Aufbau eines verwalteten Data Lake in der Cloud
Beitrag von Dale T. Anderson, Talend Regional Manager, Customer Success Architect, und Kent Graziano, Snowflake Senior Technical Evangelist
Sie möchten einen Data Lake erstellen? Dann lassen Sie uns ein wenig darüber sprechen. Vielleicht denken Sie, dass Sie mit einem Data Lake Ihr Data-Warehouse ersetzen und all Ihre Business-Anwender damit spielend leicht Geschäftsanalysen durchführen können. Dass Sie – wenn Sie für all Ihre Ressourcen Big-Data-Technologien wie Hadoop verwenden – Ihre gesamten Datenherausforderungen lösen und mit Spark innerhalb kürzester Zeit Daten verarbeiten können, um nützliche Erkenntnisse auf Basis maschinellen Lernens zu gewinnen und sich so wie von Zauberhand einen Wettbewerbsvorteil zu verschaffen. Und mit NoSQL braucht ja niemand mehr ein Datenmodell, oder?
Das Meiste davon ist wirklich nur ein Hype. Daher fragen wir Sie: Wie möchten Sie Ihrem Vorgesetzten erklären, dass es sich bei Ihrem brandneuen Data Lake in Wirklichkeit um einen Datensumpf handelt, der mit Daten aus vielen beliebigen Quellen verunreinigt ist und keine wertvollen Informationen bietet? Unser Tipp: Vergessen Sie das alles. Wir schlagen Ihnen stattdessen vor, eine bessere Lösung mitTalend und Snowflake Elastic Data Warehouse zu erstellen.
Bevor Sie mit dem Aufbau Ihres Data Lake beginnen, lassen Sie uns zunächst ein paar häufige Missverständnisse klären:
- Ein Data Lake hat (idealerweise) folgende Merkmale
- Alle Geschäftsdaten sollten sich an einem zentralen Ort befinden
- Ein offenes Datenwörterbuch (oder Glossar), das Herkunft und Historie aufzeigt
- Eine Fusion von Quelldaten mit wertvollen Metadatenmodellen
- Nutzbar für zahlreiche operative und Reporting-Anforderungen
- Skalierbar, anpassbar und robust; für fast alle Geschäftsanforderungen geeignet
- Ein Data Lake ist nicht (bzw. sollte nicht)
- das „neue“ Enterprise-Data-Warehouse
- zwingend Hadoop- oder NoSQL-basiert
- einfach nur ein weiteres Datensilo mit schnellem, einfachem Zugriff
- in der Lage, Datenintegration und -verarbeitung zu ersetzen
- der neueste Trend (er hat einen praktischen Nutzen)
- nur für IoT-, Analyse- und KI-Funktionen bestimmt
Was spricht dann eigentlich für einen Data Lake? Unserer Meinung nach liegt der Zweck eines Data Lake im Wesentlichen darin, einen direkten und umfassenden Zugriff auf rohe (ungefilterte) Unternehmensdaten bereitzustellen. Data Lakes sind eine Alternative zur Speicherung einer begrenzten Anzahl unterschiedlicher Datensätze in verstreuten, heterogenen Datensilos. Nehmen wir zum Beispiel an, dass Sie ERP-Daten in einem Data-Mart und Weblogs auf einem anderen Dateiserver haben: Wenn Sie eine Abfrage für beide benötigen, ist häufig ein komplexes Federation-Schema (und zusätzliche Software) erforderlich – ein echtes Ärgernis. Mit einem Data Lake können Sie idealerweise all diese Daten in einem großen Repository zusammenführen und für beliebige Abfragen verfügbar machen.
Ein gut durchdachter und verwalteter Data Lake erlaubt es Ihnen, alle relevanten Daten zusammenführen, und bietet Ihnen so eine einfache und nahtlose Unterstützung für sämtliche Business-Use-Cases. Wenn Sie gemeinsam mit Ihrem Data-Science-Team alles von traditionellen Business-Intelligence-Berichten und -Analysen bis hin zu Datenermittlung, Data-Discovery und Datenexperimenten abdecken, wird Ihr Vorgesetzter Ihnen sicher auf die Schulter klopfen.
Was brauchen Sie also, um erfolgreich einen Data Lake aufzubauen? Wie bei den meisten komplexen Softwareprojekten, bei denen riesige Datenmengen im Spiel sind, sollten Sie sich zunächst einige Gedanken machen. Die potenziellen Vorteile eines gut durchdachten Data Lake überwiegen bei weitem den Entwicklungsaufwand. Auf jeden Fall sollten Sie angemessene Erwartungen definieren. Es kann sein, dass es etwas dauert, bis messbare Ergebnisse zu erkennen sind. Sie müssen sich die Zeit nehmen, um die einzelnen Schritte zu gestalten und zu planen und den Zeitplan zu definieren. Nutzen Sie am besten einen agilen Ansatz. Wichtig ist, dass Sie Ziele definieren und einen Rhythmus wählen, mit dem Ihr Team arbeiten kann und der sich bei Bedarf anpassen lässt. Damit wären Sie auf einem guten Weg.
Wie bei anderen komplexen Softwareprojekten, bei denen es um enorme Datenmengen geht, müssen Sie vor allem drei Dinge beachten:
- MITARBEITER
- Binden Sie alle Business-Stakeholder ein – es handelt sich schließlich um ihre Daten
- Holen Sie bei Bedarf Datenexperten ins Boot – oder werden Sie selber zu einem
- PROZESS
- Definieren und befolgen Sie angemessene, flexible Richtlinien – schreiben Sie diese auf
- Etablieren Sie Data-Governance als Norm – und nicht als nachträgliches Projekt
- Setzen Sie auf geeignete Technologien – SDLC und Datenmodellierung
- Nutzen Sie Best Practices – achten Sie auf Einheitlichkeit
- TECHNOLOGIE
- Nutzen Sie die richtigen Tools – lernen Sie, wie sie funktionieren
Architektur und Infrastruktur
Wenn wir über Data Lakes sprechen, ist es wichtig, ihre Vorteile zu verstehen, aber gleichzeitig auch angemessene Erwartungen festzulegen. Wie bei allen neuen Begriffen passiert es auch bei Data Lakes schnell, dass man sie und/oder ihre Nutzungsweise falsch interpretiert und/oder falsch darstellt. Häufig haben Stakeholder ihre ganz eigene Auffassung (oft beflügelt durch den Hype in ihrer Branche, der zu unrealistischen Erwartungen führt), was einen Mix aus schlechter Kommunikation, falschen Technologien und ungeeigneten Methoden zur Folge haben kann. Wir möchten Ihnen helfen, das zu vermeiden.
Für einen verwalteten Data Lake brauchen Sie im Grunde einen robusten Datenintegrationsprozess, um Daten zusammen mit wertvollen Metadaten einschließlich Datenherkunft (z. B. Ladedatum und Quelle) so zu speichern, dass sich sämtliche Informationen abrufen lassen. Ohne diese wichtigen Attribute ist die Wahrscheinlichkeit, dass Sie sich in einem Datensumpf wiederfinden, extrem hoch. Lassen Sie uns als Nächstes zwei wichtige Ökosysteme unter die Lupe nehmen:
- Lokale Systeme
- Zum Beispiel RDBMS und/oder Big-Data-Infrastrukturen
- In der Regel selbst verwaltet mit kontrolliertem/sicherem Zugriff
- Umfassen wahrscheinlich QUELLDATEN, aber nicht ausschließlich
- Traditioneller IT-Support, Einschränkungen und Verzögerungen
- Cloud
- Zum Beispiel SaaS-Anwendungen
- Oft mit Benutzerrollen/Berechtigungen für den Zugriff gehostet
- Beim Prozess könnte es sich um Cloud-to-Cloud, Cloud-to-Ground oder Ground-to-Cloud handeln
- Geringe TCO, hohe Flexibilität und globale Nutzbarkeit
Lokal und in der Cloud
Ihre Architektur und Infrastruktur variiert je nach Anforderungen. Die möglichen Vorteile hängen direkt von den Entscheidungen ab, die Sie in den ersten Phasen eines Data Lake-Projekts treffen. Talend und Snowflake unterstützen beide Ökosysteme. Werfen wir einen Blick darauf:
Option 1 – Talend lokal und Snowflake in der Cloud
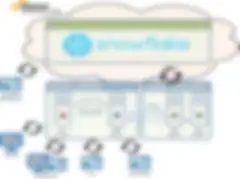
Bei dieser ersten Option wird Talend lokal in Ihrem Datencenter installiert und ausgeführt, während Snowflake auf einer gehosteten AWS-Plattform läuft. Ausführungsserver führen Ihre Talend-Jobs aus, die mit Snowflake verknüpft sind und je nach Bedarf Daten verarbeiten.
Dies ist eine gute Option, wenn Sie lieber Talend-Services über ein breites Spektrum an Quell-/Zieldaten-Use-Cases unterstützen möchten und der Data Lake nicht im Mittelpunkt steht.
Option 2 – Talend und Snowflake in der Cloud
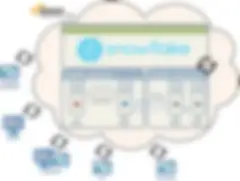
Bei der zweiten Option wird Talend in der Cloud implementiert (eventuell auf AWS gehostet). Ausführungsserver führen Ihre Jobs in der Cloud aus und nutzen vielleicht einige der neuen AWS-Komponenten, die jetzt für Jobs verfügbar sind, bei denen eine flexible Nutzung der AWS-Plattform möglich ist. Diese Jobs lassen sich mit Snowflake und/oder beliebigen anderen Quellen/Daten aus dem Cloud-Ökosystem verknüpfen. Dies könnte die beste Option für ein Szenario sein, in dem Sie Daten aus in der Cloud gespeicherten Dateien direkt in Ihren Data Lake speisen und bei dem die Nutzer, die einen Zugriff auf Talend benötigen, auf der ganzen Welt verteilt sind.
Datenintegration und -verarbeitung
Einen Data Lake mit Daten zu füllen ist ein mühseliger Prozess. Und die Daten wieder herauszubekommen, kann sogar noch aufwendiger sein. Leistungsstarke ETL-/ELT-Datenintegrations- und -verarbeitungsfunktionen sind daher unerlässlich. Wie Sie vielleicht schon wissen, bietet unsere Softwareplattform die Grundlage, um Ihren Code zu schreiben und diese Anforderungen zu erfüllen. Als Java-Generierungstool bietet Talend bewährte Funktionen zur Entwicklung robuster Prozesse und effizienter Datenflows. Die Talend-Software unterstützt Projektintegration, kollaborative Entwicklung, Systemadministration, Planung, Überwachung, Protokollierung und noch vieles mehr.
Mit den mehr als 1.000 Komponenten aus dem Talend-Winter-Release 2017 (v6.3.1) können Sie jetzt wesentlich einfacher eine Lösung erstellen, um Ihren Data Lake zu füllen und zu bearbeiten. Weitere Produktfunktionen umfassen Datenqualität, Data-Governance und Datenaufbereitung für Geschäftsanalysten. Das Talend-Tool Data Catalog erfasst Details zu Ihren Daten in einem Glossar. Auf diese Weise können Sie die Historie lückenlos nachverfolgen, auch wenn sich Schemata ändern, während die Generation der Talend-Jobs je nach Bedarf unterstützt wird.
Vor kurzem hat Talend eine *NEUE* Snowflake-Komponente herausgegeben. Da diese Komponente mithilfe des neuen Component-Framework (TCOMP) geschrieben wurde, ist sie nur mit Talend V6.3.1 und neueren Versionen kompatibel – vergewissern Sie sich also zuerst, dass Sie über die korrekte Installation verfügen, bevor Sie beginnen.
Data Warehouse as a Service (DWaaS) in der Cloud
Worüber sprechen wir eigentlich, wenn es um ein Data Warehouse as a Service geht? In erster Linie meinen wir eine RDBMS-Plattform, die speziell für Data-Warehouse-typische Abfragen entwickelt wurde, also Analyseabfragen und Aggregationen. Außerdem muss es Tools unterstützen, die Standard-SQL als primäre Sprache nutzen. Last, but not least muss es – um alle Datenanforderungen Ihres Data Lake zu erfüllen – die Datenaufnahme sowie die Fähigkeit unterstützen, halbstrukturierte Daten auf dieselbe Weise abzufragen wie Big-Data-Systeme.
Darüber hinaus muss das Produkt als Service (as a Service) in der Cloud angeboten werden. Das bedeutet genauso wie bei SaaS, dass keine Infrastruktur eingerichtet werden muss und dass Konfiguration und Administration vom Anbieter übernommen werden. Außerdem ist auch ein flexibles Pay-as-you-go-Modell erforderlich, was im Fall von DWaaS bedeutet, dass Sie Rechen- oder Speicherressourcen, die Sie nicht nutzen, auch nicht bezahlen.
Sie sollten sich wirklich Gedanken darüber machen, denn mit einer effizienten DWaaS-Lösung können Sie Ihrer Organisation einen einfachen Zugriff auf alle benötigten Daten bieten (und genau dazu ist ein Data Lake ja gedacht, oder?). Neben dem schnellen Laden strukturierter und unstrukturierter Daten bietet diese Lösung auch einen einfachen Zugriff auf wertvolle Daten, um Probleme zeitgerecht und kosteneffizient zu lösen. In Kombination mit der Cloud lässt sich die Lösung bei Bedarf in beide Richtungen flexibel skalieren, sodass jede beliebige Anzahl gleichzeitiger Nutzer erreicht werden kann.
Snowflake ist das einzige Data-Warehouse, das ausschließlich als Service für die Cloud entwickelt wurde. Snowflake bietet die nötige Performance und Einfachheit, um all Ihre Unternehmensdaten an einem zentralen Ort zu speichern und zu analysieren. Zudem unterstützt es eine hohe Anzahl gleichzeitiger Benutzer. Dank Snowflake können Sie die Power des Data-Warehousing, die Flexibilität von Big-Data-Plattformen und die Elastizität der Cloud zu einem Bruchteil der Kosten traditioneller Lösungen miteinander kombinieren.
Eine der Eigenschaften, die Snowflake zu einer großartigen Data Lake-Plattform machen, ist die innovative Trennung von Speicher und Computing, bekannt als Multi-Cluster-shared-Datenarchitektur. Im Gegensatz zu aktuellen bzw. älteren lokalen Architekturen können Sie mit Snowflake Ihren Speicher dynamisch ohne Rücksicht auf Computing-Knoten erweitern. Genauso können Sie, wenn Sie mehr Rechenleistung benötigen, die Größe Ihrer Computing-Cluster dynamisch anpassen und mehr Ressourcen hinzufügen, ohne weitere Festplatten kaufen zu müssen. Die Trennung ermöglicht ein Streaming von Terabytes oder sogar Petabytes an Rohdaten, ohne dass Sie sich Gedanken über die Größe Ihres Warehouse-Clusters machen müssen.
Durch die Trennung von Speicher und Computing können Sie mehrere unabhängige Computing-Cluster (sogenannte virtuelle Warehouses) konfigurieren, die auf denselben zentralen Datenspeicher zugreifen. Mit einem erfolgreich konzipierten Data Lake, der mehrere Terabyte umfasst, können Sie Ihren Data-Scientists einen eigenen separaten Computing-Cluster bereitstellen. Damit können sie Machine-Learning- und/oder SPARK-Talend-Jobs ausführen, ohne dass andere User im System beeinträchtigt werden. Weitere Einzelheiten zu diesen Funktionen erhalten Sie hier:
Ein weiteres nützliches Feature von Snowflake ist „Time Travel“. Snowflake verfolgt automatisch alle Veränderungen, die im Laufe der Zeit an den Daten vorgenommen werden (wie Slowly Changing Dimension Typ II). Das geschieht im Hintergrund, ohne Einrichtung oder Administration, was Ihren Data Lake von Anfang an zeitvariant macht. Sie können beliebige Datenobjekte zu einem beliebigen Zeitpunkt bis zu 90 Tage in der Vergangenheit abfragen – perfekt, um große, dynamische Datensätze zu vergleichen.
Wer würde bei solchen Tools eine manuelle Codierung vorziehen?
SDLC und Best Practices
Am liebsten würden wir hier alles ganz genau erklären. Allerdings würde dies den Rahmen unseres einfachen Blogeintrags bei weitem sprengen. Hier eine kurze Übersicht:
- Agiles Enablement mit Snowflake und Talend
- Data Lake-Lade- und -Abruftechniken mit Spark
- Machine-Learning-Modelle für prädiktive Analysen
Wir schlagen Ihnen stattdessen vor, künftig weitere Blogeinträge zu diesen Themen zu lesen. Unserer Meinung nach sollten Sie diese Informationen beim Aufbau eines effizienten Data Lake berücksichtigen. In der Zwischenzeit könnte die vierteilige Reihe Talend Job Design Patterns and Best Practices (Design-Muster und Best Practices rund um Talend-Jobs) interessant für Sie sein. Weitere spannende Lektüren sind Saving Time and Space: Simplifying DevOps with Fast Cloning (Zeit und Platz sparen: einfache DevOps-Prozesse dank Fast Cloning) und Automatic Query Optimization (Automatische Abfrageoptimierung) von Snowflake. Unabhängig davon sollten Sie Ihren Ansatz für Ihre Infrastruktur und die Implementierung eines Data Lake sorgfältig prüfen. Einige der Optionen, die dank dieser Technologien heute verfügbar sind, gab es vor wenigen Jahren nicht einmal.
Datentresormodellierung
Ein weiteres wichtiges Thema in diesem Zusammenhang sind die Datenmodellierungsmethoden, die Sie in Ihrem Data Lake anwenden können. Obwohl dieses Thema oft vergessen oder sogar ignoriert wird, ist es entscheidend für Ihren langfristigen Erfolg. Wir beide haben in diversen Blogeinträgen über den Datentresor geschrieben: Eine Einleitung zu den Konzepten und Vorteilen dieser innovativen Lösung finden Sie im Beitrag What is a Data Vault and Why do we need it? (Was ist ein Datentresor und warum brauchen Sie einen?). Weitere Informationen finden Sie unter Data Vault Modeling and Snowflake (Datentresormodellierung und Snowflake) und List of top Data Vault Resources (Liste der wichtigsten Ressourcen rund um Datentresore). Wir hoffen, dass Sie hier ein paar nützliche Informationen finden.
Der Datentresoransatz für Datenmodellierung und Business-Intelligence bietet eine äußerst agile, flexible, anpassbare und besonders automatisierbare Methode für den Aufbau eines Ökosystems für Unternehmensdaten. Eine der Architekturgrundlagen eines Datentresors ist ein Staging-Bereich, in dem die rohen Quelldaten gespeichert werden. Zum Teil wird dadurch das Prinzip des Datentresors unterstützt, Ladeprozesse neu zu starten, sodass eine Rückkehr zu den Quellsystemen zum erneuten Abrufen der Daten nicht mehr nötig ist. Vor kurzem wurde bei einer Präsentation die Anmerkung gemacht, dass dies alles sehr nach Data Lake klingt ...
Wenn wir die Datentresor-Empfehlungen befolgen, jederzeit das Ladedatum und die Datensatzquelle in jeder Zeile aufzuzeichnen, wird langsam das Konzept eines verwalteten Data Lake sichtbar. Im nächsten Schritt geht es darum, einen festen Staging-Bereich einzurichten und „Change Data Capture“-Methoden auf den Ladeprozess anzuwenden (um Duplikate zu vermeiden). Jetzt haben wir wirklich einen verwalteten Data Lake und rohe Quelldaten in Kombination mit Metadaten – mit dem zusätzlichen Vorteil, dass dieser wesentlich weniger Speicher nutzt als ein typischer Data Lake (dieser lädt im Laufe der Zeit vollständige Kopien der Quelldaten, bietet aber keinen sinnvollen Mechanismus, um nützliche Informationen auf einfache Weise abzurufen oder von anderen, weniger nützlichen zu unterscheiden.

Nehmen Sie sich etwas Zeit, um sich das Talend Data Vault Tutorial (Talend-Datentresor-Tutorial) anzusehen, das auf dem hier beschriebenen Modell basiert. In diesem Tutorial erfahren Sie, wie Sie einen 100-prozentigen INSERT-ONLY-Data Lake mithilfe von Talend-Jobs verarbeiten können. Der Quellcode ist bereits enthalten und in einem künftigen Release wird die Cloud-Implementierung mit der NEUEN, oben erwähnten Snowflake-Komponente ermöglicht.
Fazit
Legen Sie keinen Datensumpf an! Nutzen Sie hoch entwickelte cloudbasierte DWaaS-Lösungen (Snowflake) und das führende Datenintegrationstool (Talend), um einen verwalteten Data Lake als Grundlage einer modernen Enterprise-Datenarchitektur zu erstellen. Verwenden Sie anstelle des traditionellen Sternschemas, das der sprichwörtlichen Quadratur des Kreises entspricht, eine hoch anpassbare Datentresormethode für die Datenmodellierung, um Ihren Data Lake schnell, effizient und effektiv zu entwickeln. Ein gut durchdachter, strukturierter und implementierter Data Lake bietet Ihrem Unternehmen einen echten Mehrwert und schafft die Grundlage für erfolgreiche Prozesse. Sprechen Sie mit Ihrem Vorgesetzten darüber!
Sie möchten sich gerne über diese Themen austauschen? Dann besuchen Sie im Mai das 4. jährliche World Wide Data Vault Consortium in Stowe, Vermont (USA) und treffen Sie dort Dale T. Anderson und Kent Graziano. Sowohl Talend als auch Snowflake sind Sponsoren dieser Veranstaltung. Die Teilnehmerzahl ist begrenzt, melden Sie sich also am besten bald an.
Über den Autor: Kent Graziano
Kent Graziano ist Senior Technical Evangelist bei Snowflake Computing und ein preisgekrönter Autor, Redner und Dozent in den Bereichen Datenmodellierung, Datenarchitektur und Data-Warehousing. Er ist zertifizierter Data Vault Master und Data Vault 2.0 Practitioner (CDVP2) sowie ein erfahrener Datenmodellierer und Lösungsarchitekt mit über 30 Jahren Erfahrung, einschließlich zwei Jahrzehnten im Bereich Data-Warehousing und Business-Intelligence (in verschiedenen Branchen). Er ist ein international anerkannter Experte für Oracle SQL Developer Data Modeler und agiles Data-Warehousing. Graziano hat viele erfolgreiche Software- und Data-Warehouse-Implementierungsteams (einschließlich mehrerer agiler DW-/BI-Teams) geschult und geleitet. Er hat zahlreiche Artikel geschrieben, ist Autor von drei Kindle-Büchern (erhältlich auf amazon.com), hat vier Bücher mitverfasst und Hunderte Präsentationen auf nationaler und internationaler Ebene gehalten. Er war technischer Redakteur für das Buch Super Charge Your Data Warehouse (Optimieren Sie Ihr Data-Warehouse) (das Fachbuch schlechthin für DV 1.0). Sie können Graziano auf Twitter @KentGraziano oder auf seinem Blog The Data Warrior (http://kentgraziano.com) folgen.
