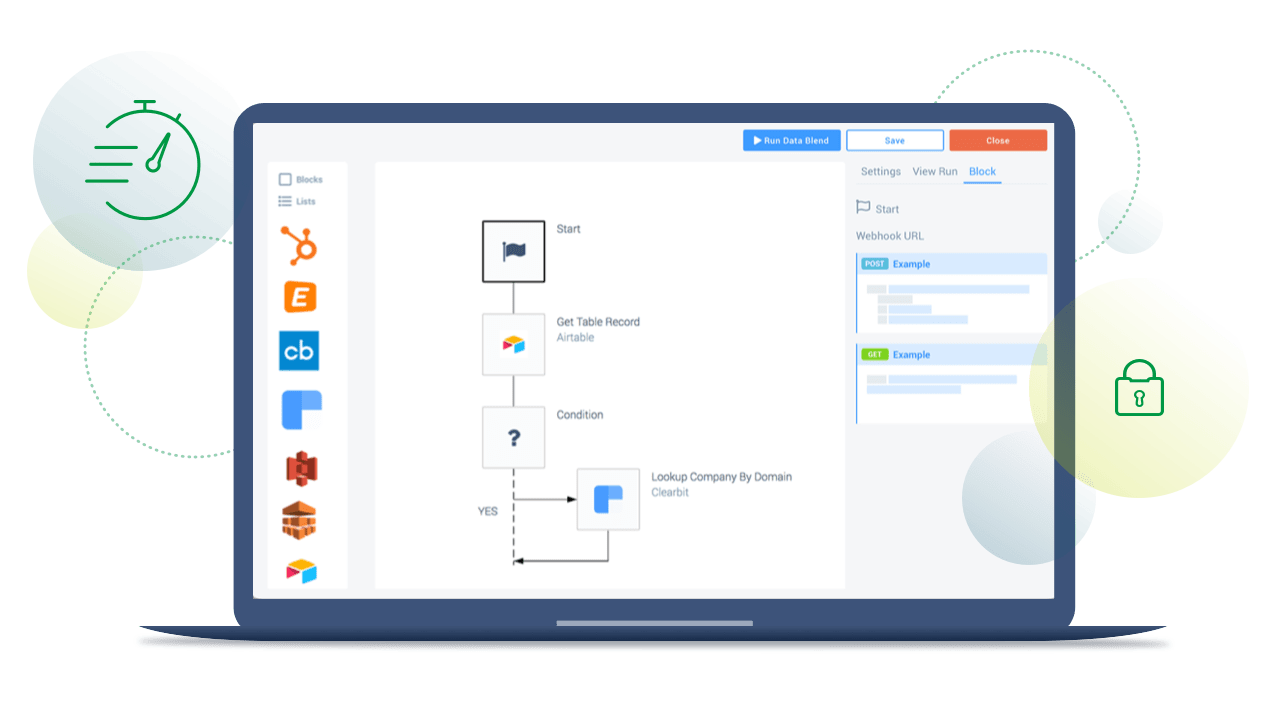
How It Works
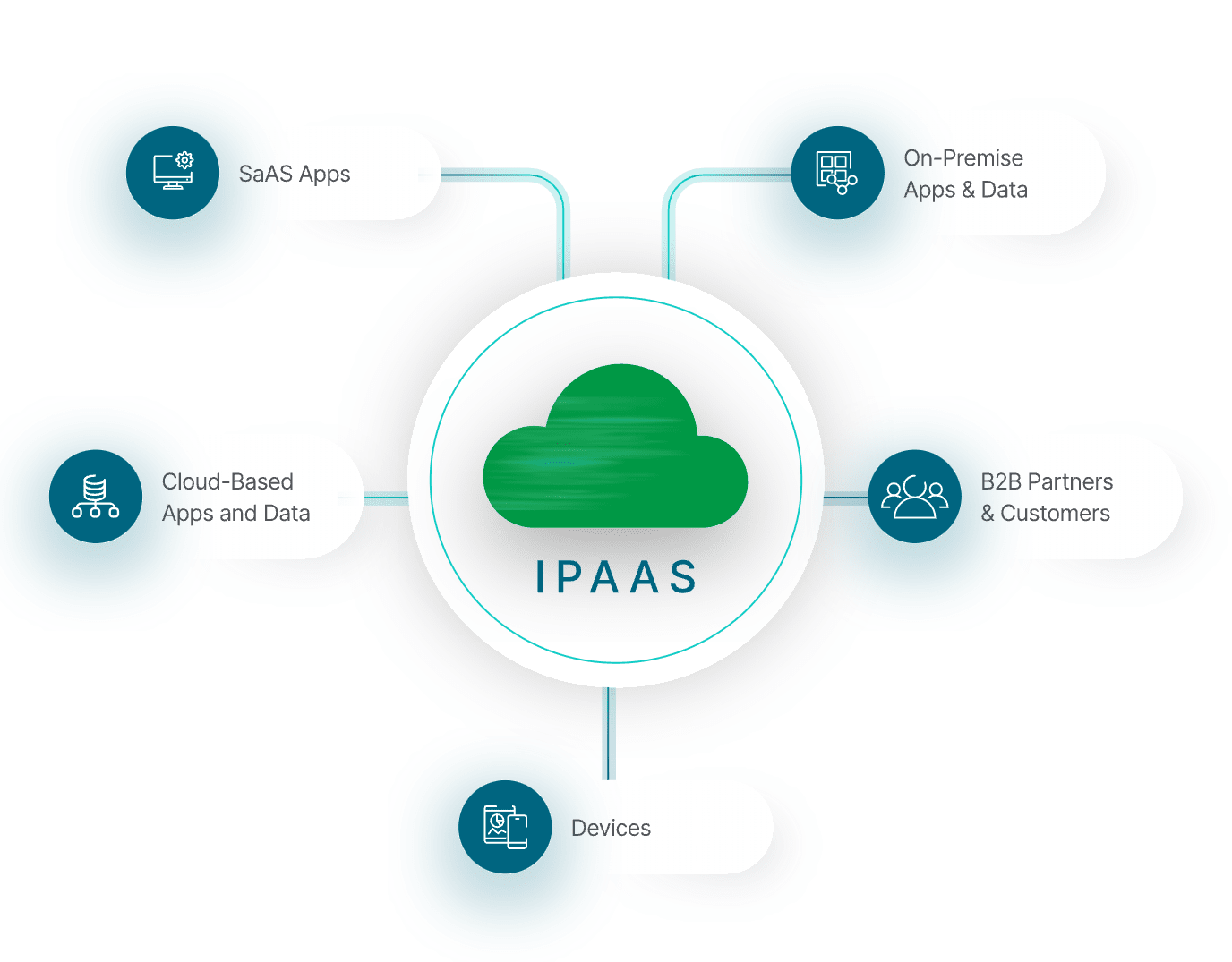
An iPaaS platform provides a single solution and process for integrating all of the systems in your organization such as SaaS apps, on-premise apps and data, external business partners, devices, and cloud-based apps and data.

SaaS & On-Premise Apps. An integration platform as a service typically provides a range of pre-built connectors and APIs that enable seamless communication between these disparate systems. For example, it may offer connectors to popular SaaS apps like Salesforce, Workday, and HubSpot, as well as to on-premise applications like SAP and Oracle.
In addition, it may offer data mapping and transformation tools that allow users to map data fields between different systems, ensuring that data is properly formatted and can be seamlessly transferred between systems.
B2B Partners. External business partners, such as suppliers or customers, can also be integrated into your cloud data integration ecosystem through secure APIs and data-sharing mechanisms. This allows for smoother collaboration and communication between partners, as well as the ability to share data and resources in real-time.
Devices, such as IoT sensors or smart devices, can also be integrated into your integration ecosystem through APIs that enable them to communicate with other systems and applications. This enables you to leverage data generated by these devices to drive insights and improve operations.
Cloud-based apps and data can be integrated into your cloud integration platform through APIs that enable seamless communication between cloud-based and on-premise systems. This allows for greater flexibility and scalability, as you can easily integrate new cloud-based services into their existing infrastructure.
And beyond integrating these systems, your iPaaS platform also provides for data governance, security, and software updates.