









































What is Metadata?
Metadata describes technical, business, or operational aspects of other data. This provides you context so you can find the information you need more easily and use your data more effectively.
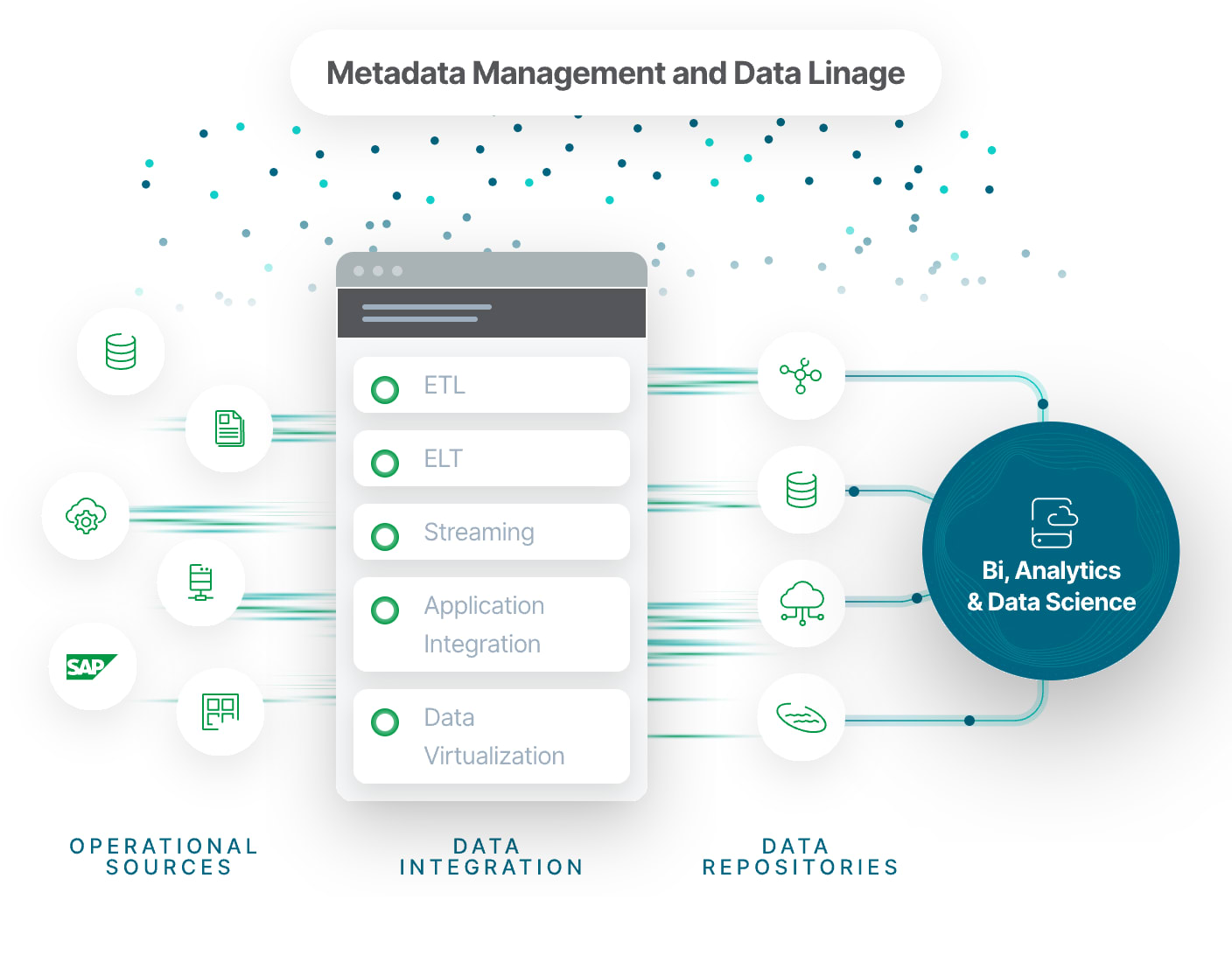
What is “other data”? By other data, we mean a collection of facts which represent measurements or descriptions of a situation. These facts can be in the form of numbers, symbols or words and are typically stored digitally. This source data, or raw data, is the facts in the original form and structure that they were collected. For analysis to happen, this raw data needs to be transformed into clean, business ready information through data integration.
Now let’s get back to defining metadata. To help you to find, understand, and access the information you need, this “other data” needs to have metadata associated with it. The metadata identifies other data and gives it context by providing core information about it, such as author, creation time, file size, file type, topic, etc.
There are three main types of metadata:
Structural metadata describes relationships among different parts of a data set and is often used to support machine processing.
Descriptive metadata describes attributes such as author, topic, and title which aids in identification and discovery of information assets.
Administrative metadata describes the technical source or lineage of a data asset and how the data is used including elements such as creation time, file size, and file type but also usage rights, intellectual property, and use duration.
There are two ways to create metadata:
Manual creation is labor-intensive but allows you to include more details. This approach is recommended for high-value, low volume data sets.
Automatic creation, sometimes referred to as active metadata management, allows you to process massive volumes of data by leveraging machine learning. However, this approach can limit the amount of details you add.

