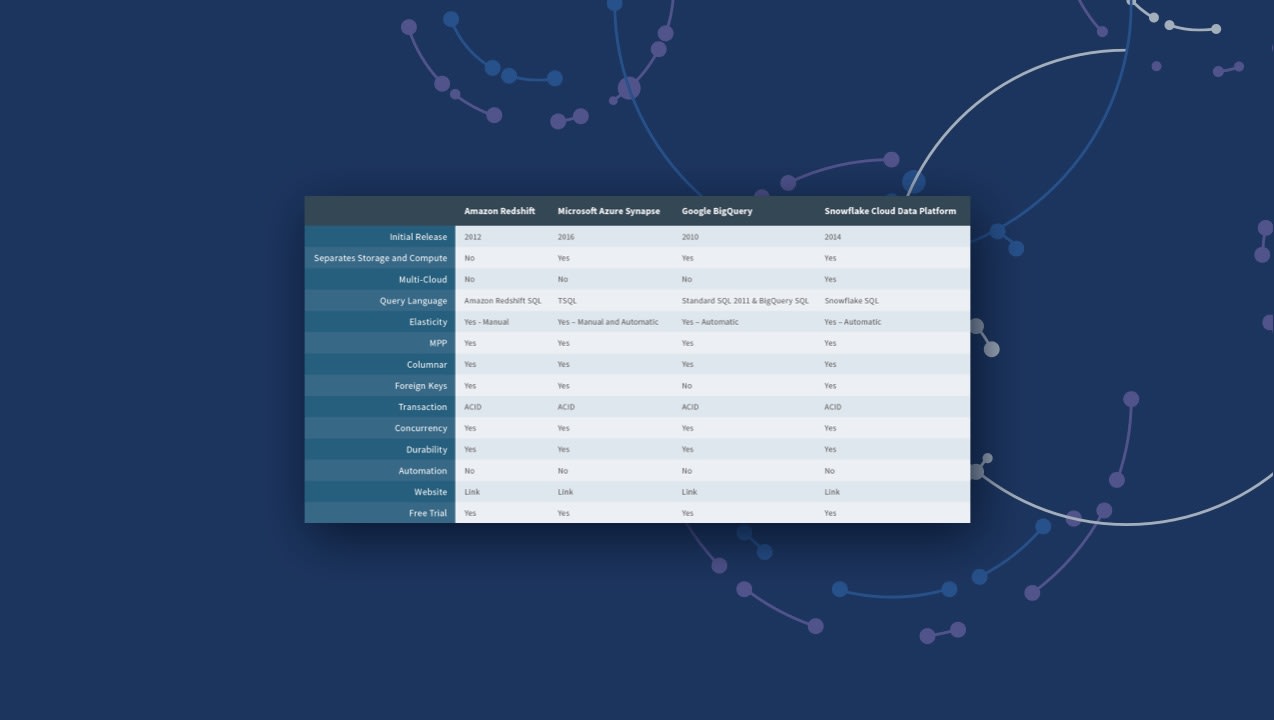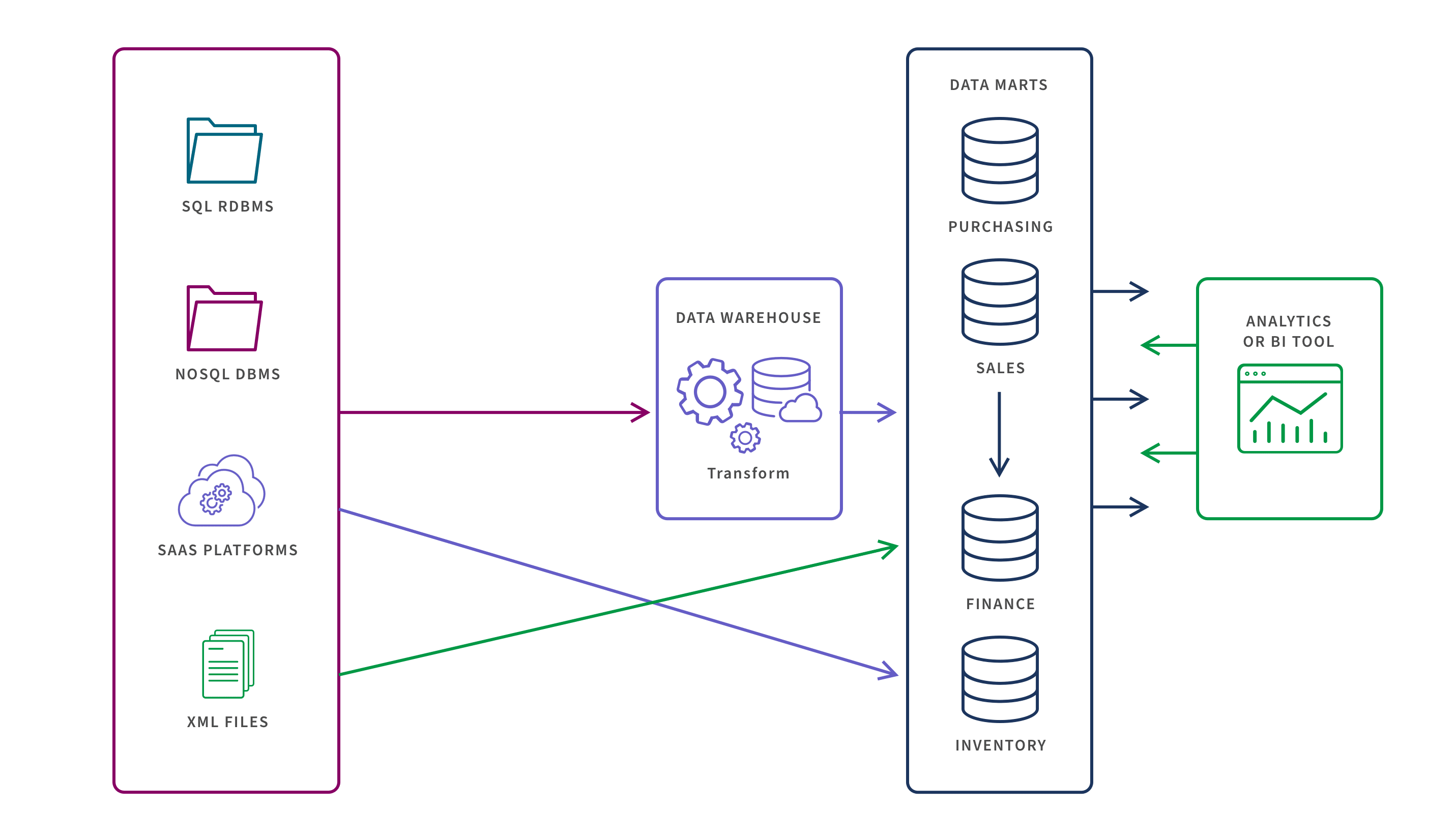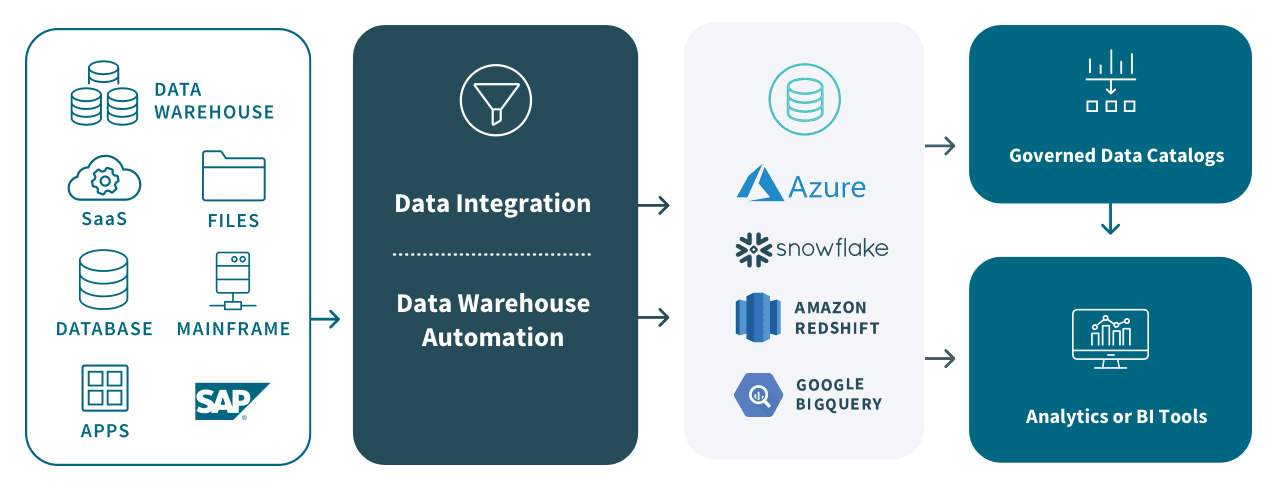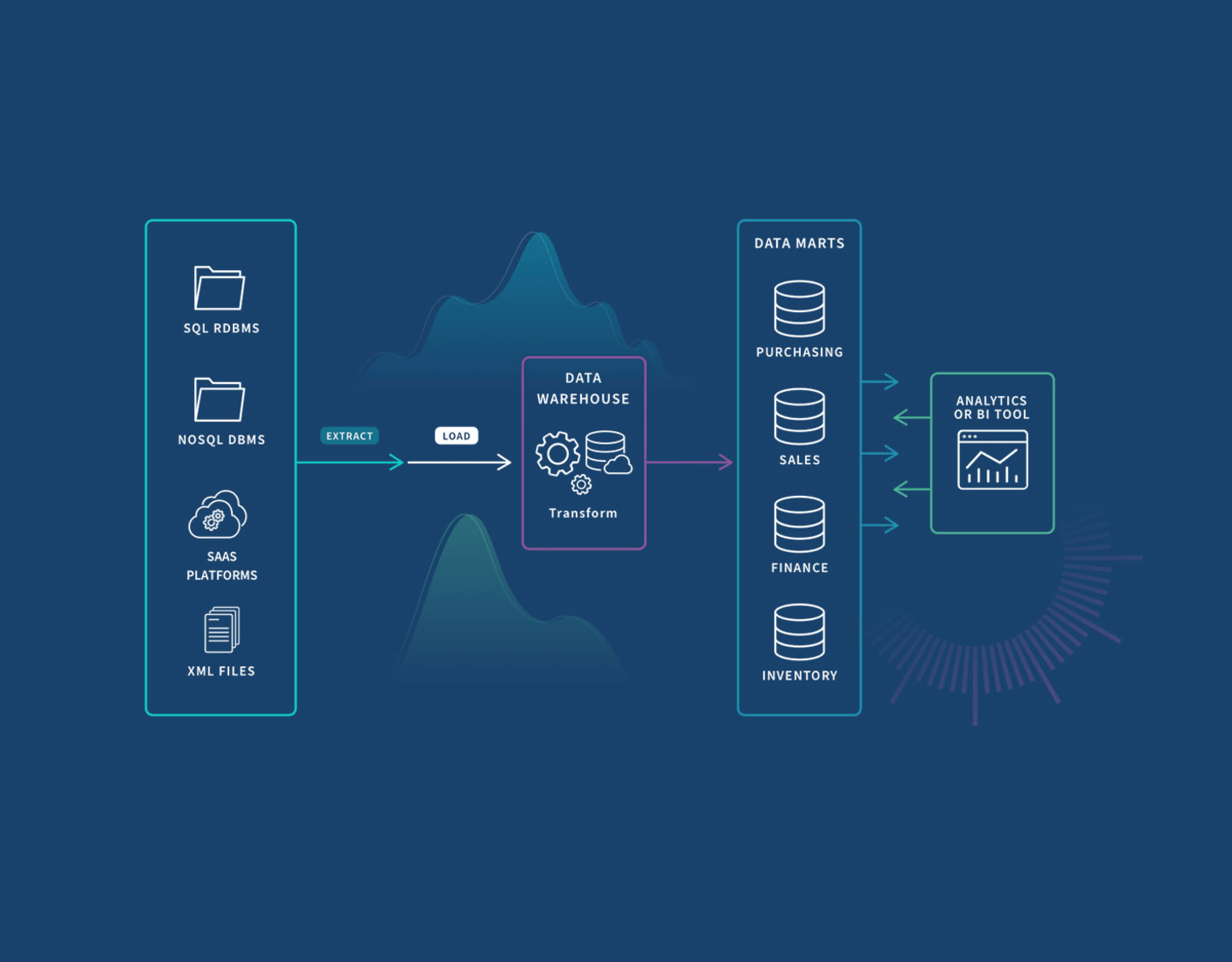
Data Mart Benefits
Your organization is likely flooded by massive, complex datasets from many sources, both historical data and real-time streaming data. All this big data typically lives in a data warehouse and users have to code complex queries to get the answers they seek.
But your teams need to make data-driven decisions quickly and confidently. This is where data marts come in. They’re an efficient approach which allows analytics and business users to explore and analyze more manageable subsets of data which are directly relevant to them. Here are the key benefits:
More trustworthy data. Data marts create a “single source of truth” regarding a certain subject or department. This gives your teams a collective view of the data and allows them to focus on finding insights, making decisions, and taking action rather than sharing spreadsheets and wondering which data is accurate.
Easier access to data. Since data marts hold a subset of data, you can access the data you need with less effort than dealing with a cluttered data warehouse. Plus, by establishing connections to the appropriate data sources, you can access live data anytime without waiting for IT to perform periodic extracts.
Faster insights & decisions. The focused nature of a data mart also allows you to more quickly leverage your analytics and business intelligence tools because you’re only working with a relevant, frequently needed data set.
Lower cost. Data marts typically cost far less to set up than establishing a full data warehouse.
Easier implementation & maintenance. Unlike data warehouses, which require integration with a wide variety of internal and external data sources, data marts only contain data essential to the particular business unit or department. This makes for faster and easier implementation and maintenance because you’re serving the needs of a specific business team rather than your entire organization.
Better support short-term projects. As noted above, you can quickly and cost-effectively establish a data mart, so they are well-suited for short-term data analysis projects such as determining the effectiveness of an advertising campaign.
Better data access control. Data in your mart is partitioned from the broader data warehouse. This gives you the ability to control data access privileges at a granular level.