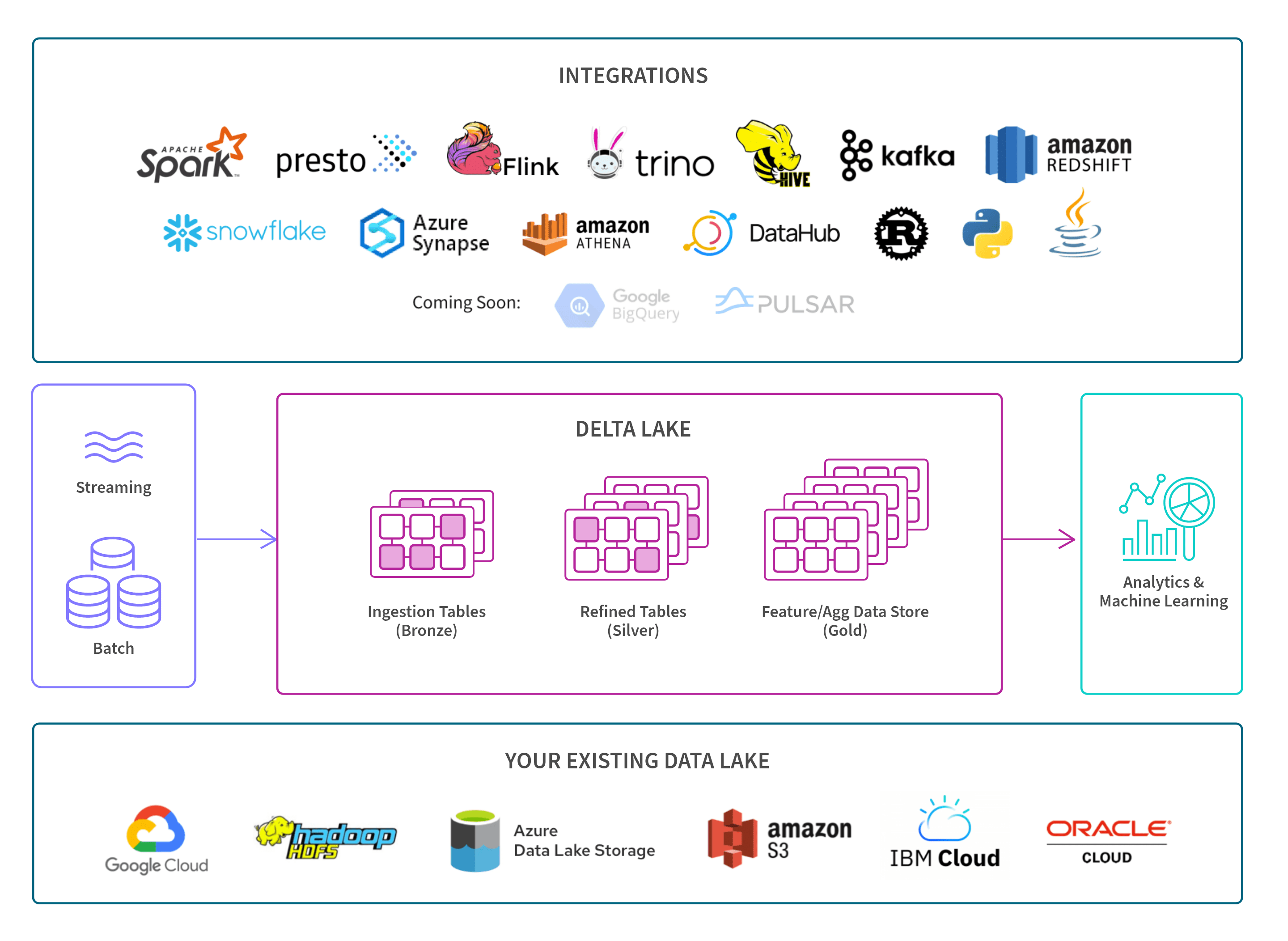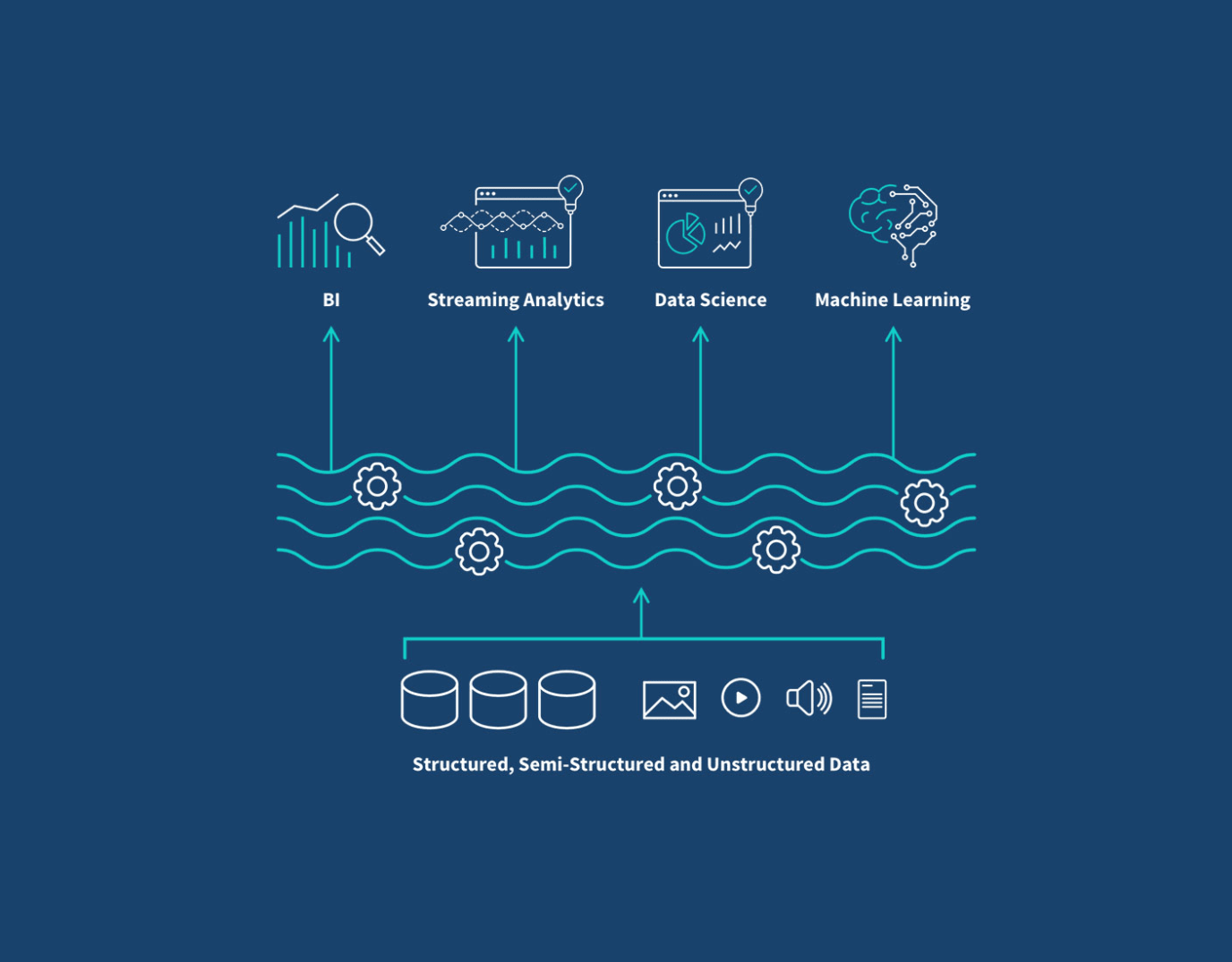
Data Lakehouse Features and Benefits
The lakehouse data platform ensures that data analysts and data scientists can apply the full and most recent data set toward business intelligence, big data analytics and machine learning. And having one system to manage simplifies the enterprise data infrastructure and allows analysts and scientists to work more efficiently.
Here we present the key features of data lakehouses and the benefits they bring to your organization.
FEATURE | BENEFIT |
|---|---|
Concurrent read & write transactions | Multiple users can concurrently read and write ACID-compliant transactions without compromising data integrity. |
Data warehouse schema architectures | This means lakehouses can standardize large datasets. |
Governance mechanisms | Having a single control point lets you better control publishing, sharing and user access to data. |
Open & standardized storage formats | Open formats facilitate broad, flexible and efficient data consumption from BI tools to programming languages such as Python and R. Many also support SQL. |
Separation of storage & processing | You can scale to larger datasets and have more concurrent users. Plus, these clusters run on inexpensive hardware, which saves you money. |
Support for diverse data types | This allows you to store, access, refine and analyze a broad range of data types and applications, such as IoT data, text, images, audio, video, system logs and relational data. |
Support for end-to-end streaming | This enables real-time reporting and analysis. Plus, you no longer need separate systems dedicated to serving real-time data apps. |
Single repository for many applications | This improves operational efficiency and data quality for business intelligence, ML and other workloads since you only have to maintain one data repository. |