A data pipeline is a set of tools and processes used to automate the movement and transformation of data between a source system and a target repository.
How It Works
This 2-minute video shows what a data pipeline is and how it makes transactional data available for analytics.
Source systems often have different methods of processing and storing data than target systems. Therefore, data pipeline software automates the process of extracting data from many disparate source systems, transforming, combining and validating that data, and loading it into the target repository.
In this way, building data pipelines breaks down data silos and creates a single, complete picture of your business. You can then apply BI and analytics tools to create data visualizations and dashboards to derive and share actionable insights from your data.
Data Pipeline vs ETL
The terms “data pipeline” and “ETL pipeline” should not be used synonymously. The term data pipeline refers to the broad category of moving data between systems, whereas an ETL pipeline is a specific type of data pipeline.
AWS Data Pipeline
AWS data pipeline is a web service offered by Amazon Web Services (AWS). This service allows you to easily move and transform data within the AWS ecosystem, such as archiving Web server logs to Amazon S3 or generating traffic reports by running a weekly Amazon EMR cluster over those logs.
Top 4 Strategies for Automating Your Data Pipeline
Data integration is the process of bringing together data from multiple sources to provide a complete and accurate dataset for business intelligence (BI), data analysis and other applications and business processes.
The needs and use cases of these analytics, applications and processes can be split into two primary categories: historical data or real-time data.
So, it makes sense to categorize pipelines in the same way.
1) Batch processing: historical data
Historical data is typically used in BI and data analytics to explore, analyze and gain insights on activities and information that has happened in the past. Therefore, traditional batch processing where data is periodically extracted, transformed, and loaded to a target system is sufficient. These batches can either be scheduled to occur automatically, can be triggered by a user query or by an application. Batch processing enables complex analysis of large datasets.
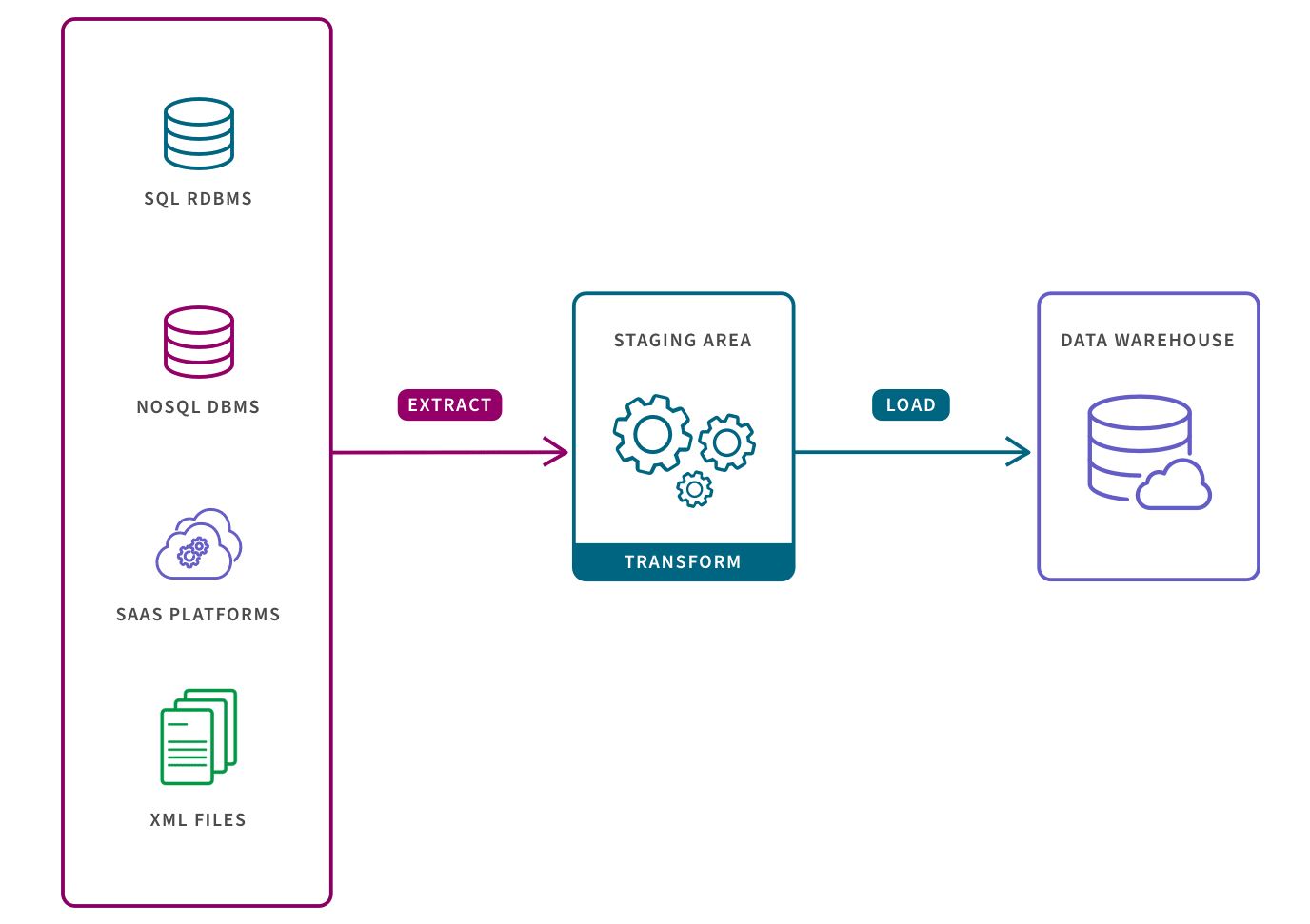
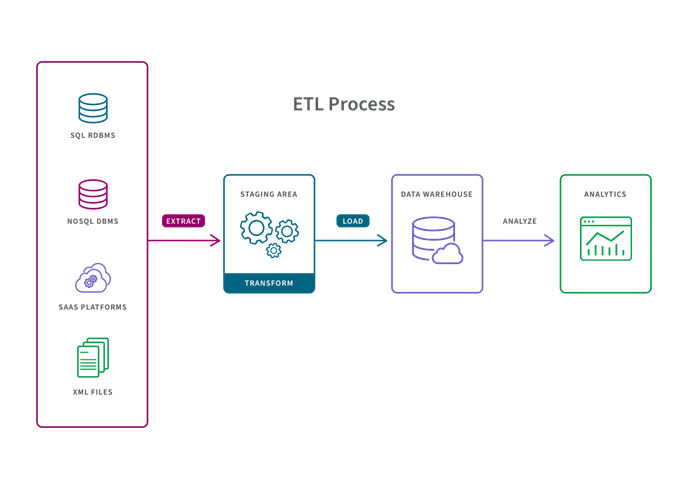
ETL pipelines can support use cases that can rely on historical data, and are especially appropriate for small data sets which require complex transformations. Converting raw data to match the target system before it is loaded, allows for systematic and accurate data analysis in the target repository. ETL is an acronym for “Extract, Transform, and Load” and describes the three stages of this pipeline:
Extract: pulling raw data from a source (such as a database, an XML file or a cloud platform holding data for systems such as marketing tools, CRM systems, or transactional systems)
Transform: converting the format or structure of the dataset to match that of the target system
Load: placing the dataset into the target system which can be an application or a database, data lakehouse, data lake or data warehouse.
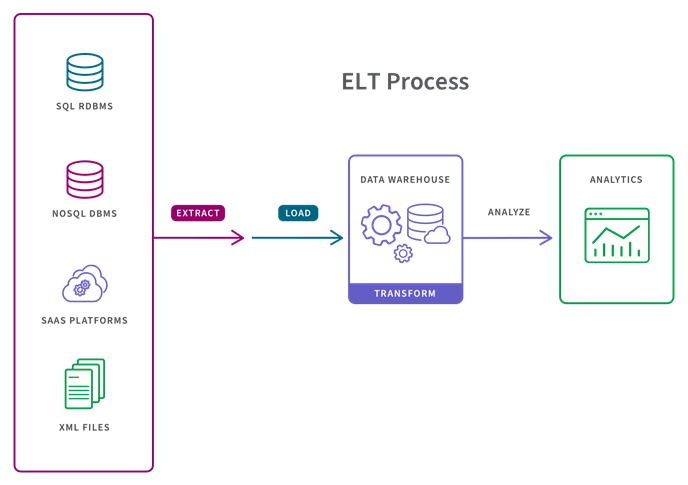
Streaming data pipelines are used when the analytics, application or business process requires continually flowing and updating data. Instead of loading data in batches, streaming pipelines move data continuously in real-time from source to target. For large, unstructured data sets and when timeliness is important, the ELT process is more appropriate (“Extract, Load, and Transform”) than ETL.
The key benefits of streaming pipelines is that users can analyze or report on their complete dataset, including real-time data, without having to wait for IT to extract, transform and load more data. Plus, there is lower cost and lower maintenance than batch-oriented pipelines. Cloud-based platforms offer much lower costs to store and process data and the ELT process typically requires low maintenance given that all data is always available and the transformation process is usually automated and cloud-based.
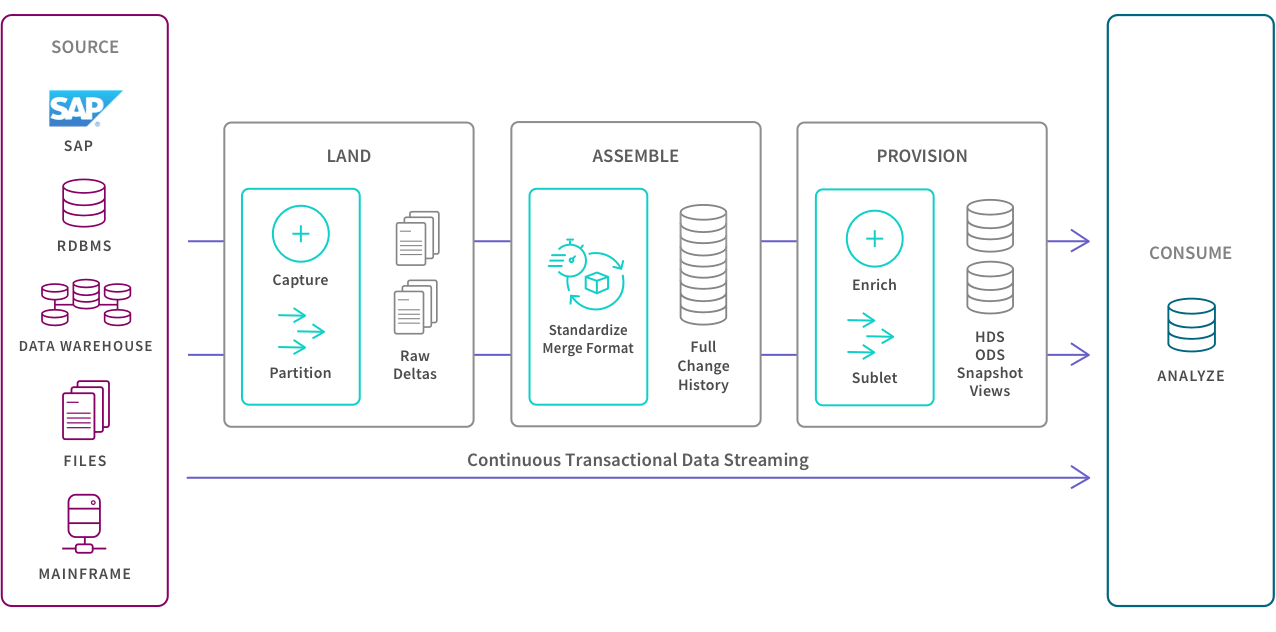
Below is a data pipeline architecture supporting a transactional system which requires the real-time ingestion and transformation of data and then the updating of KPIs and reports with every new transaction as it happens:
Apache Kafka is an open-source data store which is optimized for ingesting and transforming real-time streaming data. Kafka is scalable because it allows data to be distributed across multiple servers, and it’s fast because it decouples data streams, which results in low latency. Kafka can also distribute and replicate partitions across many servers, which protects against server failure.
As stated above, the term “data pipeline” refers to the broad set of all processes in which data is moved between systems, even with today’s data fabric approach. ETL pipelines are a particular type of data pipeline. Below are three key differences between the two:
First, data pipelines don’t have to run in batches. ETL pipelines usually move data to the target system in batches on a regular schedule. But certain data pipelines can perform real-time processing with streaming computation, which allows data sets to be continuously updated. This supports real-time analytics and reporting and can trigger other apps and systems.
Second, data pipelines don’t have to transform the data. ETL pipelines transform data before loading it into the target system. But data pipelines can either transform data after loading it into the target system (ELT) or not transform it at all.
Third, data pipelines don’t have to stop after loading the data. ETL pipelines end after loading data into the target repository. But data pipelines can stream data, and therefore their load process can trigger processes in other systems or enable real-time reporting.
Data Integration Challenges & Solutions
Learn how to overcome the top 14 challenges you face.