









































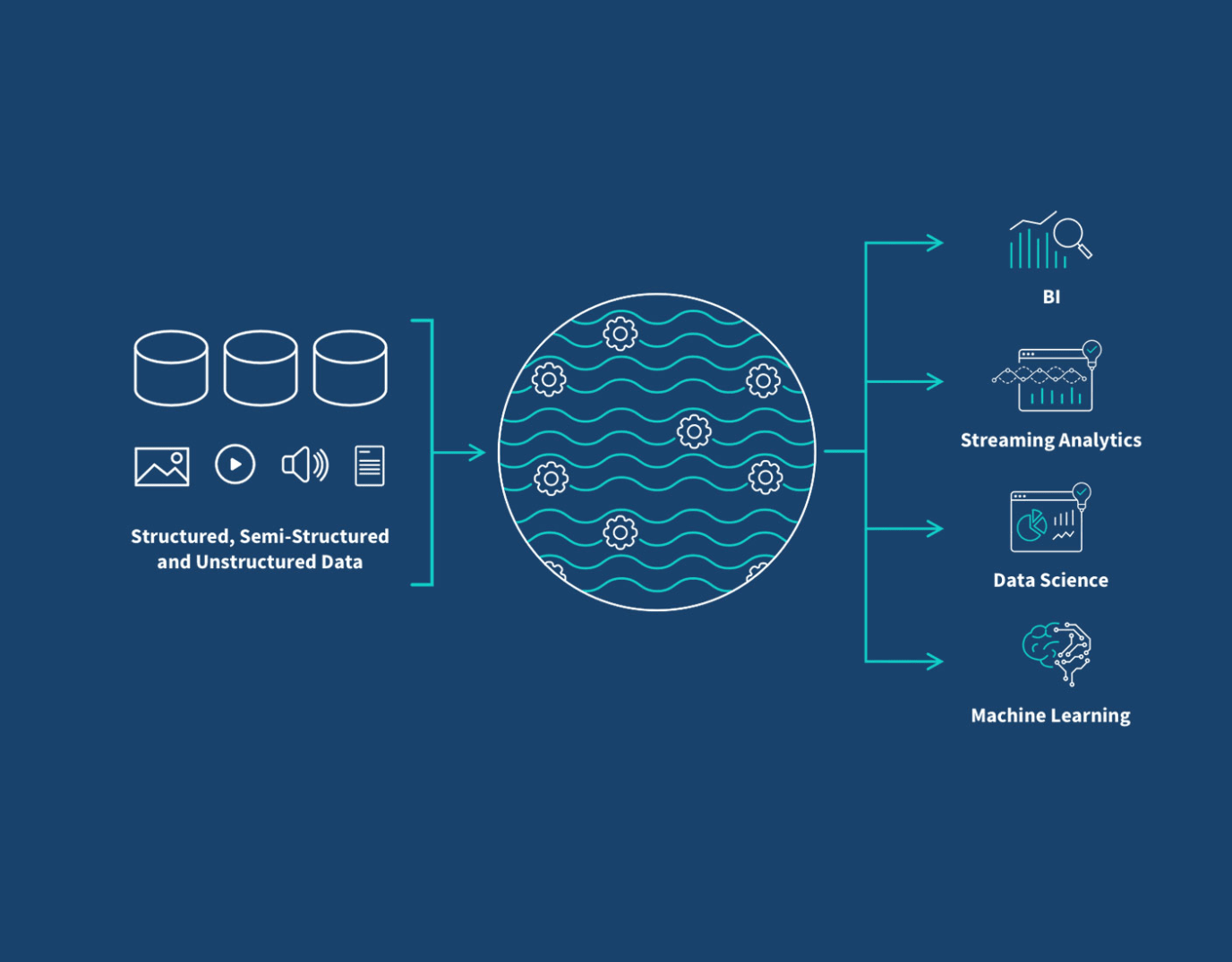
Data Lake Architecture
There are a number of different tools you can use to build and manage your data lake, such as Azure, Amazon S3 and Hadoop. Therefore, the detailed physical structure of your system will depend on which tool you select. Still, you can see below how it can fit into your overall data integration strategy.

Data teams can build ETL data pipelines and schema-on-read transformations to make data stored in a data lake available for data science and machine learning and for analytics and business intelligence tools. As we discuss below, managed data lake creation tools help you overcome the limitations of slow, hand-coded scripts and scarce engineering resources.
Many organizations today are adopting Delta Lake, an open-source storage layer that leverages ACID compliance from transactional databases to enhance reliability, performance, and flexibility in data lakes. It is particularly useful for scenarios requiring transactional capabilities and schema enforcement within your data lake. It enables the creation of data lakehouses, which support both data warehousing and machine learning directly on the data lake. Notably, it offers features such as scalable metadata handling, data versioning, and schema enforcement for large-scale datasets, ensuring data quality and reliability for analytics and data science tasks.

