Conception de modèles de données et bonnes pratiques : Partie 1
Les applications métier, l'intégration des données, la gestion des master data, le data warehousing, les big data, les data lakes et le machine learning ont tous (ou devraient tous avoir) en commun un même ingrédient essentiel : un modèle de données. Ne l'oublions PAS ou, comme dans de nombreuses situations que j'ai pu observer, ne le balayons PAS d'un revers de la main !
Le modèle de données est la pierre angulaire de presque toutes nos solutions métier stratégiques à forte valeur, du commerce électronique et du point de vente à l'intelligence décisionnelle et l'Internet des objets, en passant par la gestion financière, des produits et des clients. Sans un modèle de données adapté, où sont les données métier ? Probablement... perdues !
Suite au succès de ma série d'articles de blog sur les modèles de conception de jobs Talend et les bonnes pratiques (Partie 1, Partie 2, Partie 3 et Partie 4) qui couvre 32 bonnes pratiques et présente la meilleure façon de concevoir vos jobs dans Talend, j'avais laissé entendre que la publication d'un article sur la modélisation des données était imminente. Et bien, le voici !
Les modèles de données et les méthodologies de modélisation des données existent depuis la nuit des temps. En tout cas, depuis la nuit des temps de l'informatique. Les données doivent être structurées pour qu'on puisse leur donner un sens et permettre aux ordinateurs de traiter chacun de leurs bits et octets. Bien évidemment, aujourd'hui, nous avons également affaire à des données non structurées et semi-structurées mais, selon moi, cela veut simplement dire que nous avons évolué vers des paradigmes informatiques plus sophistiqués que ceux auxquels étaient confrontés nos prédécesseurs. Par conséquent, le modèle de données reste et fournit le socle sur lequel nous construisons des applications métier très avancées. Tout comme c'est le cas avec les bonnes pratiques de Talend, je suis convaincu que nous devons prendre au sérieux nos modèles de données et nos méthodes de modélisation.
Talend Open Studio for Data Integration →
Rétrospectivement, l'histoire de la modélisation de données peut nous éclairer. J'ai donc fait quelques recherches pour me rafraîchir la mémoire.
Une brève leçon d'histoire sur le modèle de données


À la fin des années 1960, alors qu'il travaillait chez IBM, E. F. Codd, en collaboration avec C. J. Date (l'auteur de « An Introduction to Database Systems »), schématisa les théories innovantes de modélisation des données de Codd dans « Relational Model of Data for Large Shared Data Banks » publié en 1970. Dans le cadre de sa campagne visant à garantir que les constructeurs mettraient en œuvre la méthodologie, Codd publia ses 
La grande méthodologie de modélisation des données suivante a vu le jour en 1996. Elle a été proposée par Ralph Kimball (à la retraite), dans son ouvrage révolutionnaire co-écrit avec Margy Ross « The Data Warehouse Toolkit: The Complete Guide to Dimensional 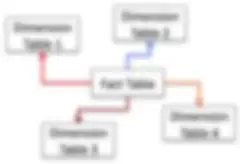

Le modèle de données en résumé
Bref résumé historique des différentes méthodologies de modélisation des données :
- Modèle à plat – baie simple en deux dimensions composée d'éléments de données
- Modèle hiérarchique – enregistrements contenant des champs et des ensembles définissant une hiérarchie parent/enfant
- Modèle en réseau – semblable au modèle hiérarchique mais permettant des relations un-à-plusieurs à l'aide d'une mise en correspondance des tables de « liaison »/jointure
- Modèle relationnel – ensemble de prédicats sur un ensemble fini de variables de prédicat défini par des contraintes sur les valeurs possibles et une combinaison de valeurs
- Modèle de schéma en étoile – tables de fait et de dimension normalisées supprimant les attributs à faible cardinalité en vue des agrégations de données
- Modèle de data vault – enregistrements de données historiques à long terme provenant de plusieurs sources de données et utilisant des tables hubs, satellites et links
Cycle de vie du développement des bases de données – DDLC
Le débat aujourd'hui semble porter uniquement sur la complexité et le volume des données. C'est important, évidemment, mais je tiens à vous rappeler une nouvelle fois que le modèle de données doit occuper une place importante dans la discussion. Le schéma (modèle de données) doit suivre l’évolution des exigences - ou même ouvrir la voie. Dans tous les cas, il doit être géré. C'est pourquoi je vous présente le cycle de vie du développement des bases de données !
Pour chaque environnement (DEV/TEST/PROD, etc.) comportant des données, les développeurs doivent adapter le code à son inévitable transformation structurelle. À l’instar du cycle de vie du développement logiciel (SDLC), une base de données doit adopter la conception de modèles de données et les bonnes pratiques adéquates. Des principes clairs ont émergé des nombreux modèles de données que j'ai conçus, notamment :
- Adaptabilité – création de schémas qui résistent à l'enrichissement ou à la correction
- Extensibilité – création de schémas qui se développent au-delà des attentes
- Caractère fondamental – création de schémas qui offrent les fonctions et les fonctionnalités nécessaires
- Portabilité – création de schémas qui peuvent être hébergés sur des systèmes disparates
- Exploitation – création de schémas qui optimisent la technologie hôte
- Stockage efficace – création d'un encombrement optimisé des schémas sur le disque
- Haute performance – création de schémas optimisés d'excellence
Ces principes de conception intègrent l'essence de toute méthodologie de modélisation choisie, parfois en contradiction les uns avec les autres. D'après mon expérience, malgré ces dichotomies, un modèle de données n'a que trois stades de vie, du berceau à la tombe :
- Une nouvelle INSTALLATION – en fonction de la version actuelle du schéma
- L'application d'une MISE À JOUR – dépôt/création/modification des objets de base de données en passant d'une version à la suivante
- La MIGRATION de données – si une « mise à niveau » perturbatrice a lieu (comme le fractionnement de tables ou d'une plateforme)
La conception d'un modèle de données peut être un travail de longue haleine, impliquant d'accorder une attention fastidieuse aux détails tout en faisant abstraction des ambiguïtés avec créativité. À titre personnel, étant attiré par les schémas complexes, je recherche le moindre défaut à corriger, quelle que soit la forme qu'il prend. Par exemple :
- χ Clés primaires composites elles doivent être évitées en raison de leur manque d'efficacité ou d'adéquation, il y a toutefois des exceptions en fonction du modèle de données
- χ Mauvaises clés primaires le type DateHeure et/ou les chaînes (GUID ou Hash) sont généralement incorrects
- χ Mauvaises indexations elles sont trop nombreuses ou trop rares
- χ Types de données Colonne évitez d'utiliser un entier long (entier très grand), en particulier sur une clé primaire, si vous n'avez besoin que d'un entier
- χ Allocation de mémoire quelle que soit la taille des données et le potentiel de croissance
- χ Références circulaires si une table A a un lien avec une table B, que la table B a un lien avec une table C et que la table C a un lien avec la table A, la conception est mauvaise (à mon humble avis)
Étudions une bonne pratique en matière de conception de base de données : le processus de conception et de publication d'un modèle de données. J'estime, que lors de la création d'un modèle de données, on doit suivre un processus établi ressemblant à ceci :

Même s'il se passe probablement d'explication pour la plupart d'entre vous, permettez-moi quand même de souligner l'importance de ce processus. Si les schémas évolueront inévitablement, il est crucial de définir rapidement un modèle de données robuste lors de tout projet de développement logiciel. Il est évident que, pour obtenir des projets logiciels performants, l'impact sur le code d'application doit être limité au maximum. Une bonne connaissance du cycle de vie des bases de données et de son rôle prend tout son sens lorsque l'on sait que les changements de schéma peuvent se révéler coûteux. Il est donc essentiel de gérer correctement les versions de votre modèle de base de données. Utilisez des graphiques pour illustrer les conceptions. Créez un « dictionnaire » ou un « glossaire des données » et gardez une trace du linéage des modifications historiques. Ҫa demande plus de discipline mais ça marche !
Méthodologie de modélisation des données
Tout commence par une bonne connaissance de l'historique du modèle de données et du processus optimal par lequel il doit être conçu. En tant qu'architecte de bases de données pour des modèles transactionnel (OLTP) et analytique (OLAP), j'ai pu constater que les trois premières étapes illustrées dans le diagramme ci-dessus constituent environ 80 % du travail. Penchons-nous donc sur cette question.
Concevoir un modèle de données peut parfois être aisé, généralement du fait de sa simplicité et/ou de sa petite taille. Cela peut aussi être très difficile, le plus souvent en raison de la complexité, de la diversité et/ou de la taille et du format des données et des nombreux domaines au sein de l'entreprise où elles sont utilisées. J'estime que nous devrions connaître le plus rapidement possible l'ampleur des données, leur emplacement, la manière dont elles sont affectées par les applications et les systèmes les utilisant ou dont elles les affectent, et pourquoi elles se trouvent là en premier lieu. Le défi qui se pose à vous est de déterminer qui a besoin de quoi et comment le fournir. Votre objectif : mettre tous ces éléments en correspondance pour garantir un modèle de données robuste. Il est primordial de choisir la bonne méthodologie de modélisation des données.
Valeur métier d'un modèle de données
Les jobs ETL/ELT de Talend sont conçus pour lire et écrire des données. Notre but est clairement d'apporter une valeur ajoutée au métier. Pourquoi, dans ce cas, avons-nous besoin d'un modèle de données ? Quelle est son utilité ? N'est-il pas possible de le traiter simplement une bonne fois pour toutes ?
D'un point de vue technique, nous avons besoin du modèle de données pour disposer d'une structure à partir de laquelle nous pourrons manipuler le flux de données. Le cycle de vie d'un modèle de données a une incidence directe sur la conception, les performances et l'adaptabilité des jobs. Et ce n'est, techniquement, que la partie émergée de l'iceberg. D'un point de vue métier, les choses sont peut-être plus abstraites. Avant toute chose, le modèle de données valide les exigences métier. Il offre une définition vitale pour l'intégration des systèmes et le contrôle structurel des données utilisées par le métier et garantit ainsi le respect de différents principes fonctionnels et/ou opérationnels. J'affirme que le métier perd toute efficacité sans modèle de données. Vous êtes d’accord ?
Conclusion
Sans le modèle de données et des outils tels que Talend, les données peuvent ne pas présenter le moindre intérêt économique ou, encore pire, entraver la réussite de votre entreprise en raison de leur inexactitude, d'un mauvais usage ou d'une mauvaise compréhension. D'après mon expérience, un modèle de données bien défini et l'application de bonnes pratiques en matière de DDLC accélèrent et augmentent la valeur métier des données.
Dans la Partie 2 de cette série d'articles, j'illustrerai et examinerai les principes fondamentaux et l'intérêt du modèle de données logique et physique. J'expliquerai également plus en détail comment différencier nos données : dans une perspective d'ensemble dans un premier temps, puis en examinant les concepts séparément avant que nous puissions envisager une conception logique ou physique. Afin de mieux comprendre les données, de pouvoir les modéliser et de valider le modèle de conception de notre base de données.
Partie 2 →

Plus d'articles connexes
- Qu’est-ce que la metadata et pourquoi est-elle aussi importante que la data ?
- Processus de fiabilisation des données, le guide définitif
- Principes de base de la gestion des métadonnées
- Pourquoi et comment nettoyer ses données d’entreprise ?
- Préparation des données – Présentation générale
- Conception de modèles de données et bonnes pratiques : Partie 2