An Informatica PowerCenter Developers’ Guide to Talend: Part 2
Thanks to all our readers for a very positive response to my previous blog on “Informatica PowerCenter Developers Guide to Talend”. The first part of the series provided an overview of the architectural differences between PowerCenter and Talend. It also provided a primer on Talend Studio – our unified development environment – for developers transitioning over from legacy PowerCenter tools.
In the second part of the series, I’d like to dive a bit deeper into the internals of Talend’s code-generation process and why it is important to become a more effective and productive Talend developer. I will also provide a mapping of some of the most commonly used Informatica transformations to the equivalent Talend components.
Talend vs. Informatica PowerCenter: Processing Details
If you are familiar with the details of PowerCenter’s multi-threaded execution engine, you will know that every session is an operating system process with (at least) three threads – reader, transform and writer. From a memory allocation standpoint, the session is allocated a certain amount of memory (“DTM Buffer Size”) when the process starts up. Cache-based transformations have additional memory allocated to them.
Memory allocation and multi-threading works differently with Talend and, as a developer, you need to be aware of these differences. Every Talend job is a process running within JVM and has a certain amount of memory allocated to it (Fig 1 shows how to configure it). This memory is shared across all subjobs and components that are part of the job.
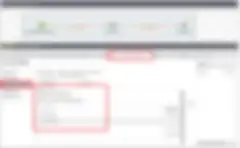
Figure 1
Every subjob when implemented as a data flow, is executed as a loop over a data set. The Talend generated code reads one row at a time from the first source component; processes that row through every component that is part of the subjob; writes the row to the target and goes back to the source component to get the next row. After the code has looped through all the rows in the source, the thread exits the subjob.
Here’s an example (Figure 2). The subjob reads data from a CSV file that has two columns (FirstName, LastName) and five rows. The tLogRow_1 component writes both columns to the console. The tLogRow_2 component writes only the FirstName column to the console. Notice the output in the console – the entries alternate between the outputs of tLogRow_1 and tLogRow_2.

Figure 2
Iteration and Blocking Components
In the example above, we dissected a very simple subjob and understood that the data is processed end- to-end, one row at a time. However, there are a couple of exceptions to this:
1. When an Iterate loop is implemented in the subjob
In this situation, all rows in the component you are iterating through are read before control is passed to the next component. Once the iteration over all rows has been completed, the code for downstream components is executed one row at a time (just like the previous example).
Here’s an example of how an iteration works in Talend - https://help.talend.com/access/sources/content/topic?pageid=tpw1550478454088&afs:lang=en&EnrichVersion=7.3
2. If there is a “Blocking” component in the code
Let’s define a “Blocking” component as one that requires a batch of rows (instead of one row at a time) to complete processing e.g. When you need to sort all the rows from an input using the tSortRow component, it will read all the rows and store it in memory before starting the sorting process and sending the output to the next component. Components like tSortRow “block” the rows from moving forward until the sort (or some other process) is complete. To illustrate this (see Figure 3), I have modified the previous example by introducing a tSortRow component between the two tLogRows in the subjob. Unlike the previous example, where we noticed outputs from tLogRow_1 and tLogRow_2 appear on alternate rows, in this example we see the output of tLogRow_2 appear only after all the rows from tLogRow_1 have been sorted by the tSortRow_1.
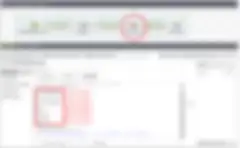
For jobs that have an iterate loop or a blocking component, one needs to be aware of the memory requirements for the job (e.g. if you are iterating over thousands of large input files or are sorting millions of rows or rows with many columns, you need to adjust the memory settings of the job to avoid runtime errors).
One of the first questions that I ask myself when I drop a component into the Studio canvas is – “Is this a blocking component?”. This helps me determine if I must tweak the memory required for the job. I highly recommend that you adopt the same approach to your job design.
From Informatica Transformations to Talend Components
In the second part of this blog, let’s map some of the most popular PowerCenter transformations to the equivalent Talend components:
|
Informatica |
Talend Studio |
Description |
|
Source Qualifier |
t<RDBMS>Input tFileInput<FileFormat> |
Instead of having a generic source qualifier component that supports all databases/files, Talend has database/file format specific components e.g. tMySQLInput is a source qualifier for a MySQL database and tFileInputDelimited helps ingests delimited files. |
|
Expression |
tMap |
tMap is one of the most frequently used components and the workhorse of data processing. It maps the input columns to the output columns and supports a variety of transformation functions. |
|
Filter |
tFilterRow |
You can set one or more filter conditions on selected columns to filter out the rows. |
|
Joiner |
tMap |
tMap joins two or more tables by doing a join on one or more columns. |
|
Lookup |
tMap |
tMap allows you to have multiple lookup tables in the same map. It supports Cached and Un-cached lookups (“Lookup Model”) and storing lookups on disk (“Store temp data”). It also allows you to override the SQL query generated by the tMap lookup. |
|
Sorter |
tSortRow |
Sorts data based on one or several columns, by sort type and order |
|
Aggregator |
tAggregateRow tAggregateSortedRow |
If your data set is sorted, you can use tAggregateSortedRow to improve performance |
|
Union |
tUnite |
Merges data from multiple sources based on a common schema |
|
Router |
tMap tReplicate |
If you just want to send the same row to multiple destinations, you can use tReplicate. For more complex logic, use tMap instead. |
|
Stored Procedure |
t<RDBMS>SP tJDBCSP |
These are database specific components e.g. if you want to call an Oracle stored procedure, you can use tOracleSP. If there is no native SP component for your database, you can use tJDBCSP |
|
Sequence Generator |
Code Routines |
Use the numeric routine called sequence in any Java expression to generate a sequence. |
|
Update Strategy |
t<RDBMS>Output |
Use the appropriate value for “Action on Data” in the t<RDBMS>Output component to implement your update strategy. |
You can find more details about these components in the Talend Components Reference Guide. Talend currently has 900+ components and connectors that help our users design and develop their data integration jobs much faster. And because we have our origins as an open source product, our users create connectors and components to share freely on the Talend Exchange.
For more detailed discussion on process design, setting up memory, and other architectural guidelines, please read the four part series on Talend Job Design Patterns and Best Practices – Part 1, Part 2, Part 3 and Part 4.
Conclusion
Like I have stated earlier, it is important to understand the differences between PowerCenter and Talend, how Talend works and the best practices around it, so that you can deliver incredible value to your organization or clients by leveraging Talend as a data integration platform.
← Part 1 | Part 3 →

More related articles
- What are Data Silos?
- What is Data Extraction? Definition and Examples
- What is Customer Data Integration (CDI)?
- Talend Job Design Patterns and Best Practices: Part 4
- Talend Job Design Patterns and Best Practices: Part 3
- What is Data Migration?
- What is Data Mapping?
- What is Database Integration?
- What is Data Integration?
- Understanding Data Migration: Strategy and Best Practices
- Talend Job Design Patterns and Best Practices: Part 2
- Talend Job Design Patterns and Best Practices: Part 1
- What is change data capture?
- Experience the magic of shuffling columns in Talend Dynamic Schema
- Day-in-the-Life of a Data Integration Developer: How to Build Your First Talend Job
- Overcoming Healthcare’s Data Integration Challenges
- An Informatica PowerCenter Developers’ Guide to Talend: Part 3
- 5 Data Integration Methods and Strategies
- An Informatica PowerCenter Developers' Guide to Talend: Part 1
- Best Practices for Using Context Variables with Talend: Part 2
- Best Practices for Using Context Variables with Talend: Part 3
- Best Practices for Using Context Variables with Talend: Part 4
- Best Practices for Using Context Variables with Talend: Part 1