









































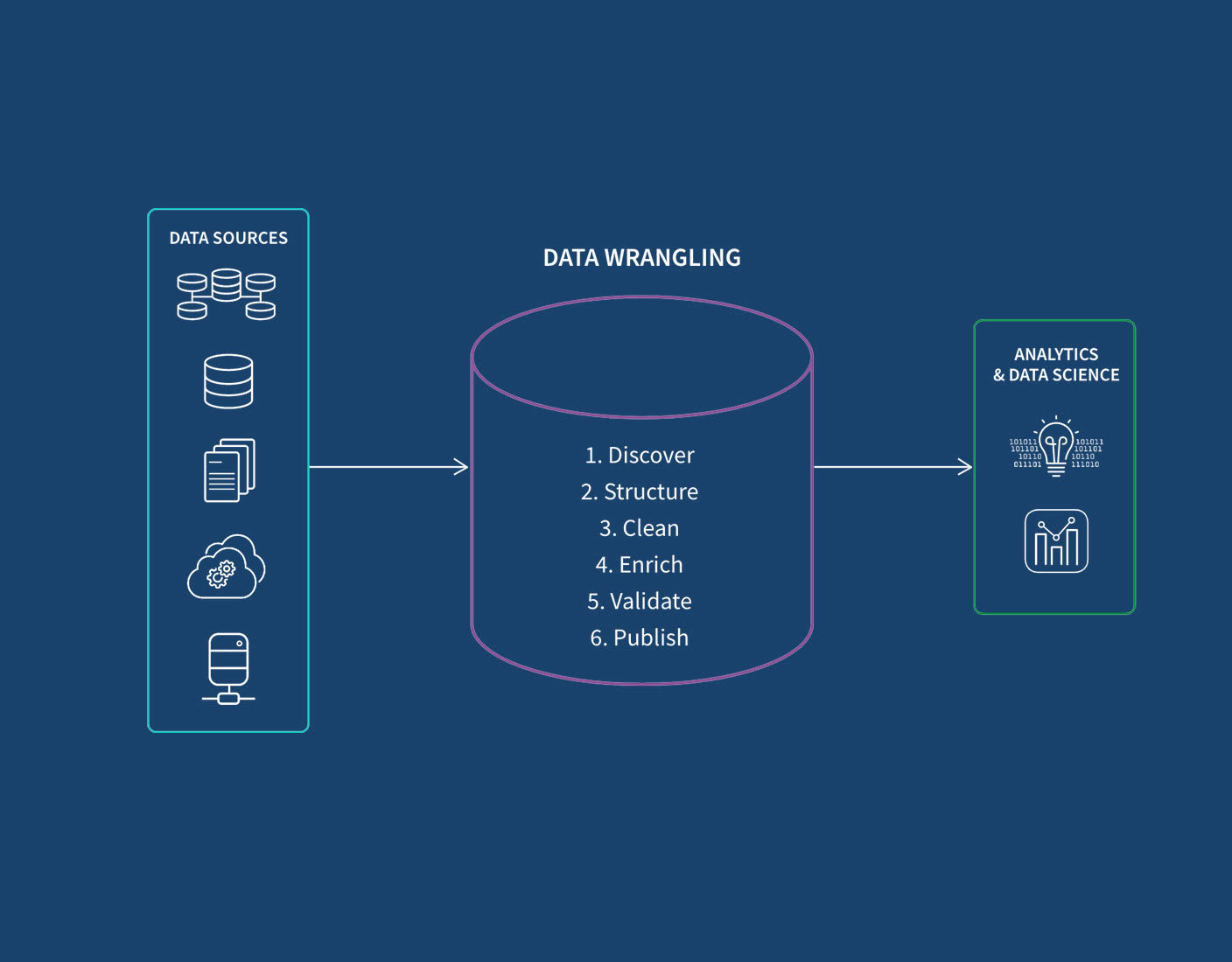
Data Wrangling Process
Wrangling data involves the systematic and iterative transformation of raw, unstructured, or messy data into a clean, structured, and usable format for data science and analytics.
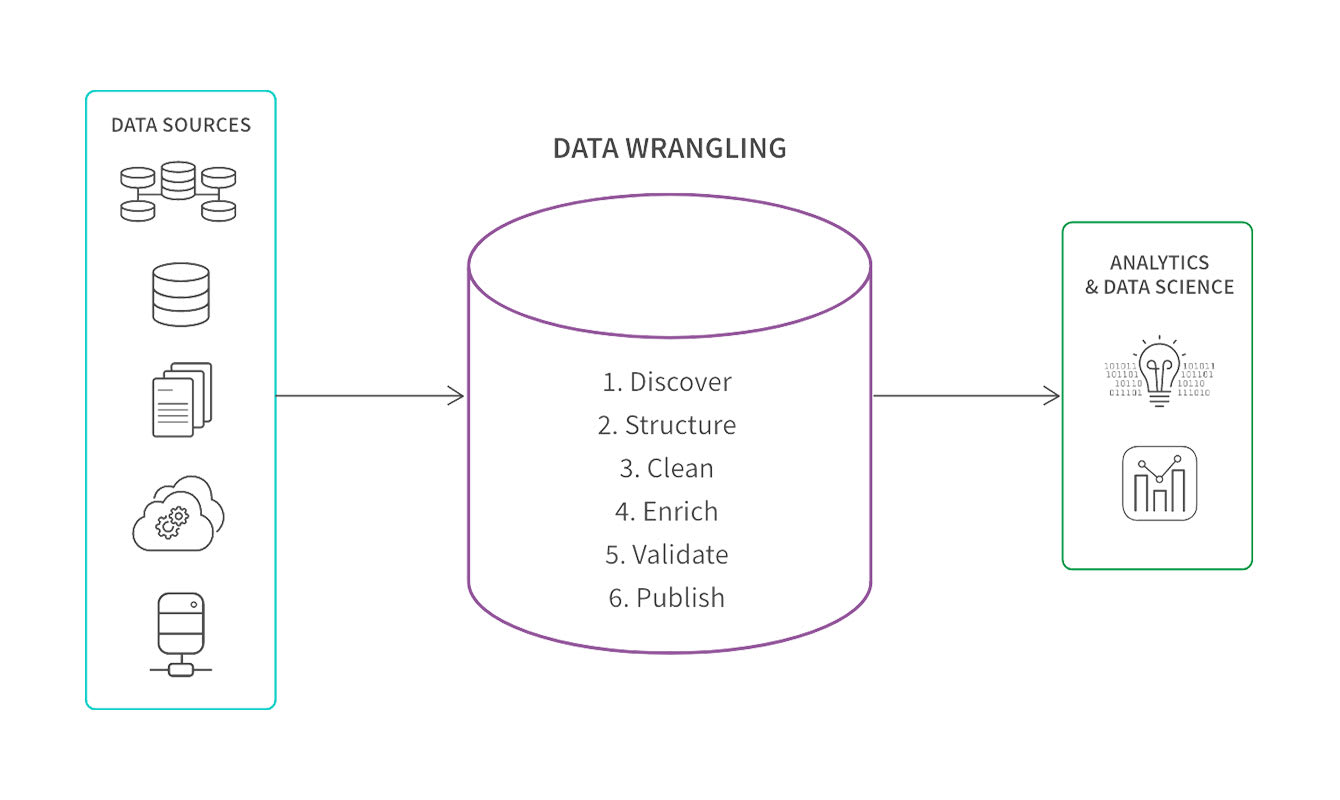
Here we describe the 6 key steps:
Step 1: Discover
Initially, your focus is on understanding and exploring the data you’ve gathered. This involves identifying data sources, assessing data quality, and gaining insights into the structure and format of the data. Your goal is to establish a foundation for the subsequent data preparation steps by recognizing potential challenges and opportunities in the data.
Step 2: Structure
In the data structuring step, you organize and format the raw data in a way that facilitates efficient analysis. The specific form your data will take depends on which analytical model you’re using, but structuring typically involves reshaping data, handling missing values, and converting data types. This ensures that the data is presented in a coherent and standardized manner, laying the groundwork for further manipulation and exploration.
Step 3: Clean
Data cleansing is a crucial step to address inconsistencies, errors, and outliers within the dataset. This involves removing or correcting inaccurate data, handling duplicates, and addressing any anomalies that could impact the reliability of analyses. By cleaning the data, your focus is on enhancing data accuracy and reliability for downstream processes.
Step 4: Enrich
Enriching your data involves enhancing it with additional information to provide more context or depth. This can include merging datasets, extracting relevant features, or incorporating external data sources. The goal is to augment the original dataset, making it more comprehensive and valuable for analysis. If you do add data, be sure to structure and clean that new data.
Step 5: Validate
Validation ensures the quality and reliability of your processed data. You’ll check for inconsistencies, verify data integrity, and confirm that the data adheres to predefined standards. Validation helps in building your confidence in the accuracy of the dataset and ensures that it meets the requirements for meaningful analysis.
Step 6: Publish
Now your curated and validated dataset is prepared for analysis or dissemination to business users. This involves documenting data lineage and the steps taken during the entire wrangling process, sharing metadata, and preparing the data for storage or integration into data science and analytics tools. Publishing facilitates collaboration and allows others to use the data for their analyses or decision-making processes.



