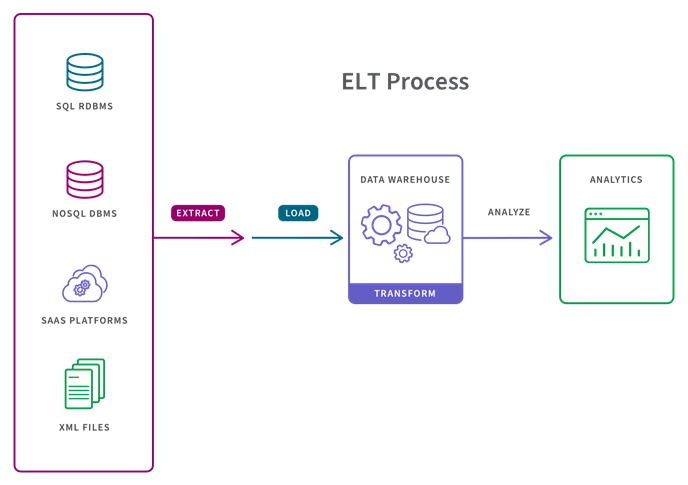
How ELT Works
ELT and cloud-based data warehouses and data lakes are the modern alternative to the traditional ETL pipeline and on-premises hardware approach to data integration. ELT and cloud-based repositories are more scalable, more flexible, and allow you to move faster.
The ELT process is broken out as follows:
Extract. A data extraction tool pulls data from a source or sources such as SQL or NoSQL databases, cloud platforms or XML files. This extracted data is often stored temporarily in a staging area in a database to confirm data integrity and to apply any necessary business rules.
Load. The second step involves placing the data into the target system, typically a cloud data warehouse, where it is ready to be analyzed by BI tools or data analytics tools.
Transform. Data transformation refers to converting the structure or format of a data set to match that of the target system. Examples of transformations include data mapping, replacing codes with values and applying concatenations or calculations.