project Documentation When Done
- - Do Not Skip Setting The Runtime Memory Heap
Conclusion
Whew! ~ is that enough? Did you get your fill? I hope not, because I am planning more blogs in this series: “Sample Use Cases”! Today’s blog
has extended the fundamentals and introduced some advanced concepts for your respected consideration. Hopefully you find them useful. Please feel free to leave comments on some Best Practices you follow and make this more of a conversation than a diatribe! Until next time, Cheers…
Related Resources
Introduction to Talend Open Studio for Data Integration
Products Mentioned

More related articles
- What are Data Silos?
- What is Data Extraction? Definition and Examples
- What is Customer Data Integration (CDI)?
- Talend Job Design Patterns and Best Practices: Part 4
- Talend Job Design Patterns and Best Practices: Part 3
- What is Data Migration?
- What is Data Mapping?
- What is Database Integration?
- What is Data Integration?
- Understanding Data Migration: Strategy and Best Practices
- Talend Job Design Patterns and Best Practices: Part 1
- What is change data capture?
- Experience the magic of shuffling columns in Talend Dynamic Schema
- Day-in-the-Life of a Data Integration Developer: How to Build Your First Talend Job
- Overcoming Healthcare’s Data Integration Challenges
- An Informatica PowerCenter Developers’ Guide to Talend: Part 3
- An Informatica PowerCenter Developers’ Guide to Talend: Part 2
- 5 Data Integration Methods and Strategies
- An Informatica PowerCenter Developers' Guide to Talend: Part 1
- Best Practices for Using Context Variables with Talend: Part 2
- Best Practices for Using Context Variables with Talend: Part 3
- Best Practices for Using Context Variables with Talend: Part 4
- Best Practices for Using Context Variables with Talend: Part 1