











Unlock the power of Qlik Talend
Streamline data operations
Eliminate the data barriers between business and IT with automated, AI augmented, cloud-independent and technology agnostic solutions.
Ensure enterprise-grade trust
End-to-end data quality capabilities that deliver curated and readily accessible, trusted data.
Flexible deployment
Deploy in the cloud, on-premises, or in hybrid environments, ensuring flexibility to meet data residency, security, and infrastructure requirements.
Easily meet constantly changing requirements
Pre-defined integrations with hundreds of data sources and tools help you stay fully connected across platforms, even as your needs change.
Looking for Talend Data Fabric?
Talend Data Fabric, both in the cloud and on-premises, is still available for trial and purchase.
Talend Data Fabric
Operational data integration
Comprehensive ETL capabilities
Production-proven & trusted
The strengths of Qlik Talend
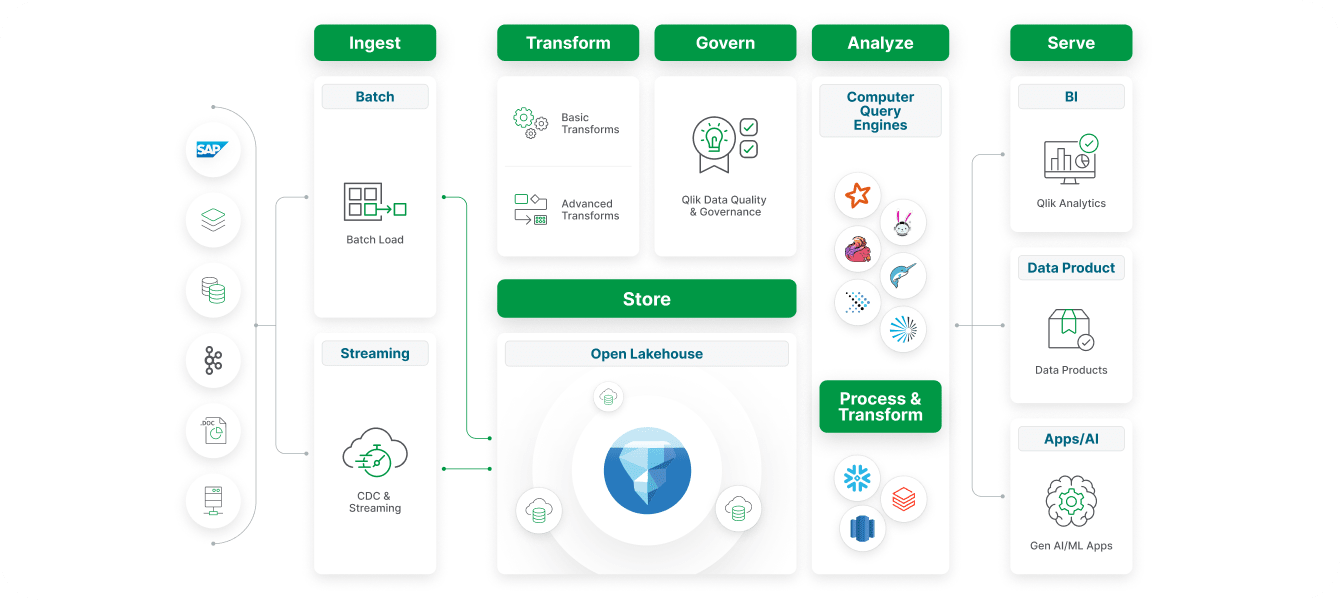
A unified platform for integration, quality, and governance — built for scale and flexibility, with tools for every role in your data journey. In the Cloud, On-Premises, or Hybrid, get the power of Qlik and Talend however you want.

Multi-modal data integration patterns
Support every integration need (from batch and real-time to ETL, ELT, and APIs) within a single, scalable platform built for modern data pipelines.

Superior data quality & governance
Powerful data quality tools and workflows, such as Data Products and Lineage, deliver trusted, reusable datasets for analytics, machine learning, and business consumption.
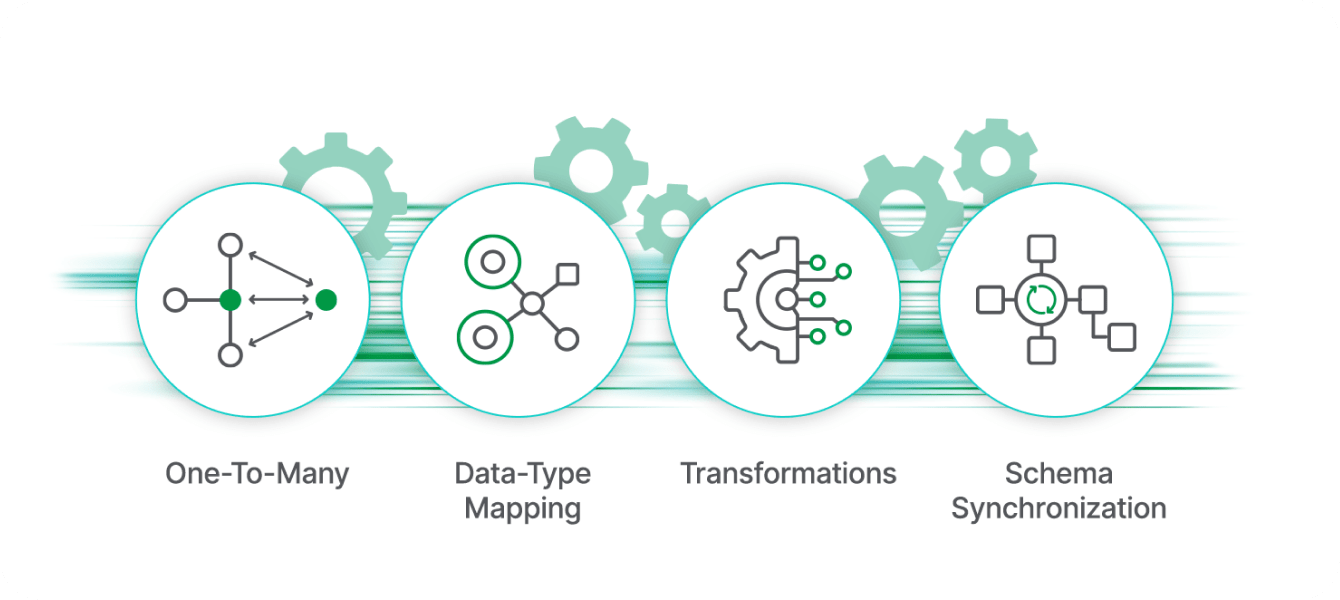
Multiple data transformations options
Empower every user — from data engineers to business analysts — with flexible transformation capabilities, including both visual, low-code tooling, and full-code control, all within a single integrated platform.
AI-augmented no-code pipelines
Fuel AI, analytics and machine learning initiatives with trusted, high-quality data pipelines that integrate, cleanse, and transform data across any environment with speed and scalability.
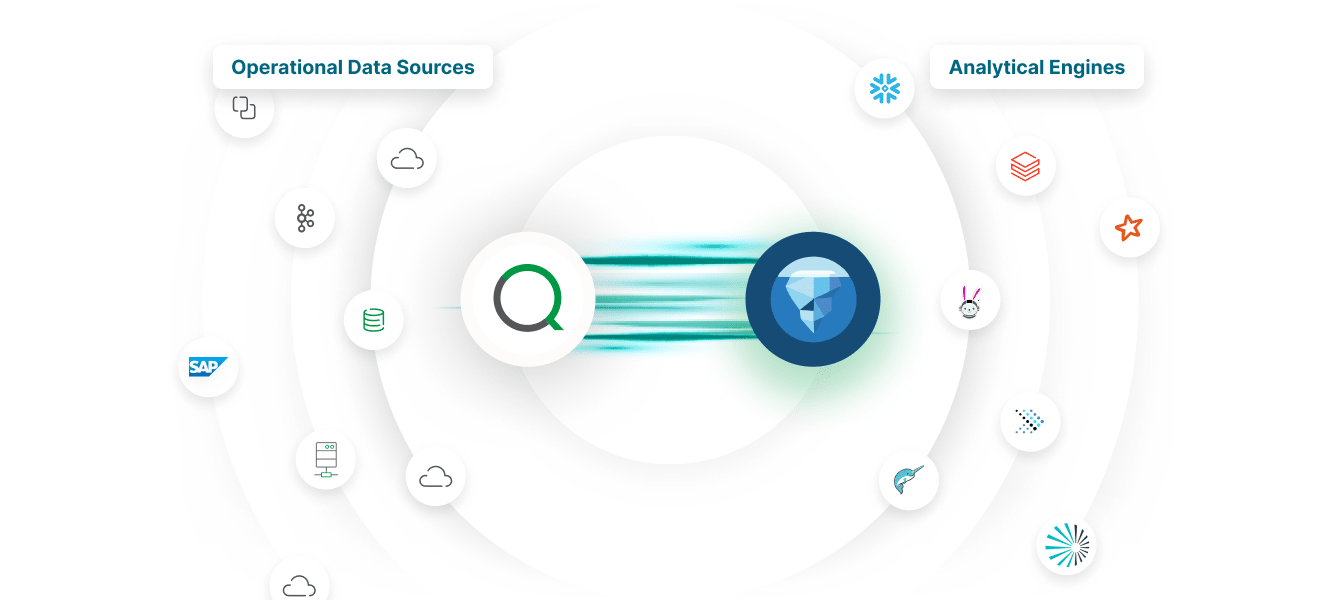
High-performance lakehouses
Combine the scalability of data lakes with the performance of data warehouses, enabling unified analytics and real-time insights across all data.
FAQ
Addressing common questions from Talend customers about Qlik + Talend
There is no change. Existing Talend customers can continue leveraging their current Talend solutions without disruption.
No. Talend customers are already using the same support portal as Qlik - https://customerportal.qlik.com/
Yes. There are a number of paths for you to expand your solution with Qlik. Please contact your local Qlik representative to discuss how we can best help you expand your specific environment. You can also experience some of these new capabilities for yourself by trying our Qlik Talend Cloud trial or Qlik Cloud Analytics trial.