What it is, why it matters, and best practices. This guide provides definitions and practical advice to help you understand and establish modern change data capture.
Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real-time to a downstream process or system.
Why it Matters
Capturing every change from transactions in a source database and moving them to the target in real-time keeps the systems in sync and provides for reliable data replication and zero-downtime cloud migrations.
CDC is perfect for modern cloud architectures since it’s a highly efficient way to move data across a wide area network. And, since it’s moving data in real-time, it also supports real-time analytics and data science.
This 2-minute video shows how change data capture works and why it’s rapidly becoming the preferred method for data ingestion and movement.
Change Data Capture in ETL
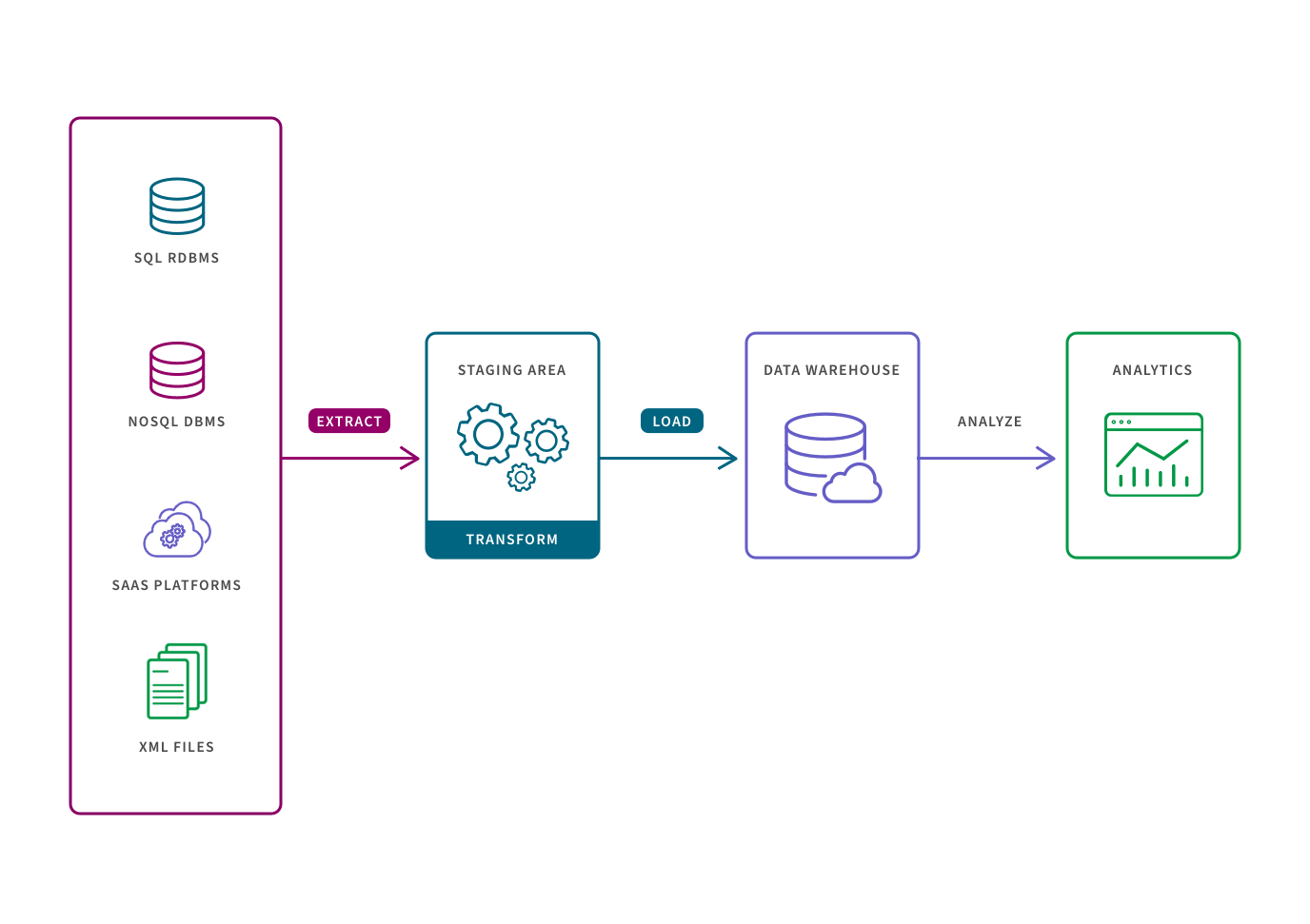
Change data capture is a method of ETL (Extract, Transform, Load) where data is extracted from a source, transformed, and then loaded to a target repository such as a data lake or data warehouse. Let’s walk through each step of the ETL pipeline.
Extract. Historically, data would be extracted in bulk using batch-based database queries. The challenge comes as data in the source tables is continuously updated. Completely refreshing a replica of the source data is not suitable and therefore these updates are not reliably reflected in the target repository.
Change data capture solves for this challenge, extracting data in a real-time or near-real-time manner and providing you a reliable stream of change data.
Transformation. Typically, ETL tools transform data in a staging area before loading. This involves converting a data set’s structure and format to match the target repository, typically a traditional data warehouse. Given the constraints of these warehouses, the entire data set must be transformed before loading, so transforming large data sets can be time intensive.
Today’s datasets are too large and timeliness is too important for this approach. In the more modern ELT pipeline (Extract, Load, Transform), data is loaded immediately and then transformed in the target system, typically a cloud-based data warehouse, data lake, or data lakehouse. ELT operates either on a micro-batch timescale, only loading the data modified since the last successful load, or CDC timescale which continually loads data as it changes at the source.
Load. This phase refers to the process of placing the data into the target system, where it can be analyzed by BI or analytics tools.
Streaming Change Data Capture
Learn how to modernize your data and analytics environment with scalable, efficient and real-time data replication that does not impact production systems.
There are many use cases for CDC in your overall data integration strategy. You may be moving data into a data warehouse or data lake, creating an operational data store or a replica of the source data in real-time. Or even implementing a modern data fabric architecture. Ultimately, CDC will help your organization obtain greater value from your data by allowing you to integrate and analyze data faster—and use fewer system resources in the process. Here are some key benefits:
Eliminates the need for bulk load updating and inconvenient batch windows by enabling incremental loading or real-time streaming of data changes into your target repository. Log-based CDC is a highly efficient approach for limiting impact on the source extract when loading new data.
Since CDC moves data in real-time, it facilitates zero-downtime database migrations and supports real-time analytics, fraud protection, and synchronizing data across geographically distributed systems.
CDC is a very efficient way to move data across a wide area network, so it’s perfect for the cloud.
Change data capture is also well suited for moving data into a stream processing solution like Apache Kafka.
CDC ensures that data in multiple systems stays in sync. This is especially important if you're making time-sensitive decisions in a high-velocity data environment.
Change Data Capture Methods
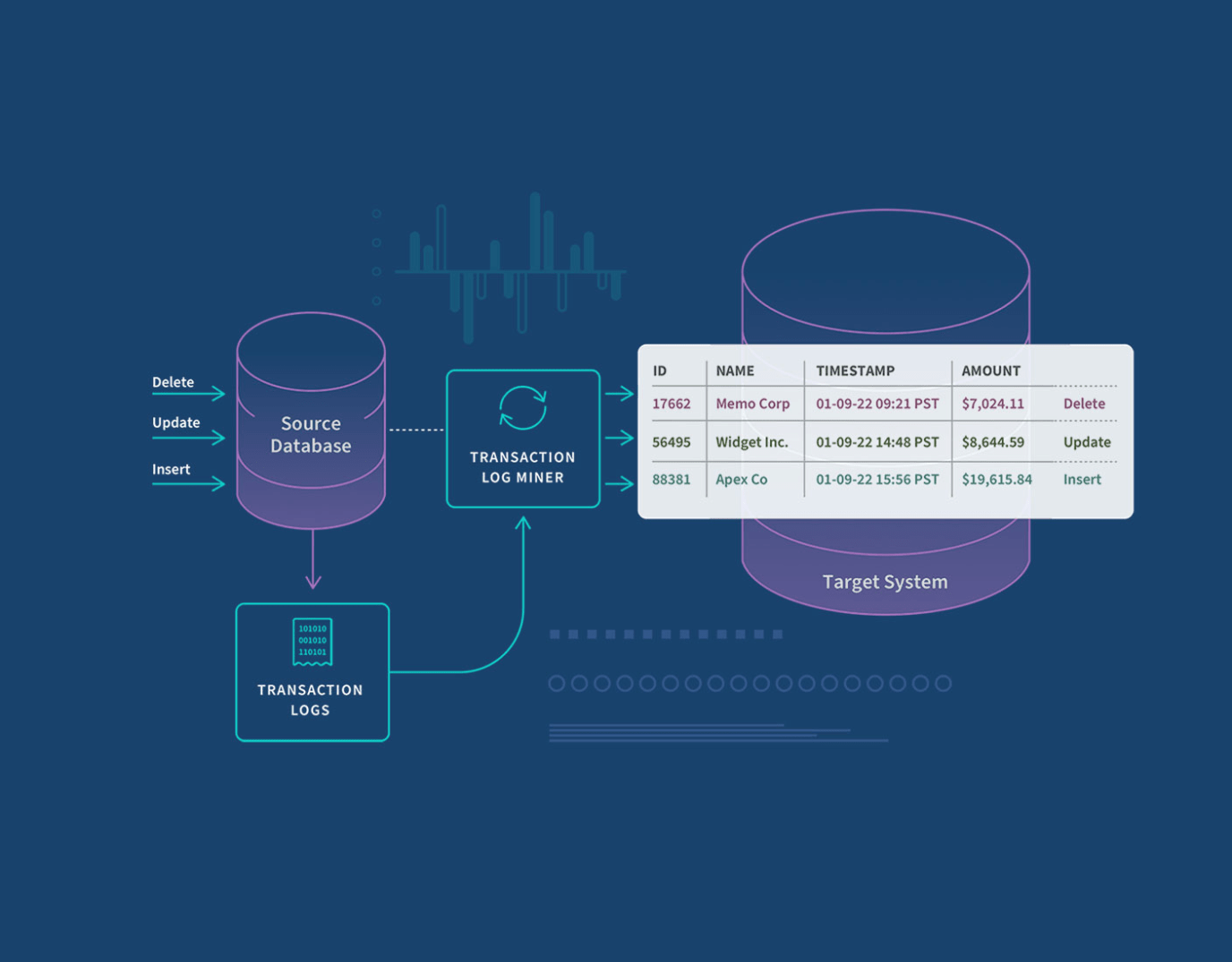
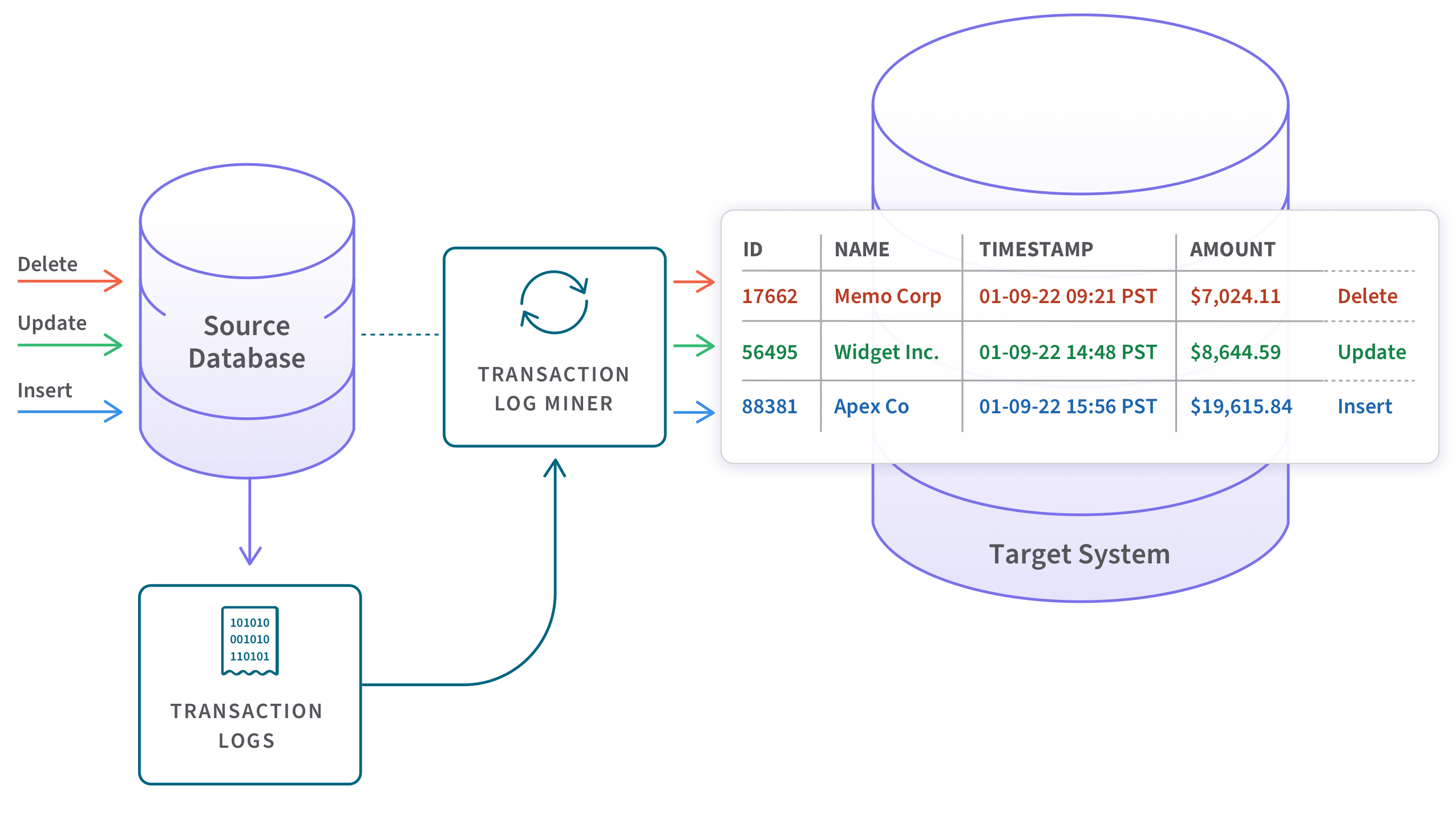
There are a few ways to implement a change data capture system. Before built-in features were introduced for CDC in SQL Server, Oracle, and a few other databases, developers and DBAs utilized techniques such as table differencing, change-value selection, and database triggers to capture changes made to a database. These methods, however, can be inefficient or intrusive and tend to place substantial overhead on source servers. This is why DBAs quickly embraced embedded CDC features which are log-based such as Oracle CDC. These features utilize a background process to scan database transaction logs in order to capture changed data. Therefore, transactions are unaffected, and the performance impact on source servers is minimized.
The most popular method is to use a transaction log which records changes made to the database data and metadata. Here we discuss the three primary approaches.
Log-based CDC. This is the most efficient way to implement CDC. When a new transaction comes into a database, it gets logged into a log file with no impact on the source system. And you can pick up those changes and then move those changes from the log.
Query-based CDC. Here you query the data in the source to pick up changes. This approach is more invasive to the source systems because you need something like a timestamp in the data itself.
Trigger-based CDC. In this approach, you change the source application to trigger the write to a change table and then move it. This approach reduces database performance because it requires multiple writes each time a row is updated, inserted, or deleted.
Change Data Capture 101: What Works Best and Why
Modern data analytics have the potential to reinvent your business. But to take advantage, IT has to reinvent how they move, store and process data. And integration is a big challenge.
Few database vendors provide embedded CDC or change data capture technology. And, even when they do, the technology is generally not suitable for capturing data changes from other types of source systems. This means IT teams must learn, configure, and monitor separate CDC tools for each type of database system in use at their organization.
The newest generation of log-based CDC tools are fully integrated. They offer high-performance data ingestion capabilities which work seamlessly with most ETL tools and a wide variety of source and target systems such as CDC for Oracle and SQL Server CDC. They can also replicate data to targets such as Snowflake and Azure. This lets you leverage one tool for all of your real-time data integration and data warehousing needs.
This quick video describes how these tools accelerate data replication, ingestion and streaming across a wide variety of heterogeneous databases, data warehouses, and big data platforms.