Why It Matters
This 2-minute video describes the key data catalog concepts and benefits.
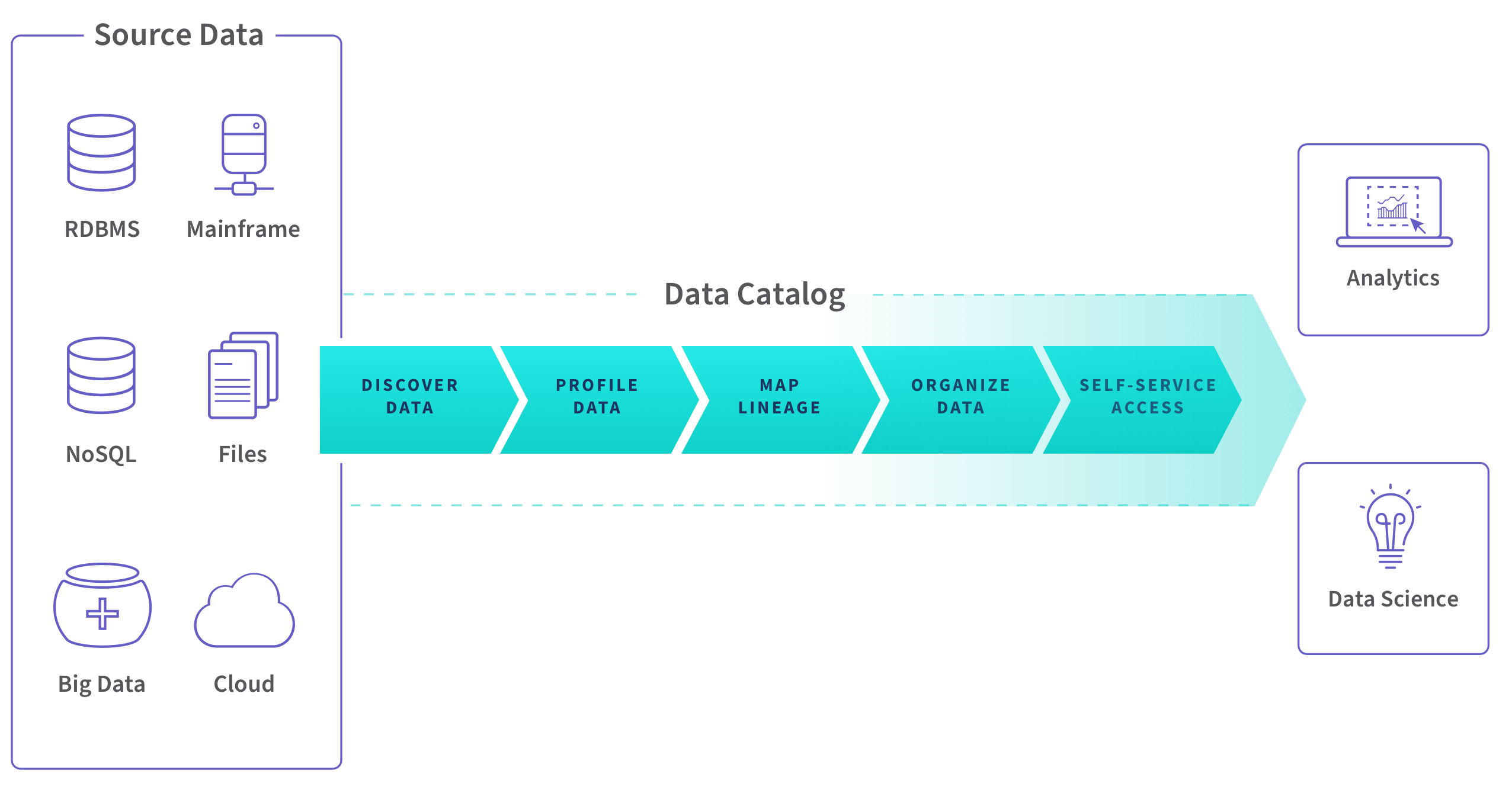
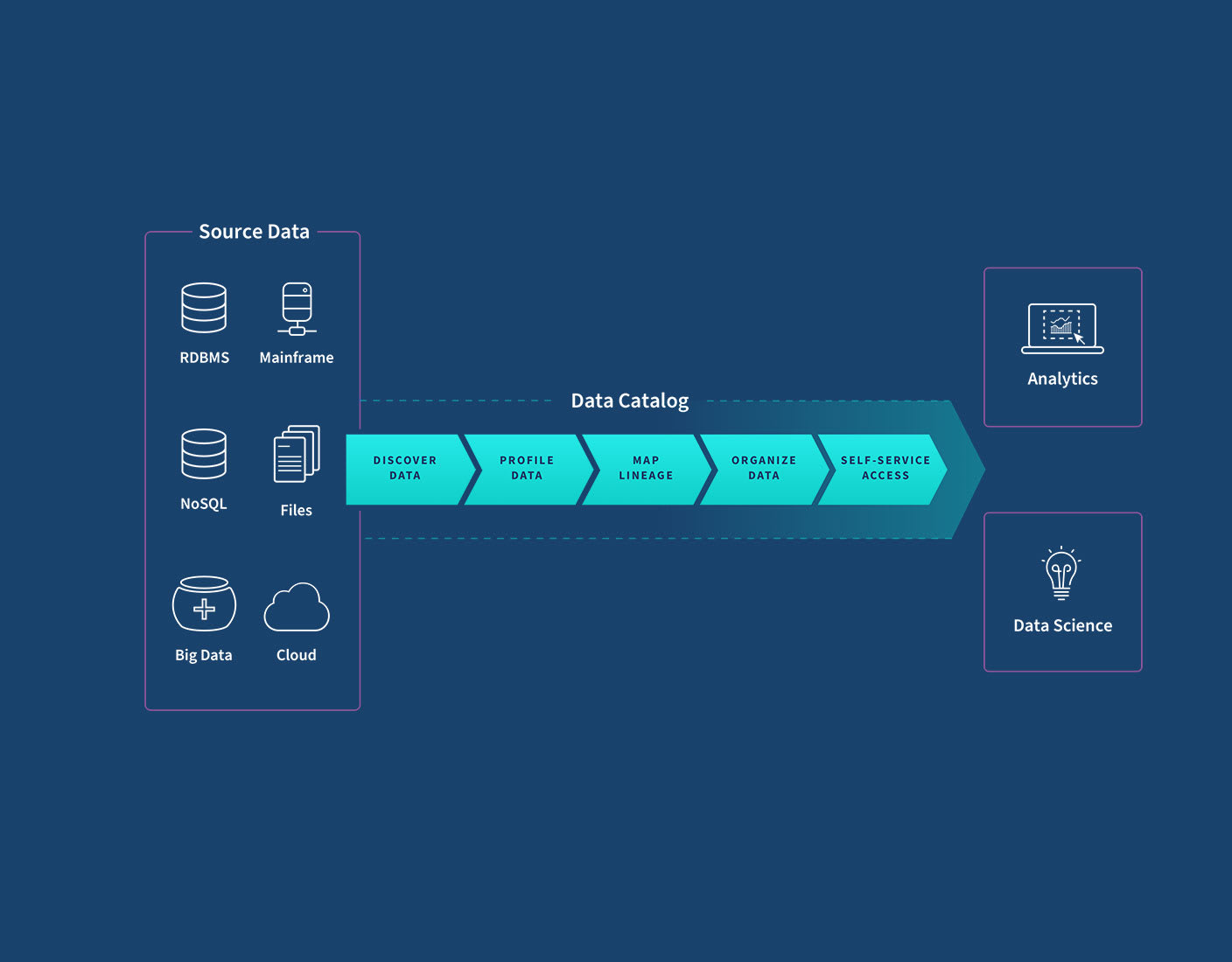
Why do you need a data catalog?
Your organization is likely flooded by large and complex datasets from many sources—financial systems, web analytics, ad platforms, CRM systems, marketing automation, partner data, and maybe even real time sources and IoT. Finding the right data and knowing you can trust it is a major challenge in the era of data lakes, big data, and self-service analytics.
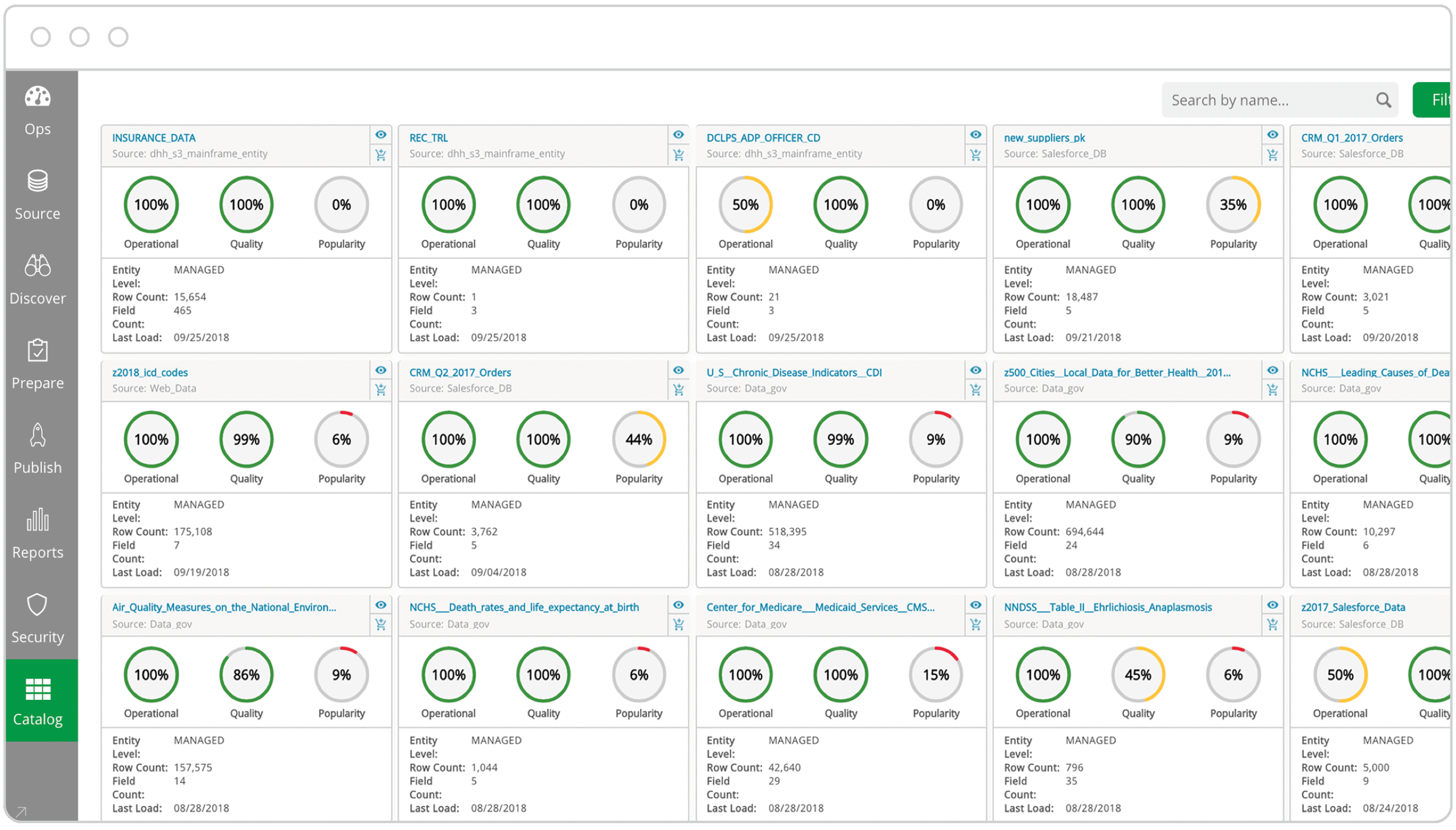
View business metadata and data lineage to improve understanding and trust.
Apply personalized tags, properties, and business metadata for greater utilization.
Browse dataset samples and profile statistics to ensure that data sets contain the expected information.