What it is, why it matters, and best practices. This guide provides a data warehouse definition and practical advice to help you understand and establish a modern data warehouse.
A data warehouse is a data management system which aggregates large volumes of data from multiple sources into a single repository of highly structured and unified historical data. The centralized data in a warehouse is ready for use to support business intelligence (BI), data analysis, artificial intelligence, and machine learning needs to inform decision making and improve organizational performance.
Modern Data Warehousing
Historically, data warehouses were hosted on-premises, and since data was stored in a relational database, it had to be transformed before loading using the classic Extract, Transform, and Load (ETL) process. But as you’d expect, data warehousing systems continue to evolve with the surrounding data integration ecosystem.
With the rise of modern cloud architectures, larger datasets and the need to support real-time analytics and machine learning projects, warehouses are now typically hosted in the cloud and pipelines are shifting from ETL to Extract, Load, and Transform (ELT), streaming and API. Also, modern data warehouse automation allows you to create data models, add new sources, and provision new data marts without writing any SQL code.
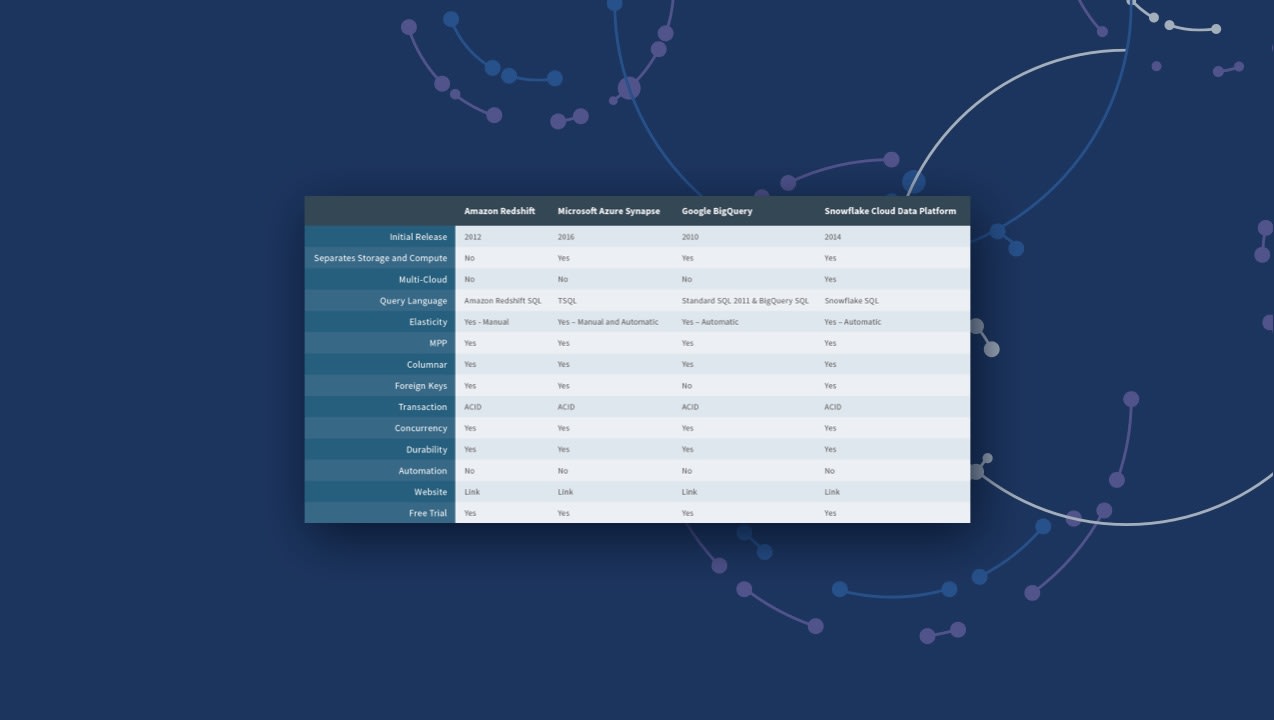
Modern cloud architectures combine three essentials: the power of data warehousing, flexibility of Big Data platforms, and elasticity of cloud at a fraction of the cost to traditional solution users. But which solution is the right one for you and your business? Download the eBook to see a side-by-side comparison of these leading vendors: Amazon vs. Azure vs. Google vs. Snowflake.
An enterprise data warehouse allows for decision making across your organization to happen faster and better than if you directly accessed disparate data stores. The major advantages are:
Better data quality. More trust. Data from a warehouse has been cleansed, de-duplicated, and standardized. This is true whether you use the traditional ETL pipeline, where data is transformed before loading into your warehouse, or the modern ELT approach where data is transformed in the warehouse as needed by a particular consumer. Having a consistent, “single source of truth” builds trust in the insights and decisions derived from any analysis.
Complete picture. Better, faster analysis. A warehouse aggregates and harmonizes data from a wide range of sources, such as operational databases, transactional systems, and flat files. This gives you a more complete picture of your business and allows you to leverage BI activities such as data mining, augmented analytics, and machine learning to find patterns you could easily miss with data silos. Also, accurate, complete data is available more quickly, so you can turn information into insight faster.
Architecture & Key Concepts
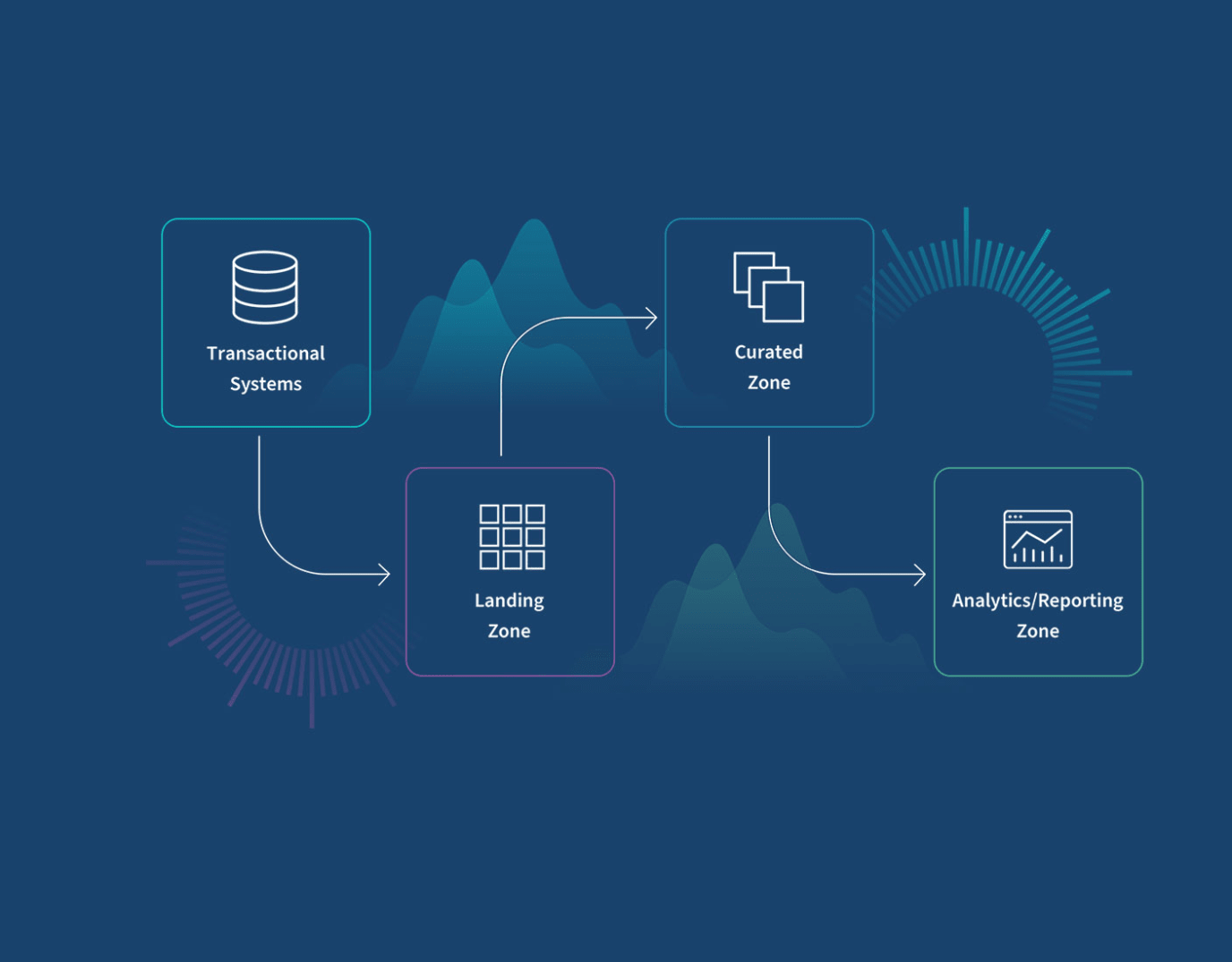
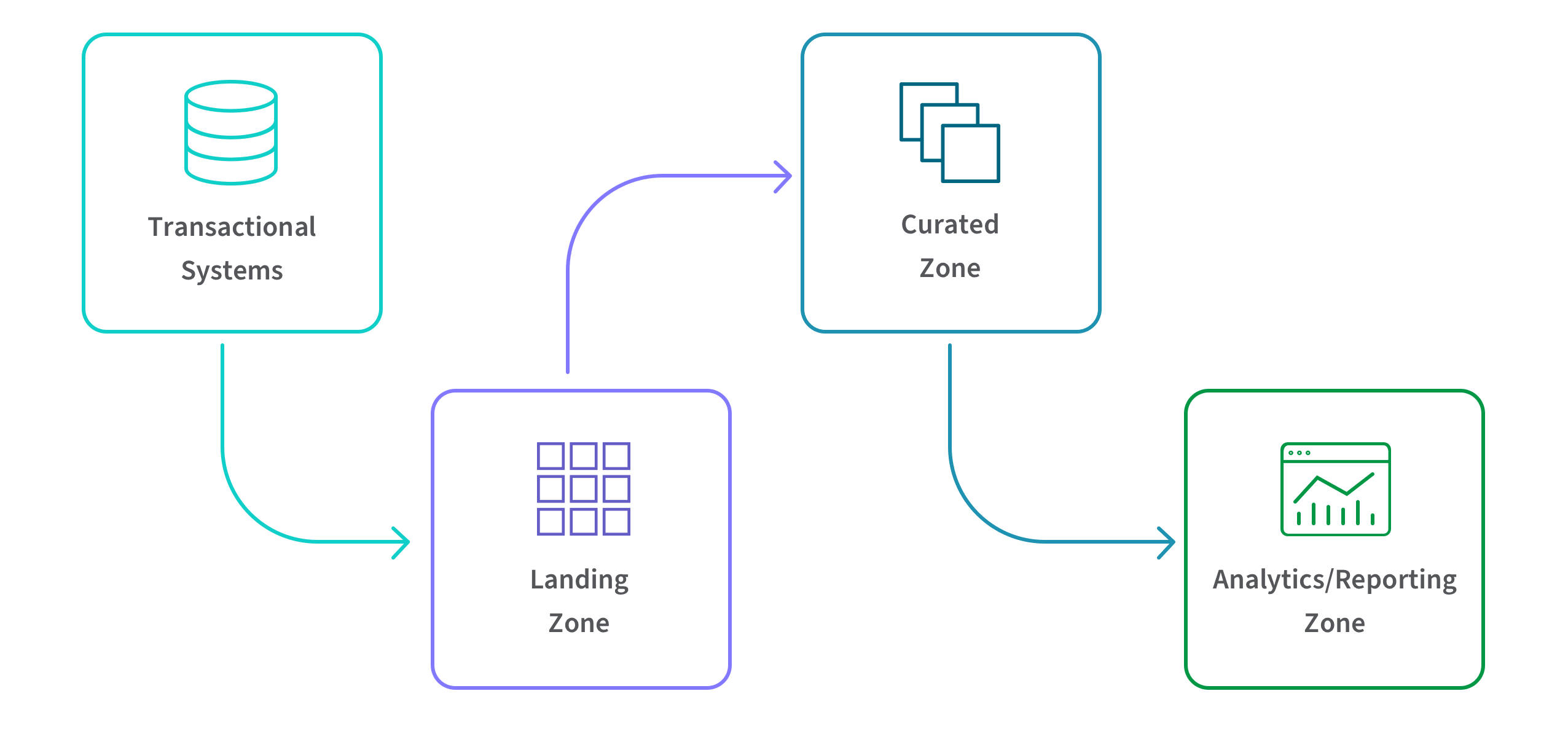
Your specific data warehouse architecture will be determined by your organization’s unique needs. Here’s a high-level diagram of the typical structure:
Generally, there are three zones. Data in the landing zone is structured as tables and mirrors the data from your transactional systems. Data in the curated zone conforms to a well-known methodology such as Data Vault, Inland or Kimble. Data in the analytics zone is typically housed in data marts and structured in star schemas where you’ll have a central fact such as the number of units sold and emanating from that fact are dimensions such as days, weeks, months, and years.
A key challenge in executing the above structure is that it requires you to write a lot of SQL code for each zone and for moving data between zones. As shown in the above video, data warehouse automation allows you to use visual tools to rapidly design, deploy, and manage your entire warehouse lifecycle without writing any code.
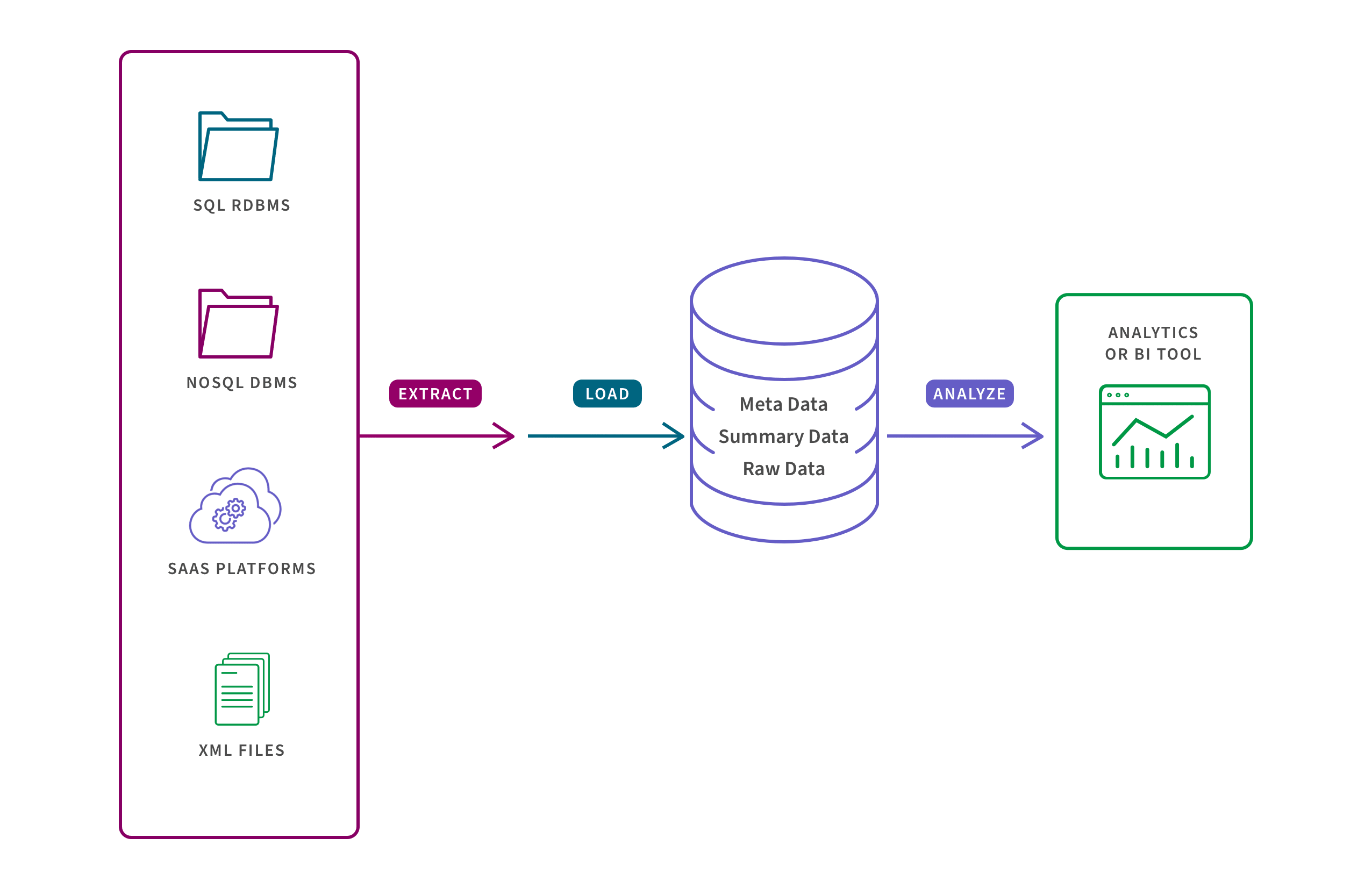
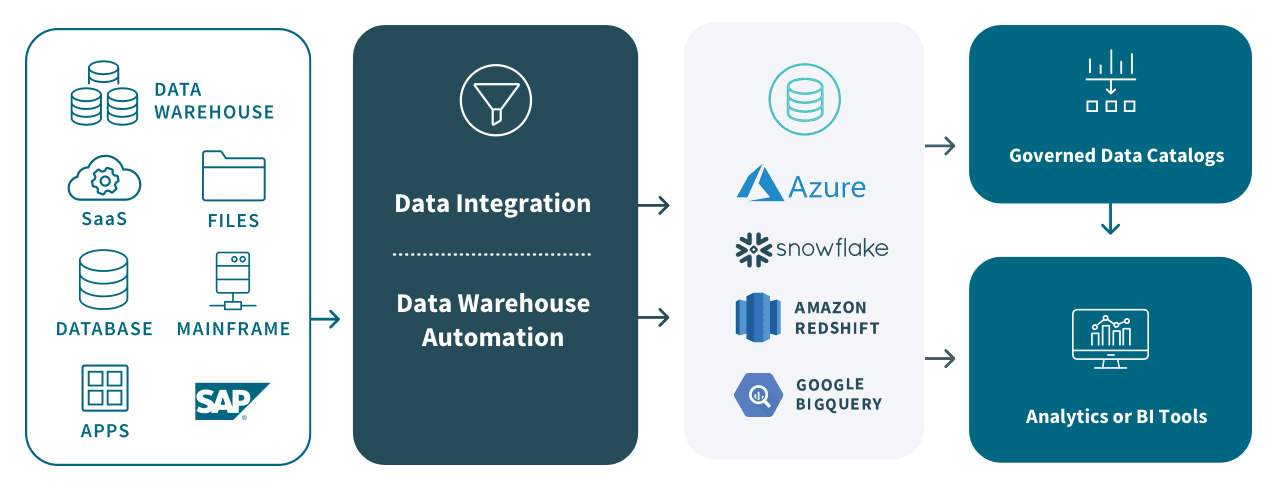
As shown above, a variety of data sources feed the warehouse using the Extract, Load, and Transform (ELT) process. Metadata, summary data, and raw data reside in the warehouse and consumers access this data using analytics or business intelligence tools. The enterprise data warehouse itself typically has a three-tier architecture as follows:
Top tier. This tier consists of a front-end user interface which allows you to perform ad hoc analysis and view reports.
Middle tier. This tier represents the analytics engine tier, usually an OLAP server, used to access and analyze your data.
Bottom tier. This tier involves the database server, usually a relational database system, where data is loaded and stored. As mentioned above, data cleansing and transformation can happen with either the ETL or ELT process.
Cloud architecture
Most often, today’s data warehouses reside in the cloud. The same benefits you find from the cloud in other areas of your work life—like lower cost, more computing power and more flexibility—also apply to data repositories. Cloud architectures bring the power of traditional warehouses but they also have the flexibility of big data platforms and the elasticity of the cloud (so you can scale your capacity up or down as needed). Plus, tools like Azure Synapse Analytics, Amazon Redshift, Google BigQuery and Snowflake come at a fraction of the cost of traditional on-premises solutions which usually involve a large up-front investment and lengthy deployment process.
An agile, cloud data warehouse brings three key productivity drivers:
A simple solution to support real-time data ingestion and updates.
An automated workflow with a model-driven approach to continually refine your warehouse operations.
An enterprise-scale data catalog to securely share your data marts.
Comparison Guide: Top Cloud Data Warehouses
Modern cloud architectures combine three essentials: the power of data warehousing, flexibility of Big Data platforms, and elasticity of cloud at a fraction of the cost to traditional solution users. But which solution is the right one for you and your business? Download the eBook to see a side-by-side comparison of these leading vendors: Amazon vs. Azure vs. Google vs. Snowflake.
Data Warehouse vs Data Mart, Database, and Data Lake
The terms data warehouse, data mart, database, and data lake should not be used interchangeably. Here we describe key differences between each.
Data warehouse vs data mart
A data mart contains a subset of warehouse data which is relevant to a specific subject or department in your organization such as finance or sales. Historically, data marts helped analysts or business managers perform analysis faster given that they were working with a smaller dataset. As shown below, they are added between the warehouse and the analytics tools.
Data warehouse vs database
A database usually serves as the primary, but limited data source for a specific application (as opposed to warehouses which contain massive data volume for all applications). The other key difference is that databases are tailored for running rapid queries and processing transactions, whereas warehouses best support BI and analytics. Databases perform much better than traditional warehouses at keeping real-time data up to date but modern cloud data warehouses can handle real-time data.
Many organizations use both warehouses and databases to cover their needs. Below is a side-by-side look at the two primary factors and how they can work in tandem for you.
FACTOR
DATA WAREHOUSE
DATABASE
Type of Data
Summarized historical (in traditional DW’s)
Detailed real-time
Use Case
Analyzing large, complex datasets
Recording transactions
Data warehouse vs data lake
A data lake stores all of your organization's data—both structured and unstructured data. So, a data lake is like a warehouse without the predefined schemas. As a result, it supports more types of analytics. Many organizations use both systems to accommodate their range of storage needs.
FACTOR
DATA WAREHOUSE
DATA LAKE
Type of Data
Typically structured data which has been transformed.
Raw, unstructured data.
Use Case
Business users analyzing large, complex datasets (data pre-structured to answer pre-determined questions).
Data scientists and engineers exploring raw data to uncover new business insights.
Analysis
Data visualization, BI, data analytics.
Predictive analytics, machine learning, data visualization, BI, big data analytics.
Cost
Higher cost than data lakes and require more time to manage.
Lower storage costs than a warehouse and less time-consuming to manage.
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.