Data Model Design e best practice: Parte 1
Business Applications, Data Integration, Master Data Management, Data Warehousing, Big Data, Data Lakes, e Machine Learning; tutti questi processi hanno (o dovrebbero avere) un ingrediente comune ed essenziale: il Data Model. NON dimentichiamolo o, come accade spesso, non ignoriamolo!
Il Data Modelè la colonna portante di quasi tutte le nostre soluzioni aziendali a valore aggiunto e di importanza "mission critical", dall'e-commerce al POS, passando dalla gestione finanziaria, dei prodotti e dei clienti, fino ad arrivare alle soluzioni di business intelligence e all'IoT. Senza un Data Model adeguato che fine farebbero i dati di business? Probabilmente andrebbero persi!
Dopo il successo della mia serie di blog sugli schemi di progettazione job di Talend (Parte 1, Parte 2, Parte 3 e Parte 4), che illustra 32 best practice e spiega come progettare al meglio i job in Talend, ho pensato di dedicarmi al data modeling. Bene, eccoci qua.
I Data Models e le Data Modeling Methodologies sono in circolazione sin dalla notte dei tempi. O, per lo meno, sin dall'inizio dell'era informatica. I dati devono essere strutturati per poter avere senso e devono fornire alle macchine un sistema per estrarre un significato dai loro bit e byte. Sicuramente oggi abbiamo a che fare anche con dati non strutturati e semi-strutturati, ma questo per me implica semplicemente che siamo passati a paradigmi più sofisticati di quelli con cui hanno avuto a che fare i nostri predecessori. Il Data Model dunque rimane e fornisce la base su cui creare applicazioni aziendali estremamente sofisticate. Come per le best practice Talend, ritengo che dobbiamo prendere estremamente sul serio i Data Models e le Data Modeling Methodologies.
Download >> Talend Open Studio for Data Integration
L'analisi della storia del Data Modeling può illuminarci, così ho fatto alcune ricerche per rinfrescarmi la memoria.
Brevi cenni storici sul modello di dati


Verso la fine degli anni sessanta, mentre lavorava presso IBM, E. F. Codd, in collaborazione con C. J. Date (autore di An Introduction to Database Systems), iniziò a delineare le proprie innovative teorie di Data Modeling nell'articolo Relational Model of Data for Large Shared Data Banks, pubblicato nel 1970. La campagna di Codd, finalizzata ad assicurare che i fornitori di IBM implementassero la metodologia in modo corretto, si tradusse nella celebre pubblicazione Twelve Rules of the Relational Model, del 1985. In realtà, si tratta di 
La successiva Data Modeling Methodology di rilievo è arrivata nel 1996, proposta da Ralph Kimball (ritirato), nel suo rivoluzionario libro The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, pubblicato in collaborazione con Margy Ross. Il modello di dati di Kimball, ovvero l'ampiamente adottato schema a stella, utilizzava concetti introdotti 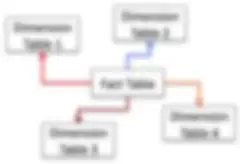

Riepilogo del modello di dati
- Modello piatto — unico array bidimensionale di elementi di dati
- Modello gerarchico — record contenenti campi e set che definiscono una gerarchia padre-figlio
- Modello reticolare — simile al modello gerarchico, ma che consente relazioni "da uno a molti" tramite una tabella di mappatura che impiega "link" di giunzione
- Modello relazionale — raccolta di predicati rispetto a un set finito di variabili di predicato, definito con vincoli relativi ai possibili valori e alle combinazioni di valori
- Modello a schema a stella — tabelle normalizzate di fatti e dimensioni che rimuovono attributi di bassa cardinalità per favorire l'aggregazione dei dati
- Modello Data Vault — registrazione di dati storici a lungo termine da più sorgenti di dati utilizzando tabelle hub, satellite e link
Ecco un rapido riepilogo delle varie metodologie di Data Model che si sono susseguite nel corso degli anni:
Ciclo vitale di sviluppo del database — DDLC
Oggi la discussione sembra concentrarsi interamente sulla complessità e sull'elevato volume dei dati. Ciò è sicuramente importante, tuttavia, vorrei ricordare di nuovo che il Data Model dovrebbe rimanere un elemento essenziale della discussione. Con l'evolversi dei requisiti, lo schema (un modello di dati) deve andare di conseguenza — o addirittura aprire la strada; in ogni caso, deve essere gestito. Di conseguenza, vi propongo il ciclo vitale dello sviluppo del database.
In ogni ambiente in cui sono coinvolti dati (ad es. sviluppo/test/produzione), gli sviluppatori si trovano a dover sistemare e adattare il codice in base alle inevitabili mutazioni strutturali dei dati stessi. Come per il ciclo vitale di sviluppo del software (SDLC), i database dovrebbero adottare Data Model Design e Best Practice appropriati. Nei vari modelli di dati che ho progettato emergono una serie di precetti chiave, che includono:
- Adattabilità — creazione di schemi in grado di reggere a miglioramenti o correzioni
- Espandibilità — creazione di schemi in grado di crescere oltre le aspettative
- Fondamentalità — creazione di schemi in grado di offrire caratteristiche e funzionalità
- Portabilità — creazione di schemi che possano essere ospitati sui sistemi più disparati
- Sfruttamento — creazione di schemi in grado di utilizzare al meglio una tecnologia host
- Efficienza di storage — creazione di schemi ottimizzati per lo spazio disponibile sul disco
- Alte prestazioni — creazione di schemi ottimizzati e dalle elevate prestazioni
Tali precetti progettuali incorporano l'essenza di qualunque metodologia di modellazione scelta, alcuni in contraddizione con altri. Secondo la mia esperienza, a prescindere da queste dicotomie, un Data Model presenta tre sole fasi, dalla sua nascita alla sua morte:
- INSTALLAZIONE iniziale — basata sulla versione corrente dello schema
- Applicazione di un UPGRADE — rilascio/creazione/alterazione di oggetti dB per l'aggiornamento di una versione alla successiva
- MIGRAZIONE dei dati — quando un upgrade ha conseguenze "devastanti" (come la separazione di tabelle o della piattaforma)
Progettare un Data Model può essere appassionante e comportare una noiosa attenzione al dettaglio, temperata dalla creativa astrazione dell'ambiguità. Personalmente attratto dagli schemi più impegnativi, cerco fessure e crepe da correggere, che spesso si manifestano nei modi più diversi. Ad esempio:
- χ Chiavi primarie composite evitatele, raramente si rivelano efficaci o appropriate; vi sono alcune eccezioni a seconda del Data Model
- χ Chiavi primarie errate in genere, gli oggetti datetime e/o le stringhe (a eccezione di GUID o Hash) non sono appropriati
- χ Indicizzazione errata né troppo, né troppo poco
- χ Tipi di dati di colonne se vi serve solo un valore Integer, non usate un valore Long (o Big Integer), in particolare su una chiave primaria
- χ Allocazione dello spazio di archiviazione senza considerare la dimensione dei dati e il potenziale di crescita
- χ Riferimenti circolari dove una tabella A ha una relazione con la tabella B, la tabella B ha una relazione con la tabella C e la tabella C ha una relazione con la tabella A – questo tipo di progettazione semplicemente non funziona (a mio parere)
Consideriamo ora una best practice di progettazione di database: il processo di progettazione e rilascio di un modello di dati. Ritengo che durante la creazione di un Data Model si dovrebbe seguire una procedura definita, simile a questa:

Anche se per i più la procedura si spiega da sé, lasciatemi sottolineare l'importanza di adottarla. Nonostante le modifiche allo schema siano inevitabili, definire un solido Data Model nella fase iniziale di un qualsiasi progetto di sviluppo software è essenziale. Ridurre al minimo l'impatto sul codice dell'applicazione è indubbiamente vantaggioso per realizzare progetti software di successo. Apportare modifiche allo schema può rivelarsi dispendioso, di conseguenza, comprendere il ciclo vitale del database e il suo ruolo diventa estremamente importante. Eseguire un controllo delle versioni del modello del database è di importanza critica. È possibile usare diagrammi grafici per illustrare i progetti. Potete creare un "dizionario dei dati" o un "glossario" e tracciare la provenienza delle variazioni storiche. Si tratta di un lavoro che richiede disciplina, ma che dà i suoi frutti!
Metodologie di Data Modeling
Comprendere la storia dei Data Model e le procedure migliori da seguire per progettarli è solo il punto di partenza. Lavorando come database architect di modelli sia di tipo transazionale (OLTP) che analitico (OLAP), ho scoperto che i primi tre passaggi illustrati sopra rappresentano circa l'80% del lavoro. Quindi passiamo immediatamente al successivo.
Talvolta i Data Model sono semplici da progettare, in genere per le dimensioni o la portata limitate. Tuttavia i Data Model possono essere anche estremamente difficili, generalmente a causa di complessità, diversità e/o dimensioni ingenti dei dati e dei numerosi punti dell'azienda in cui vengono utilizzati. Credo che in primo luogo sia necessario determinare le esatte dimensioni dei dati e dove si trovano, come influenzano o vengono influenzati dalle applicazioni e dai sistemi in cui sono utilizzati e per quale scopo vengono utilizzati. La sfida consiste proprio nel fare chiarezza su chi ha bisogno di cosa e su come ottenerlo. L'obiettivo è delineare una mappatura chiara per definire un Data model efficace. A tale scopo, è fondamentale scegliere la metodologia di data modeling più adatta.
Valore aziendale di un Data Model
I job ETL/ELT Talend vengono redatti per leggere e scrivere dati. Lo scopo di tutto questo è evidentemente offrire valore al business. Perché dunque abbiamo bisogno di un Data Model? Qual è il suo scopo? Non possiamo semplicemente elaborare i dati? Da un punto di vista tecnico, ci affidiamo al Data Model per disporre di una struttura a partire dalla quale possiamo manipolare il flusso di dati. Il ciclo vitale di un Data Model influisce direttamente sulla progettazione del job, le sue prestazioni e la sua scalabilità. E questa è solo la punta dell'iceberg, tecnicamente. Il punto di vista aziendale è forse più astratto. Principalmente, il modello di dati avvalora i requisiti di business. Fornisce una definizione critica per l'integrazione dei sistemi e il controllo strutturale dei dati usati dall'azienda, assicurando in tal modo diversi principi funzionali e/o operativi. A mio parare l'azienda diventa del tutto inefficiente senza un Data Model. Siamo tutti d'accordo?
Conclusione
Senza un modello di dati e strumenti come Talend, i dati possono risultare completamente inutili all'azienda o, peggio ancora, rallentarne la crescita a causa di imprecisioni, impieghi errati e incomprensioni. In base alla mia esperienza, disporre di un Data Model ben definito e di best practice del ciclo vitale di sviluppo del database accelera e incrementa il valore aziendale dei dati.
Nella Parte 2 di questa serie, illustrerò e analizzerò gli elementi essenziali e il valore del Data Model logico e fisico. Proporrò inoltre una visione dilatata del modo in cui i dati vengono differenziati: in primo luogo da un punto di vista olistico, quindi separando i dettagli concettuali, prima ancora di tentare una progettazione logica o fisica. Queste, per aiutarci a comprendere meglio i dati, modellano i dati e avallano il modello del nostro progetto di database.
Download >> Talend Open Studio for Data Integration
