Talend Job Design Patterns and Best Practices: Part 3
It appears that my previous blogs on this topic have been very well received. Let me express my continued delight and thanks to you, my (dedicated or avid) readers.
If you new here and haven’t read any of my previous posts, please start by reading these first (Talend “Job Design Patterns” & Best Practices Part 1 & Part 2) and then come back to read more; they all build upon a theme. The popularity of this series has in fact necessitated translations, and if you are so inclined, please read the new French versions (simply click on the French Flag). Thanks go out to Gaël Peglissco, ‘Chef de Projets’ of Makina Corpus for his persistence, patience, and professionalism in helping us get these translations crafted and published.
Before I dive in on more Job Design Patterns and best practices, please note that the previous content has been encapsulated into a 90-minute technical presentation. This presentation is being delivered at ‘Talend Technical Boot Camps’ popping up on my calendar across the globe. Please check the Talend Website for an upcoming event in your area. I’d love to see you there!
As we continue on this journey, please feel free to comment, question, and/or debate my guidance as expanding the discussion out to the Talend Community is, in fact, my ‘not-so-obvious’ end-game. ‘Guidelines,’ not ‘Standards,’ remember? Is it fair for me to expect that you may have contributions and opinions to share; am I right? I do hope so…
Building upon a Theme
By now it should be clear that I believe establishing ‘Developer Guidelines’ are essential to the success of any software life cycle, including Talend projects; but let’s be very sure: Establishing developer guidelines, attaining team adoption, and instilling discipline incrementally are the keys to delivering exceptional results with Talend. LOL; I hope you all agree! Building Talend jobs can take many turns and twists (and I am not talking about the new curvy lines), so understanding the foundation of “Business Use Case”, “Technology”, and “Methodology” dramatically improves your odds of doing it right. I believe that taking time to craft your teams’ guidelines is well worth the effort; I know that you’ll be glad you did!
Many Use Cases challenging Talend customers are usually wrapped around some form of data integration process; Talend’s core competency; moving data from one place to another. Data flow comes in many forms and what we do with it and how we manipulate it, matters. It matters so much that it becomes the essence of almost every job we create. So if moving business data is the use case, and Talend is integral to the technology stack, what is the methodology? It is, of course, the SDLC Best Practice we’ve already discussed. However, it is more than that. Methodologies, in context with data, encompass Data Modeling! A topic I get very passionate about. I’ve been a database architect for over 25 years and have designed and built more database solutions than I can count, so it’s a practical matter to me that Database Systems have a life cycle too! Irrespective of flat-file, EDI, OLTP, OLAP, STAR, Snowflake, or Data Vault schemas, ignoring the cradle-to-grave process for data and their corresponding schemas is at best an Achilles-heal, at worst – disaster!
While Data Modeling Methodologies are not the subject of this blog, adopting appropriate data structural design and utilization is highly important. Take a look at my blog series on Data Vault and watch for upcoming blogs on Data Modeling. We’ll just need to take it at face value for now, but DDLC, ‘Data Development Life Cycle’ is a Best Practice! Think about it; you may discover that I’m on to something.
More Job Design Best Practices
Ok, time to present you with some more ‘Best Practices’ for Talend Job Designs. We’ve covered 16 so far. Here are eight more (and I am sure there is likely going to be a Part 4 in this series, as I find I am unable to get to everything in here and keep the blog somewhat digestible). Enjoy!
Eight more Best Practices to consider:
Code Routines
On occasion, Talend components just don’t satisfy a particular programmatical need. That’s Ok; Talend is a Java Code Generator, right? Sure it is, and there are even Java components available you can place on your canvas to incorporate pure-java into the process and/or data flow. But what happens if even that is not enough? Let me introduce you to my little friend: Code Routines! Actual Java methods you can add to your project repository. Essentially user defined java functions you code and utilized in various places throughout your job.
Talend provides many java functions you’ve probably already utilized; like:
- getCurrentDate()
- sequence(String seqName, int startValue, int step)
- ISNULL(object variable)
There are many things you can do with code routines when you consider the big picture of your job, project, and use case. Reusable code is my mantra here and whenever you can craft a useful code routine that helps streamline a job in a generic way you’re doing something right. Make sure you incorporate proper comments as they show up when selecting the function as ‘helper’ text.

Repository Schemas
The Metadata section of the project repository provides a fortuitous opportunity to create reusable objects; a significant development guideline; Remember? Repository Schemas present a powerful technique for creating reusable objects for your jobs. This includes:

- Delimited
- Positional
- Regex
- XML
- Excel
- JSON
- Generic Schemas - used for mapping a variety of record structures
- WDSL Schemas - used for mapping Web Service method structures
- LDAP Schemas - used for mapping an LDAP structure (LDIF also available)
- UN/EDIFACT - used for mapping a wide variety of EDI transaction structures
When you create a schema you give it an object name, purpose, and description, plus a metadata object name which is referenced in job code. By default this is called ‘metadata’; take time to define a naming convention for these objects or everything in your code appears to have the same name. Perhaps ‘md_{objectname}’ is sensible. Take a look at the example.
Generic schemas are of particular importance as this is where you create data structures that focus on particular needs. Take as an example a Db Connection (as seen in the same example) which has reverse engineered table schemas from a physical database connection. The ‘accounts’ table has 12 columns, yet a matching generic schema defined below has 16 columns. The extra columns account for added value elements to the ‘accounts’ table and used in a job data flow process to incorporate additional data. In reverse, perhaps a database table has over 100 columns and for a particular job data flow only ten are needed. A generic schema can be defined for the ten columns for a query against the table with the matching ten columns; A very useful capability. My advice: Use Generic Schemas - A LOT; except for maybe 1 column structures; makes sense to me to simply make them built-in.
Note that other connection types like SAP, Salesforce, NoSQL, and Hadoop clusters all have the ability to contain schema definitions too.
Log4J
Apache Log4J has been available since Talend v6.0.1 and provides a robust Java logging framework. All Talend components now fully support Log4J services enhancing the error handling methodology discussed in my previous blogs. I am sure you’ve all now incorporated those best practices into your projects; at least I hope you have. Now enhance them with Log4J!
To utilize Log4J it must be enabled. Do this in the project properties section. There, you can also adapt your teams logging guidelines to provide a consistent messaging paradigm for the Console (stderr/stdout) and LogStash appenders. Having this single location to define these appenders provides a simple way to incorporate Log4J functionality in Talend Jobs. Notice that the level values incorporated in the Log4J syntax match up with the already familiar priorities of INFO/WARN/ERROR/FATAL.
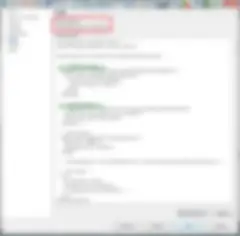
On the Talend Administrator Console (TAC) when you create a task to run a job, you can enable which level of priority Log4J will log too. Ensure that you set this appropriately for DEV/TEST & PROD environments. The best practice is to set DEV/TEST to INFO level, UAT to WARN, and PROD to ERROR. Any level above that will be included as well.

Working together with tWarn and tDie components and the new Log Server, Log4J can really enhance the monitoring and tracking of job executions. Use this feature and establish a development guideline for your team.
Activity Monitoring Console (AMC)
Talend provides an integrated add-on tool for enhanced monitoring of job execution which consolidates collected activity of detailed processing information into a database. A Graphical interface is included; accessed from the Studio and the TAC. This facility helps developers and administrators understand component and job interactions; prevent unexpected faults, and support important system management decisions. But you need to install the AMC database and web app; it is an optional feature. The Talend Activity Monitoring Console User Guide provides details on the AMC component installation, so I’ll not bore you all here with that. Let’s focus on the best practices for its use.

The AMC database contains three tables which include:
- tLogCatcher - captures data sent from Java exceptions or the tWarn/tDie components
- tStatCatcher - captures data sent from tStatCatcher Statistics check box on individual components
- tFlowMeterCatcher - captures data sent from the tFlowMeter component
These tables store the data for the AMC UI which provides a robust visualization of a job’s activity based on this data. Make sure to choose the proper log priority settings on the project preferences tab and consider carefully any data restrictions placed on job executions for each environment, DEV/TEST/PROD. Use the Main Chart view to help identify and analyze bottlenecks in the job design before pushing a release into PROD environments. Review the Error Report view to analyze the proportion of errors occurring for a specified timeframe.

While quite useful this is not the only use for these tables. As they are indeed tables in a database, SQL queries can be written to pull valuable information externally. Setup with scripting tools it is possible to craft automated queries and notifications when certain conditions occur and are logged in the AMC database. Using an established return code technique as described in my 1st blog on Job Design Patterns, these queries can programmatically perform automated operations that can prove themselves quite useful.
Recovery Checkpoints
So you have a long running job? Perhaps it involves several critical steps and if any particular step fails, starting over can become very problematic. It would certainly be nice to minimize the effort and time needed to restart the job at a specified point in the job flow just before an error has occurred. Well, the TAC provides a specialized execution restoration facility when a job encounters errors. Placed strategically and with forethought, jobs designed with these ‘recovery checkpoints’ can pick up execution without starting over and continue processing.

When a failure occurs, use the TAC ‘Error Recovery Management’ tab to determine the error and there you can launch the job for continued processing; Great stuff, right?

Joblets
We’ve discussed what Joblets are; reusable job code that can be ‘included’ in a job or many jobs as needed, but what are they really? In fact, there are not many use cases for Joblets however when you find one, use it; it is likely a gem. There are different ways you can construct and use Joblets. Let’s take a look, shall we?
When you create a new Joblet, Input/Output components are automatically added to your canvas. This jumpstart allows you to assign the schemas coming in from and going out to the job workflow utilizing the Joblet. This typical use of Joblets provide for the passing of data through the Joblet and what you do inside it is up to you. In the following example, a row is passed in, and a database table is updated, logged to stdout, and then passing the same row unchanged (in this case), out.

The non-typical use can either remove the input, the output, or both components to provide special case data/process flow handling. In the following example, nothing is passed in or out of this Joblet. Instead, a tLogCatcher component watches for various selected exceptions for subsequent processing (you’ve seen this before on error handling best practices).
Clearly using Joblets can dramatically enhance code reusability which is why they are there. Place these gems in a Reference Project to expand their use across projects. Now you’ve got something useful.
Component Test Cases
Well if you are still using a release of Talend prior to v6.0.1 then you can ignore this. LOL, or simply upgrade! One of my favorite new features is the ability to create test cases in a job. Now these are not exactly ‘unit tests’ however they are component tests; actual jobs tied into the parent job, and specifically the component it is testing. Not all components support test cases, yet where a component takes a data flow input and pushes it out, then a test case is possible.
To create a component test case, simply right click the selected component and find the menu option at the bottom ‘create test case’. After selecting this option, a new job is generated and will open up presenting a functional template for the test case. The component under test is there along with built-in INPUT and OUTPUT components wrapped up by a data flow that simply reads an ‘Input File’, processes the data from it and passing the records into the component under test, which then does what it does and writes out the result to a new ‘Result File’. Once completed that file is compared with an expected result, or ‘Reference File’. It either matches or not: Pass or Fail! - Simple right? Well let’s take a look, shall we?
Here is a job we’ve seen before; it has a tJavaFlex component that manipulates the data flow passing it downstream for further processing.

A Test Case job has been created which looks like this: No modifications are required (but I did cleanup the canvas a bit.
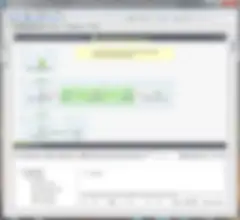
It is important to know that while you can modify the test case job code, changing the component under test should only occur in the parent job. Say for instance the schema needs to be changed. Change it in the parent job (or repository) and the test case will inherit the change. They are inextricably connected and therefore coupled by its schema.
Note that once a test case ‘instance’ is created, multiple ‘input’ and ‘reference’ files can be created to run through the same test case job. This enables testing of good, bad, small, large, and/or specialized test data. The recommendation here is to evaluate carefullynot only what to test but also what test data to use.
Finally, when the Nexus Artifact Repository is utilized, and test case jobs are stored there along with their parent job, it is possible to use tools like Jenkins to automate the execution of these tests, and thus the determination of whether a job is ready to promote intothe next environment.
Data Flow ‘Iterations’
Surely you have noticed having done any Talend code development that you link components together with a ‘trigger’ process or a ‘row’ data flow connector. By right clicking on the starting component and connecting the link ‘line’ to the next component you establish this linkage. Process Flow links are either ‘OnSubJobOk/ERROR’, ‘OnComponentOK/ERROR’, or ‘RunIF’ and we covered these in my previous blog. The Data Flow links, when connected are dynamically named ‘row{x}’ where ‘x’, a number, is assigned dynamically by Talend to create a unique object/row name. These data flow links can have custom names of course (a naming convention best practice), but establishing this link essentially maps the data schema from one component to the other and represents the ‘pipeline’ through which data is passed. At runtime data passed over this linkage is often referred to as a dataset. Depending upon downstream components the complete dataset is processed end-to-end within the encapsulated sub job.
Not all dataset processing can be done all at once like this, and it is necessary sometimes to control the data flow directly. This is done through the control of ‘row-by-row’ processing, or ‘iterations.’ Review the following nonsensical code:

Notice the components tIterateToFlow and tFlowToIterate. These specialized components allow you to place control over data flow processing by allowing datasets to be iterated over, row-by-row. This ‘list-based’ processing can be quite useful when needed. Be careful however in that in many cases once you break a data flow into row-by-row iterations you may have to re-collect it back into a full dataset before processing can continue (like the tMap shown). This is due to the requirement that some components force a ‘row’ dataset flow and are unable to handle an ‘iterative’ dataset flow. Note also that t{DB}Input components offer both a ‘main’ and ‘iterate’ a data flow option on the row menu.
Take a look at the sample scenarios: Transforming data flow to a list and Transforming a list of files as a data flow found in the Talend Help Center and Component Reference Guide. These demonstrate useful explanations on how you may use this feature. Use this feature as needed and be sure to provide readable labels to describe your purpose.
Conclusion
Digest that! We’re almost done. Part 4 in the blog series will get to the last set of Job Design Patterns and Best Practices that assure the foundation for building good Talend code. But I have promised to discuss “Sample Use Cases”, and I will. I think getting all these best practices under your belt will serve well when we start talking about abstract applications of them. As always, I welcome all comments, questions, and/or debate. Bonsai!

More related articles
- What are Data Silos?
- What is Data Extraction? Definition and Examples
- What is Customer Data Integration (CDI)?
- Talend Job Design Patterns and Best Practices: Part 4
- What is Data Migration?
- What is Data Mapping?
- What is Database Integration?
- What is Data Integration?
- Understanding Data Migration: Strategy and Best Practices
- Talend Job Design Patterns and Best Practices: Part 2
- Talend Job Design Patterns and Best Practices: Part 1
- What is change data capture?
- Experience the magic of shuffling columns in Talend Dynamic Schema
- Day-in-the-Life of a Data Integration Developer: How to Build Your First Talend Job
- Overcoming Healthcare’s Data Integration Challenges
- An Informatica PowerCenter Developers’ Guide to Talend: Part 3
- An Informatica PowerCenter Developers’ Guide to Talend: Part 2
- 5 Data Integration Methods and Strategies
- An Informatica PowerCenter Developers' Guide to Talend: Part 1
- Best Practices for Using Context Variables with Talend: Part 2
- Best Practices for Using Context Variables with Talend: Part 3
- Best Practices for Using Context Variables with Talend: Part 4
- Best Practices for Using Context Variables with Talend: Part 1