"Job Design Pattern e best practice Talend": Parte 3
A quanto pare, i miei precedenti blog su questo argomento hanno riscosso un gran successo. Ne sono veramente felice e ringrazio tutti i miei (attenti o avidi) lettori.
Se qualcuno ancora non avesse letto i miei post precedenti, consiglio di iniziare prima da quelli (Job Design Pattern e best practice Talend Parte 1 e Parte 2), quindi di passare a questo per approfondire; ogni blog si concentra su un tema differente. Vista la popolarità della serie, sono state anche fatte delle traduzioni; se vi interessa, potete leggere le nuove versioni in francese (basta fare clic sulla bandiera francese). Colgo l'occasione per ringraziare Gaël Peglissco, "Chef de Projets" di Makina Corpus, per la perseveranza, pazienza e professionalità dimostrate nell'aiutarci a realizzare e pubblicare queste traduzioni.
Prima di passare ad analizzare ulteriori Job Design Pattern e best practice, vorrei anche informarvi che i contenuti precedenti sono stati condensati in una presentazione tecnica di 90 minuti. Tale presentazione viene mostrata ai "Talend Technical Boot Camps" che si stanno tenendo in varie parti del mondo. Sul sito web di Talend è disponibile un calendario con le date e i luoghi dei prossimi eventi. Sarei felice di vedervi in occasione di uno di essi!
Mentre continuiamo il nostro viaggio, potete inviare commenti, domande e/o aprire dibattiti sulla mia guida, in quanto portare la discussione al di fuori della community Talend è, in realtà, il mio "non proprio ovvio" obiettivo. "Linee guida" non "standard", ricordate? Mi sembra lecito aspettarmi che abbiate contributi e opinioni da condividere; dico bene? Lo spero davvero…
Condivisione di un tema comune
A questo punto, dovrebbe essere chiaro che definire delle "Linee guida di sviluppo" è alla base del successo di un qualunque ciclo vitale del software, inclusi i progetti Talend; tuttavia, per essere ancora più chiari: stabilire delle linee guida di sviluppo, farle adottare dall'intero team e inculcare progressivamente disciplina sono la chiave per ottenere risultati eccezionali con Talend. Mi auguro che siate tutti d'accordo ormai! Creare job Talend può essere un percorso complicato e tortuoso (e non mi riferisco alle nuove linee curve utilizzabili per i collegamenti), di conseguenza, comprendere l'essenza di concetti quali "caso d'uso", "tecnologia" e "metodologia" migliora drasticamente le probabilità di successo. Sono convinto che valga la pena dedicare un po' di tempo alla messa a punto di linee guida per il team; sono sicuro che non vi pentirete di averlo fatto!
Molti casi d'uso che mettono in difficoltà i clienti Talend sono in genere incentrati su processi di integrazione dei dati, competenze chiave di Talend o spostamento dei dati da un luogo a un altro. I flussi di dati si manifestano in diverse forme e il modo in cui li gestiamo e li manipoliamo fa la differenza. Questo aspetto è in realtà così importante da diventare l'essenza stessa di ogni job che creiamo. Quindi, se trasferire dati aziendali rappresenta il caso d'uso e Talend è parte integrante della soluzione tecnologica adottata, quale sarà la metodologia? Sarà, ovviamente, la best practice SDLC di cui abbiamo già parlato. In realtà, è molto di più di questo. Le metodologie, nel contesto dei dati, includono l'elaborazione di Data Model. Un argomento che mi appassiona molto. Sono database architect da oltre 25 anni e ho progettato e realizzato tantissime soluzioni di database, quindi per me è naturale che anche i sistemi di database abbiano un ciclo vitale! A prescindere dal file flat, dai modelli EDI, OLTP, OLAP, STAR, Snowflake o dagli schemi di data vault, ignorare il percorso "dalla culla alla tomba" dei dati e dei relativi schemi rappresenta, nella migliore delle ipotesi, un rischio, nelle peggiori, un disastro!
Se le metodologie di Data Modeling non sono l'argomento di questo blog, è comunque estremamente importante adottare schemi di progettazione e utilizzo strutturale dei dati appropriati. Date un'occhiata alla mia serie di blog sul data vault e non perdetevi i prossimi blog sul Data Modeling. Per il momento, non ci resta che prendere questa affermazione alla lettera: il DDLC, o "ciclo vitale di sviluppo dei dati", è una best practice. Provate a pensarci; potreste scoprire che ho ragione.
Altre best practice per la progettazione di job
Ok, è ora giunto il momento di presentarvi ulteriori best practice per la progettazione di job Talend. Ne abbiamo già viste 16. Eccone altre otto (ma sono certo che a questa serie di blog verrà aggiunta una Parte 4, in quanto non credo di riuscire a esaurire l'argomento in questo blog senza renderlo eccessivamente pesante da assimilare). Buon divertimento!
Otto ulteriori best practice da prendere in considerazione:
Routine del codice
Talvolta, i componenti Talend non riescono a soddisfare una particolare esigenza di programmazione. Talend è un generatore di codice java, giusto? Proprio così. E offre anche componenti java da collocare sulla "tela" per incorporare codice java puro nel processo e/o flusso di dati. Ma cosa accade se anche questo non fosse sufficiente? Lasciate che vi presenti un'utilissima funzione: le routine del codice. Si tratta di metodi java veri e propri da aggiungere al repository dei progetti. In sostanza, sono funzioni java definite dall'utente che è possibile codificare e utilizzare in varie posizioni all'interno di un job.
Talend offre numerose funzioni java che forse già utilizzate, come:
- getCurrentDate()
- sequence(String seqName, int startValue, int step)
- ISNULL(object variable)
Sono tante le cose che si possono fare con le routine del codice, se si considera il quadro generale di job, progetti e caso d'uso. La riutilizzabilità del codice è il mio mantra e ogni volta che è possibile, è buona cosa creare un'utile routine che aiuti a semplificare un job in modo generico. Assicuratevi di incorporare commenti appropriati da visualizzare quando si seleziona la funzione come testo di aiuto.

Schemi di repository
La sezione Metadata del repository progetti offre l'opportunità di creare oggetti riutilizzabili; una linea guida di sviluppo importante, ricordate? Gli schemi di repository rappresentano un'efficace tecnica per creare oggetti riutilizzabili nei vostri job. Ecco cosa includono:

- Delimitati
- Posizionali
- Regex
- XML
- Excel
- JSON
- Schemi generici – utilizzati per la mappatura di una varietà di strutture di record
- Schemi WDSL – utilizzati per la mappatura di strutture di metodi Web Service
- Schemi LDAP – utilizzati per la mappatura di una struttura LDAP (LDIF anche disponibile)
- UN/EDIFACT – utilizzati per la mappatura di una grande varietà di strutture di transazioni EDI
Quando si crea uno schema, gli si assegna un nome oggetto, uno scopo e una descrizione, oltre a un nome oggetto dei metadati a cui si fa riferimento nel codice job. Per impostazione predefinita, il nome assegnato è "metadati"; dedicate tuttavia un po' di tempo alla definizione di una convenzione di denominazione per questi oggetti, o ogni cosa all'interno del vostro codice sembrerà avere lo stesso nome. Forse "md_{objectname}" può avere senso. Date un'occhiata all'esempio.
Gli schemi generici sono particolarmente importanti in quanto è all'interno di essi che si creano strutture di dati focalizzate su particolari esigenze. Prendiamo, ad esempio, una Db Connection (come illustrato nell'esempio) che presenta schemi di tabelle deingegnerizzati a partire da una connessione di database fisica. La tabella "accounts" presenta 12 colonne, tuttavia uno schema generico corrispondente definito di seguito presenta 16 colonne. Le colonne in eccesso rappresentano elementi di valore aggiunto integrati nella tabella "accounts" e usati in un processo di flusso di dati del job per incorporare dati aggiuntivi. Al contrario, una tabella di database può avere più di 100 colonne, quando per un particolare flusso di dati del job ne sono richieste solo dieci. È possibile definire uno schema generico per le dieci colonne ed eseguire una query all'interno della tabella per trovare le dieci colonne corrispondenti. Una funzionalità senz'altro utile. Il mio consiglio: utilizzate gli schemi generici DIFFUSAMENTE; tranne, forse, per strutture a una sola colonna dove secondo me ha più senso integrarli.
Tenete presente che anche altri tipi di connessioni come SAP, Salesforce, NoSQL e cluster Hadoop hanno la capacità di contenere definizioni di schemi.
Log4J
Apache Log4J è disponibile dalla versione 6.0.1 di Talend e fornisce un framework robusto per la registrazione java. Tutti i componenti Talend ora supportano completamente i servizi Log4J, ottimizzando la metodologia di gestione degli errori di cui ho parlato nei miei blog precedenti. Sono certo che avrete già incorporato queste best practice nei vostri progetti; o almeno me lo auguro. Ora è il momento di ottimizzarle con Log4J!
Per prima cosa è necessario abilitare Log4J. Potete farlo nella sezione delle proprietà del progetto. In questa sezione, è possibile anche adattare le linee guida di registrazione del team al fine di creare un paradigma di messaggistica coerente per la Console (stderr/stdout) e gli appender LogStash. La disponibilità di un'unica posizione dove definire tali appender offre un modo semplice per incorporare la funzionalità Log4J nei job Talend. Si noti come i valori di livello incorporati nella sintassi Log4J corrispondano alle priorità già familiari di INFO/WARN/ERROR/FATAL.
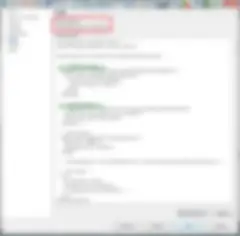
Nella Talend Administrator Console (TAC), quando si crea un'attività per eseguire un job, è possibile abilitare il livello di priorità Log4J che dovrà essere registrato. Assicuratevi di definire questa impostazione correttamente per gli ambienti DEV/TEST e PROD. La best practice consiste nell'impostare DEV/TEST sul livello INFO, UAT su WARN e PROD su ERROR. Qualunque livello superiore verrà incluso.

Operando insieme ai componenti tWarn e tDie, e con il nuovo Log Server, Log4J può veramente migliorare il monitoraggio e la tracciabilità dell'esecuzione dei job. Usate questa funzione e stabilite una linea guida di sviluppo per il team.
Activity Monitoring Console (AMC)
Talend offre un componente aggiuntivo integrato per ottimizzare il monitoraggio dell'esecuzione dei job, che consolida l'attività di raccolta di informazioni dettagliate sull'elaborazione in un database. È inclusa un'interfaccia grafica, accessibile da Studio e dalla TAC. Questo strumento aiuta gli sviluppatori e gli amministratori a comprendere le interazioni tra componenti e job, a prevenire errori inattesi e a supportare importanti decisioni sulla gestione del sistema. Ma è necessario installare il database AMC e l'app web, in quanto si tratta di una funzionalità opzionale. La Guida per l'utente dell'Activity Monitoring Console di Talend fornisce tutti i dettagli per l'installazione del componente AMC, quindi non mi dilungherò sull'argomento. Concentriamoci invece sulle best practice per il suo utilizzo.

Il database AMC contiene tre tabelle che includono:
- tLogCatcher – cattura dati inviati da eccezioni java o dai componenti tWarn/tDie
- tStatCatcher – cattura dati inviati dalla casella di controllo Statistics (Statistiche) di tStatCatcher su singoli componenti
- tFlowMeterCatcher – cattura dati inviati dal componente tFlowMeter
Queste tabelle memorizzano i dati per l'interfaccia utente della console AMC, che offre un'efficace visualizzazione dell'attività di un job, sulla base dei dati acquisiti. Assicuratevi di selezionare la priorità di registrazione corretta nella scheda delle preferenze di progetto e valutate attentamente eventuali limitazioni dei dati applicate alle esecuzioni dei job in ciascun ambiente, DEV/TEST/PROD. Utilizzate la vista Main Chart (Grafico principale) per identificare e analizzare i colli di bottiglia nella progettazione job, prima di inviare una release negli ambienti PROD. Rivedete anche la schermata Error Report (Report errori) per analizzare la proporzione di errori che si verifica in un intervallo di tempo specificato.

Anche se interessante, questo non è il solo possibile utilizzo di queste tabelle. Dal momento che si tratta di vere e proprie tabelle di un database, è possibile creare query SQL per estrarre utili informazioni. È possibile utilizzare strumenti di scripting per creare query e notifiche automatiche che si attivano quando determinate condizioni si verificano e vengono registrate nel database AMC. Utilizzando una tecnica acquisita di codice di restituzione, descritta nel mio 1o blog sui Job Design Pattern, è possibile utilizzare queste query per eseguire in modo programmatico operazioni automatizzate che possono rivelarsi molto utili.
Checkpoint di ripristino
Avete creato un job dall'esecuzione particolarmente complessa? Magari include diversi passaggi critici e se un particolare passaggio non dovesse andare a buon fine, ricominciare da capo potrebbe rivelarsi estremamente problematico. Sarebbe bello poter ridurre al minimo il tempo e lo sforzo e riavviare il job da un punto specifico nel flusso del lavoro, appena prima dell'errore. Ebbene, la TAC offre una speciale funzionalità di ripristino dell'esecuzione da utilizzare quando si verificano errori in un job. Se posizionati in modo strategico e premeditato, questi "checkpoint di ripristino" inseriti nel job possono consentire la ripresa dell'esecuzione senza dover ricominciare da capo e interrompere l'elaborazione.

Se si verifica un errore, è possibile usare la scheda "Error Recovery Management" (Gestione ripristino errori) della TAC per determinare l'errore e lanciare di nuovo il job per un'elaborazione ininterrotta. Fantastico, vero?

Joblet
Abbiamo già parlato dei Joblet; si tratta di codice job riutilizzabile che può essere "incluso" in un job, o in più job, in base alle necessità; ma cosa sono veramente i Joblet? In realtà, non sono tanti i casi d'uso in cui è previsto l'impiego di Joblet; comunque, quando ne trovate uno, utilizzateli: sono un portento. È possibile costruire e utilizzare i Joblet in tanti modi diversi. Vediamoli.
Quando create un nuovo Joblet, i componenti Input/Output vengono automaticamente aggiunti alla "tela". Partendo in questo modo, è possibile assegnare gli schemi in arrivo e in uscita dal flusso di lavoro del job utilizzando il Joblet. Questo tipico impiego dei Joblet consente la trasmissione dei dati tramite il Joblet, permettendovi di decidere cosa fare all'interno di esso. Nell'esempio che segue, una riga viene introdotta, determinando l'aggiornamento di una tabella di database, registrata su stdout, quindi la stessa riga viene trasmessa invariata (in questo caso) e fatta uscire.

Un impiego non altrettanto tipico prevede la rimozione dell'input o dell'output, o di entrambi i componenti, per permettere la gestione di casi speciali di dati/flussi di processo. Nell'esempio che segue, nulla viene introdotto o fatto uscire dal Joblet. Al contrario, un componente tLogCatcher controlla varie eccezioni selezionate per la successiva elaborazione (abbiamo già visto questa procedura nelle best practice di gestione degli errori).
È chiaro che l'uso dei Joblet può migliorare drasticamente la riutilizzabilità del codice, come ci siamo prefissati. Inserite queste "perle" in un Progetto di riferimento per espanderne l'uso nei vari progetti. Si tratta di un elemento veramente utile.
Casi di test di componenti
Se utilizzate una release di Talend precedente alla v6.0.1, potete ignorare questa sezione. Scherzo, potete sempre effettuare un upgrade! Una delle mie nuove funzioni preferite è la possibilità di creare casi test per un job. Non sono propriamente dei "test di unità", ma si tratta comunque di test di componenti, ovvero job veri e propri collegati al job padre e, specificamente, al componente di cui eseguono il test. Non tutti i componenti supportano casi test, tuttavia, se un componente acquisisce un flusso di dati in ingresso e lo rimanda fuori, significa che un caso test è possibile.
Per creare un caso test per un componente, basta fare clic con il pulsante destro del mouse sul componente desiderato e selezionare l'opzione di menu "Create test case" (Crea caso test), in fondo all'elenco. Una volta selezionata questa opzione, viene generato un nuovo job che si aprirà presentando un modello funzionale per il caso test. Il componente sottoposto a test si troverà all'interno del modello insieme ai componenti INPUT e OUTPUT incorporati, inclusi in un flusso di dati che semplicemente legge un "Input File" (File di input), ne elabora i dati e trasmette i record al componente sottoposto a test, che fa ciò che deve fare e scrive il risultato in un nuovo "Result File" (File di risultato). Una volta completato, tale file viene confrontato con un risultato previsto o "Reference File" (File di rifermento). Il risultato del test dipende dalla corrispondenza o meno dei due file: se i file corrispondono il test è riuscito, se non corrispondono il test non è riuscito. Semplice, no? Vediamolo nel dettaglio.
Ecco un job che abbiamo già visto in precedenza; presenta un componente tJavaFlex che manipola il flusso di dati trasmettendolo a valle per un'ulteriore elaborazione.

È stato creato un job Test Case (Caso test) che si presenta come segue. Non sono necessarie modifiche (io ho soltanto ripulito un po' la "tela").
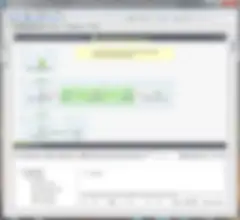
È importante tenere presente che è possibile modificare il codice del job del caso test, tuttavia, il componente sottoposto a test può essere modificato solo all'interno del job padre. Ammettiamo, ad esempio, che lo schema debba essere modificato. Apportando la modifica nel job padre (o repository), il caso test erediterà la modifica. I job sono connessi indissolubilmente, quindi tenuti assieme dallo stesso schema.
Una volta creata un'"istanza" di caso test, è possibile creare più file di "input" e di "riferimento" da eseguire nello stesso job del caso test. Ciò permette l'esecuzione di test su dati test buoni, cattivi, di piccole o grandi dimensioni e/o speciali. Il mio consiglio qui è di valutare attentamente non solo cosa testare, ma anche il tipo di dati test da utilizzare.
Per finire, se si utilizza il Nexus Artifact Repository e i job dei casi test vengono memorizzati in tale repository insieme al relativo job padre, è possibile utilizzare strumenti come Jenkins per automatizzare l'esecuzione dei test e, di conseguenza, la determinazione dell'idoneità di un job a passare nell'ambiente successivo.
"Iterazioni" del flusso di dati
Durante lo sviluppo di codice Talend, avrete sicuramente notato che i componenti vengono collegati tra loro mediante un processo "trigger" o un connettore di flusso di dati "row". Facendo clic con il pulsante destro del mouse sul componente iniziale e collegando la "linea" del link al componente successivo, viene stabilito il collegamento. I link del flusso di processo possono essere di tipo "OnSubJobOk/ERROR", "OnComponentOK/ERROR" o "RunIF"; li abbiamo analizzati nel precedente blog. Ai link del flusso di dati, una volta collegati, i nomi vengono assegnati in modo dinamico da Talend nella forma "row{x}", dove "x" corrisponde a un numero, per creare un nome oggetto/riga esclusivo. Questi link del flusso di dati possono avere anche nomi personalizzati (assegnati utilizzando la best practice di convenzione di denominazione), tuttavia, la definizione di questi link delinea essenzialmente la mappa dello schema dei dati da un componente all'altro e rappresenta la "pipeline" attraverso cui i dati vengono trasmessi. In fase di runtime, i dati trasmessi tramite questo tipo di collegamento vengono spesso definiti "dataset". A seconda dei componenti a valle, il dataset completo viene elaborato end-to-end all'interno del sotto-job che racchiude.
Non sempre però l'elaborazione del dataset può avvenire tutta in una volta, come in questo caso; talvolta può essere necessario controllare il flusso dei dati direttamente. Questo avviene tramite il controllo dell'elaborazione "riga per riga" o "iterazioni". Rivediamo il seguente codice privo di logica:

Si notino i componenti tIterateToFlow e tFlowToIterate. Questi componenti speciali consentono di mettere sotto controllo l'elaborazione del flusso di dati tramite l'iterazione dei dataset, riga per riga. Questa elaborazione "basata su elenco" può risultare piuttosto utile, all'occorrenza. Fate comunque attenzione poiché in molti casi, una volta suddiviso un flusso di dati in iterazioni riga per riga, può essere necessario ricomporlo in un dataset completo per consentire la continuazione dell'elaborazione (come per il componente tMap illustrato). Questo è dovuto a un requisito di alcuni componenti che forzano il flusso di dataset a livello di "riga" e non sono in grado di gestire il flusso di un dataset "iterativo". Si noti inoltre come i componenti t{DB}Input offrano sia l'opzione "main" (principale) che "iterate" (iterato) per il flusso di dati nel menu della riga.
Date un'occhiata agli scenari di esempio Transforming data flow to a list (Trasformazione di un flusso di dati in un elenco) e Transforming a list of files as a data flow (Trasformazione di un elenco di file in un flusso di dati) disponibili nel Centro assistenza Talend e nella Component Reference Guide. Qui troverete utili spiegazioni su come usare questa funzione. Utilizzate questa funzione in base alle necessità e assicuratevi di fornire etichette leggibili che ne descrivano lo scopo.
Conclusione
Assimilate bene tutte queste informazioni. Abbiamo quasi terminato. Nella Parte 4 di questa serie di blog affronteremo i Job Design Pattern e le best practice rimanenti per garantire solide basi al nostro codice Talend. Ma ho anche promesso che analizzerò dei "Casi d'uso di esempio", e lo farò. Credo che iniziare ad assimilare queste best practice sin da subito vi sarà molto utile per quando inizieremo ad analizzare le loro applicazioni astratte. Come sempre, vi esorto a inviare commenti, domande e/o ad avviare discussioni sull'argomento. Bonsai!

Altri articoli correlati
- "Job Design Pattern e best practice Talend": Parte 4
- Che cos'è la migrazione dei dati?
- Che cos'è la mappatura dei dati?
- Che cos'è la Data Integration?
- Migrazione dei dati: strategia e best practice
- Job Design Pattern e best practice Talend: parte 2
- Job Design Pattern e best practice Talend: parte 1
- Change Data Capture (CDC)
- Guida per sviluppatori alla migrazione da Informatica PowerCenter a Talend: Parte 1