How It Works
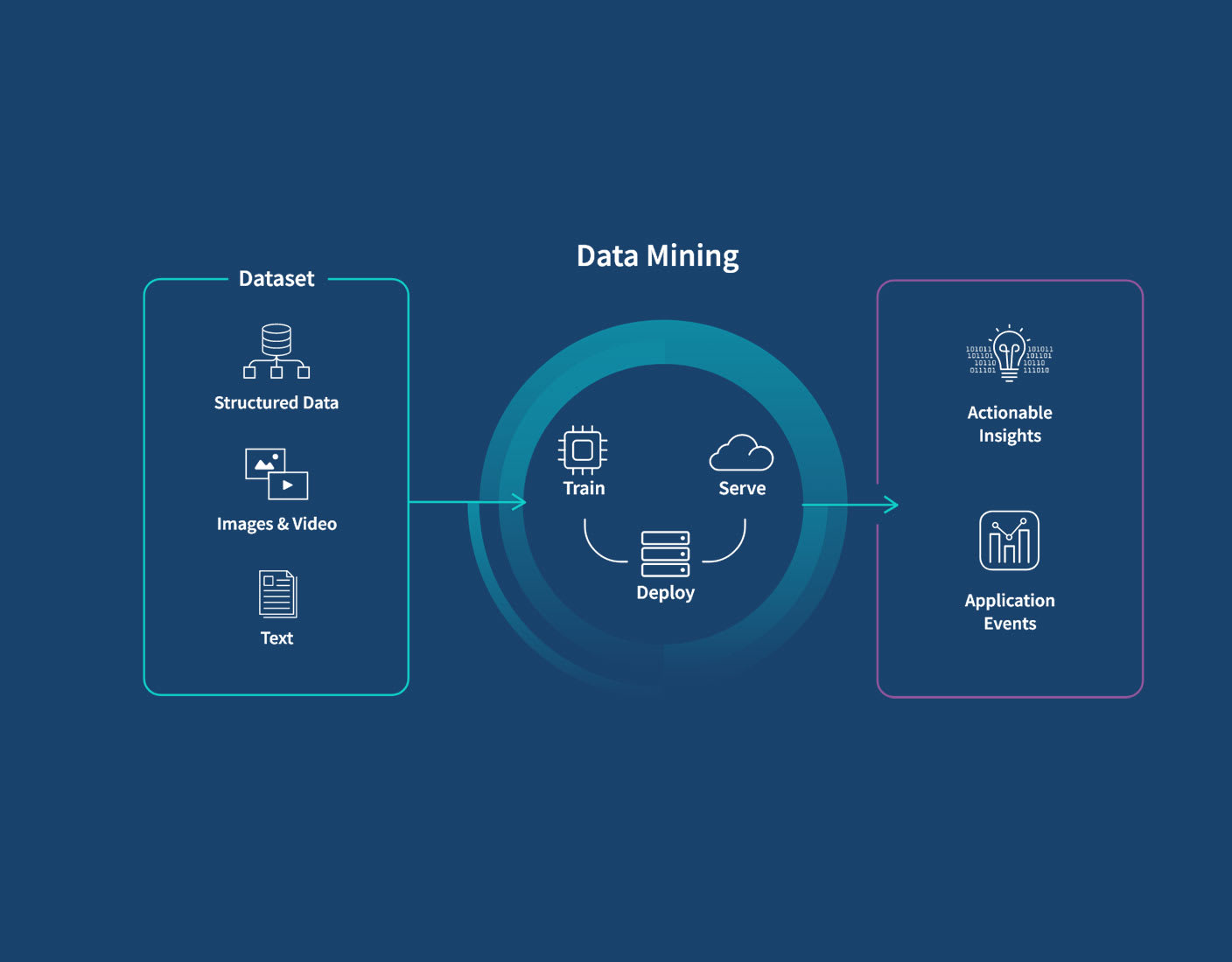
Data mining can be seen as a subset of data analytics that specifically focuses on extracting hidden patterns and knowledge from data. Historically, a data scientist was required to build, refine, and deploy models. However, with the rise of AutoML tools, data analysts can now perform these tasks if the model is not too complex.
The data mining process may vary depending on your specific project and the techniques employed, but it typically involves the 10 key steps described below.

1. Define Problem. Clearly define the objectives and goals of your data mining project. Determine what you want to achieve and how mining data can help in solving the problem or answering specific questions.
2. Collect Data. Gather relevant data from various sources, including databases, files, APIs, or online platforms. Ensure that the collected data is accurate, complete, and representative of the problem domain. Modern analytics and BI tools often have data integration capabilities. Otherwise, you’ll need someone with expertise in data management to clean, prepare, and integrate the data.
3. Prep Data. Clean and preprocess your collected data to ensure its quality and suitability for analysis. This step involves tasks such as removing duplicate or irrelevant records, handling missing values, correcting inconsistencies, and transforming the data into a suitable format.
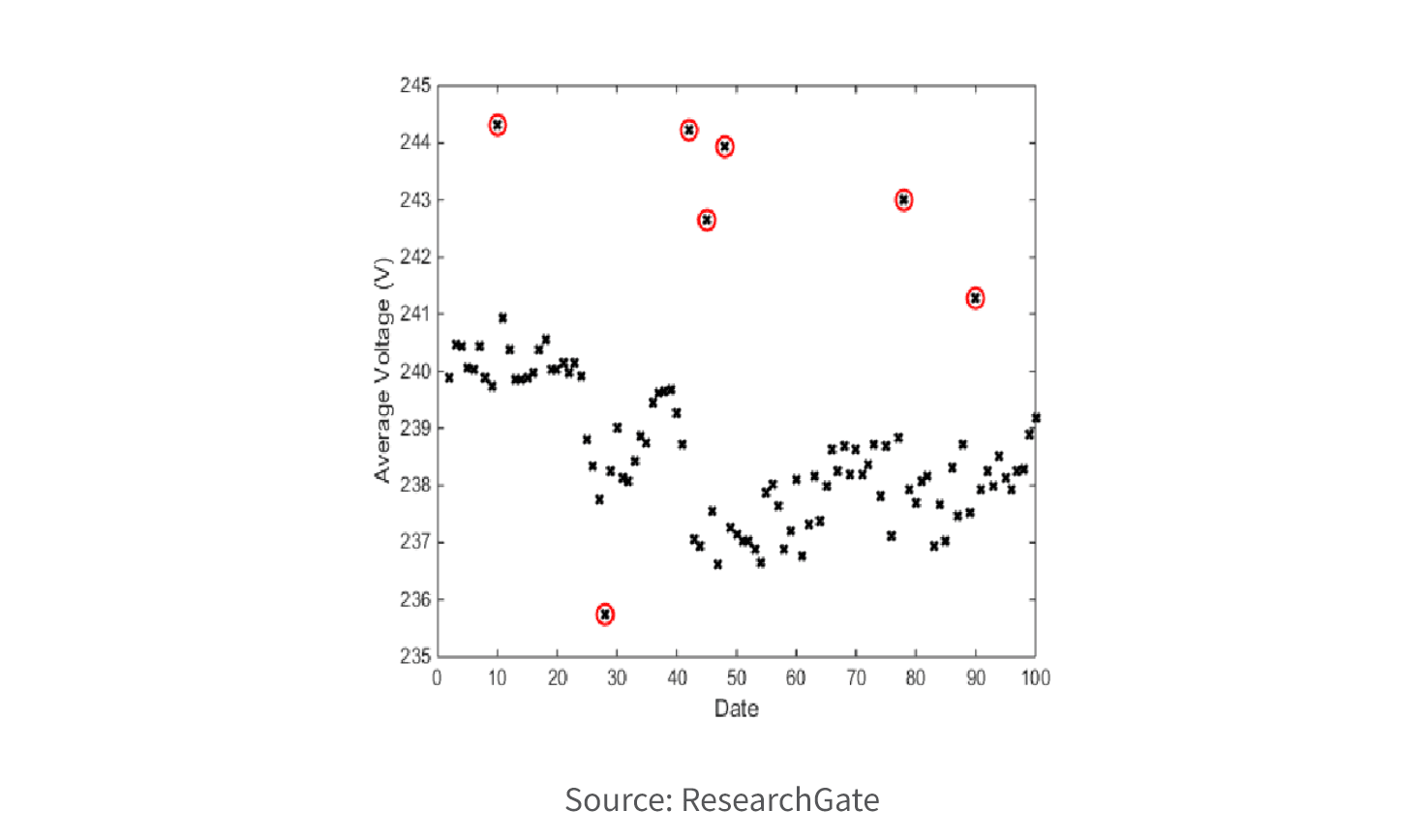
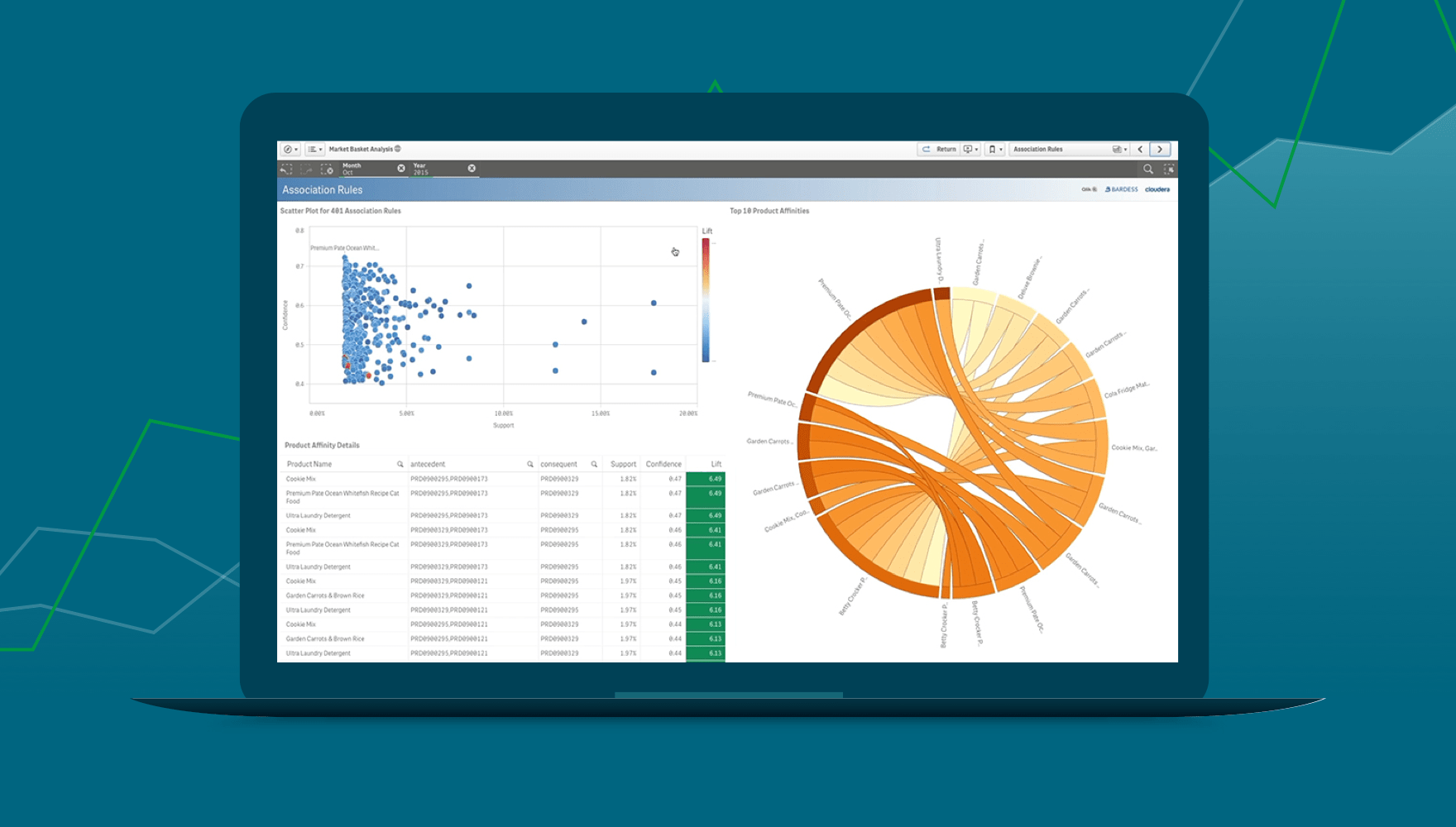
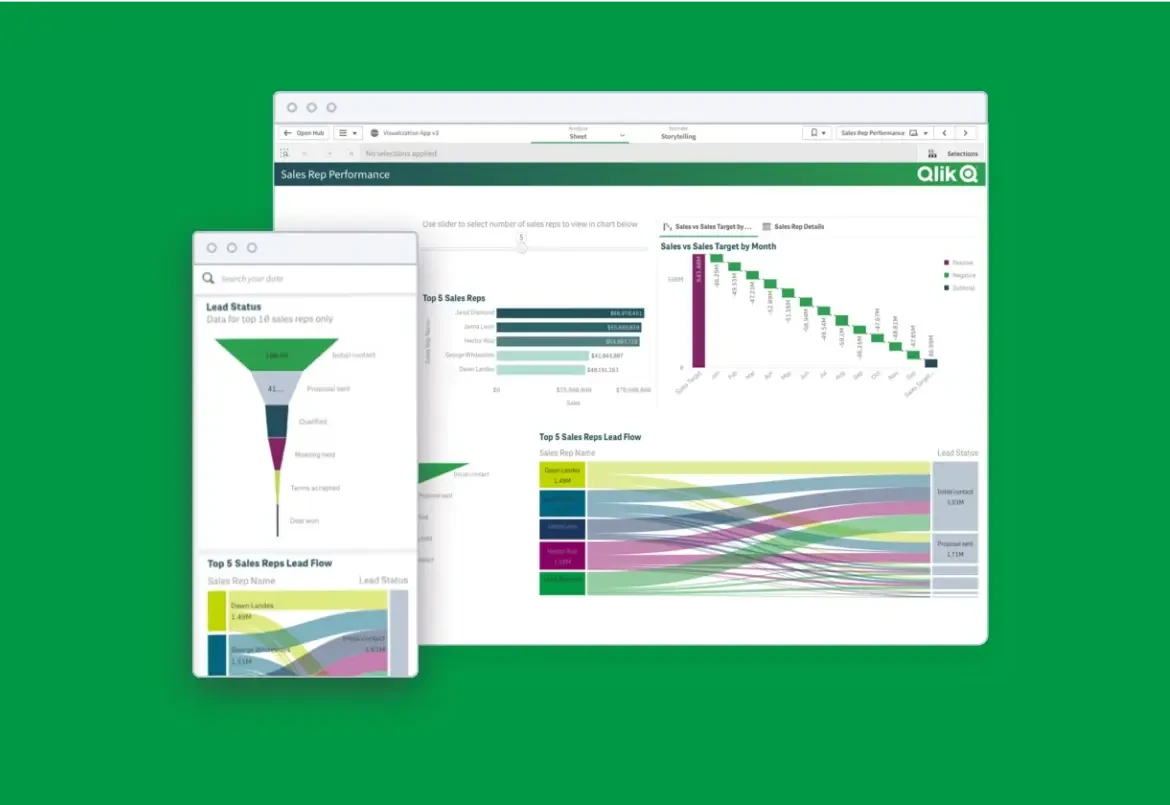
4. Explore Data. Explore and understand your data through descriptive statistics, visualization techniques, and exploratory data analysis. This step helps in identifying patterns, trends, and outliers in the dataset and gaining insights into the underlying data characteristics.
5. Select predictors. This step, also called feature selection/engineering, involves identifying the relevant features (variables) in the dataset that are most informative for the task. This may involve eliminating irrelevant or redundant features and creating new features that better represent the problem domain.
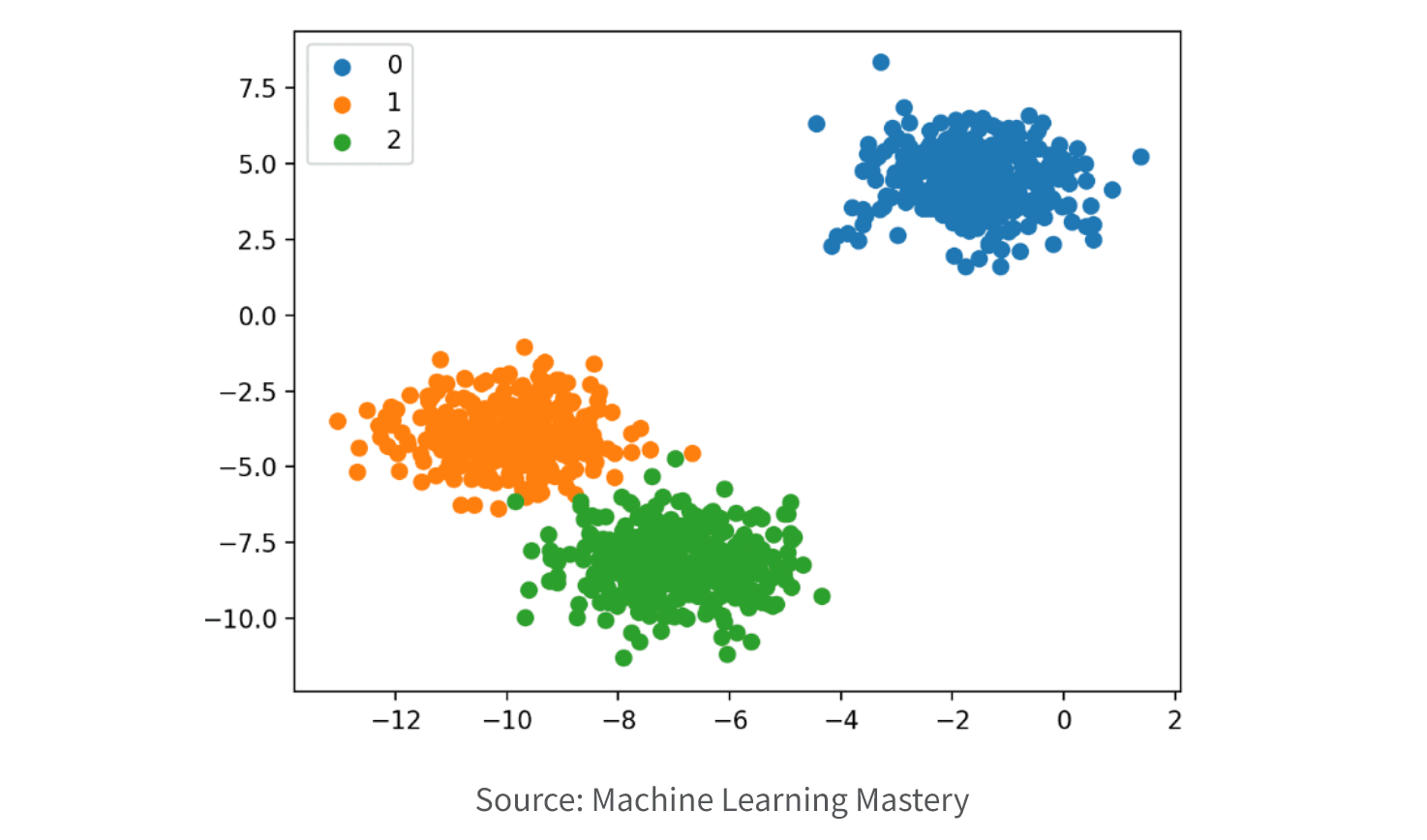
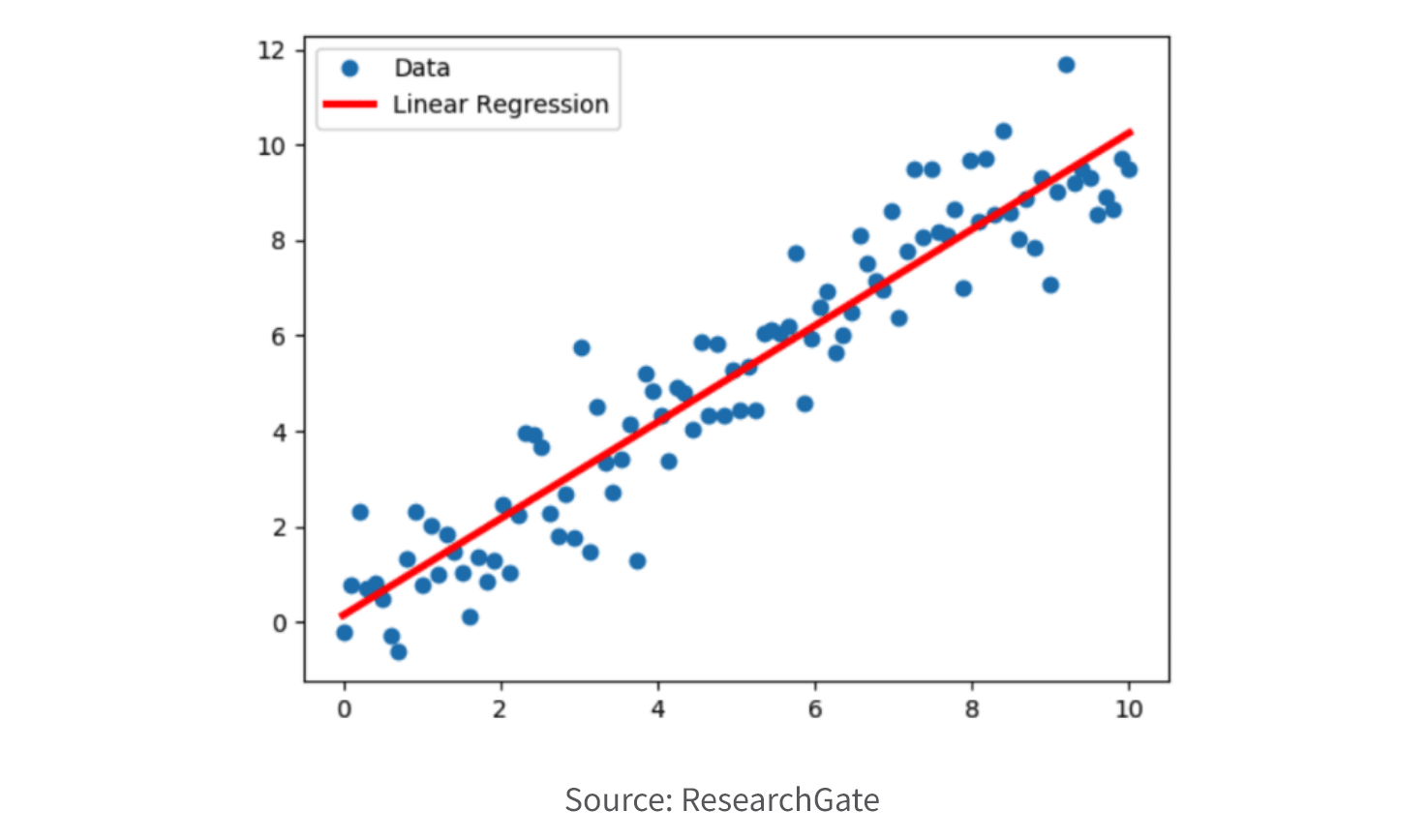
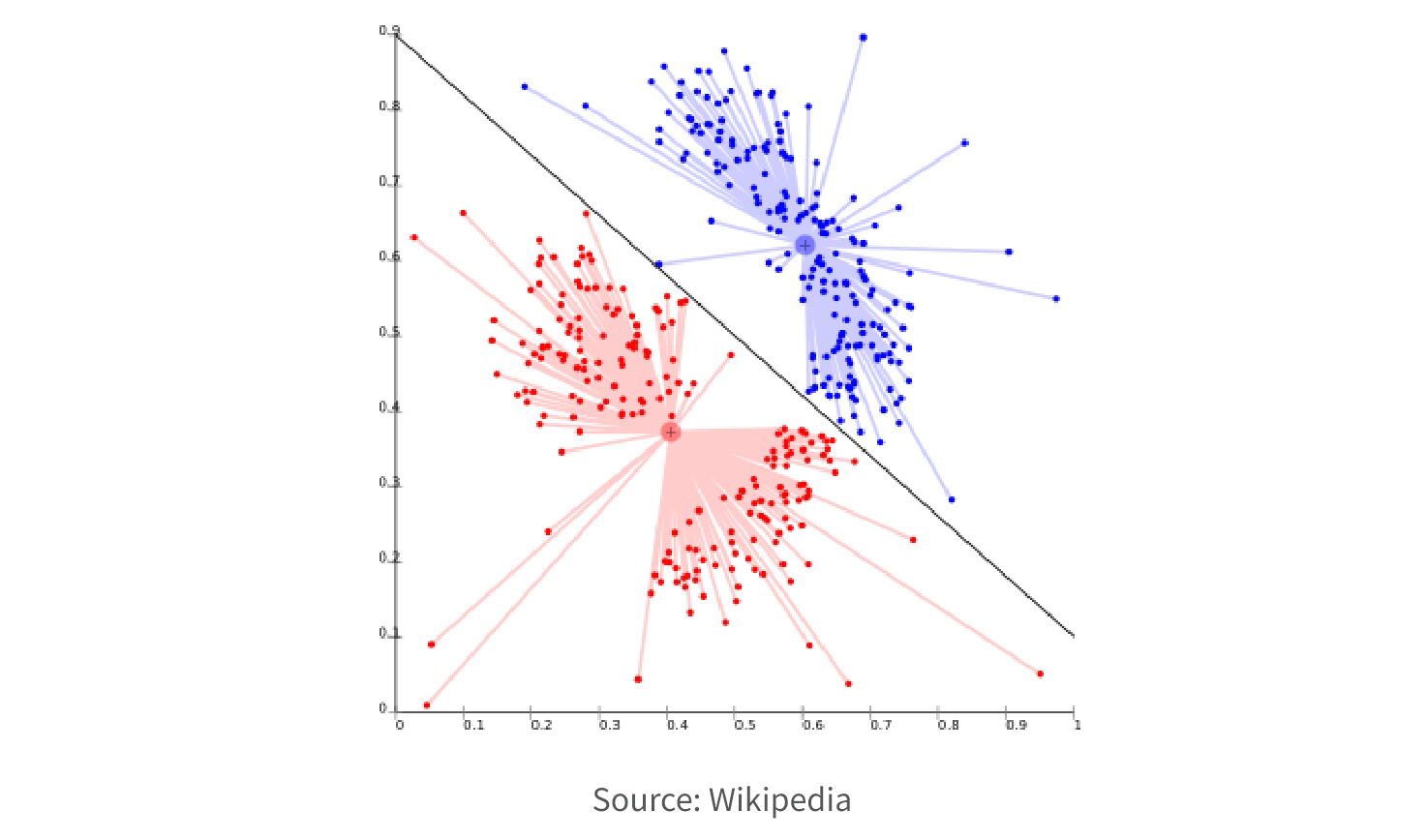
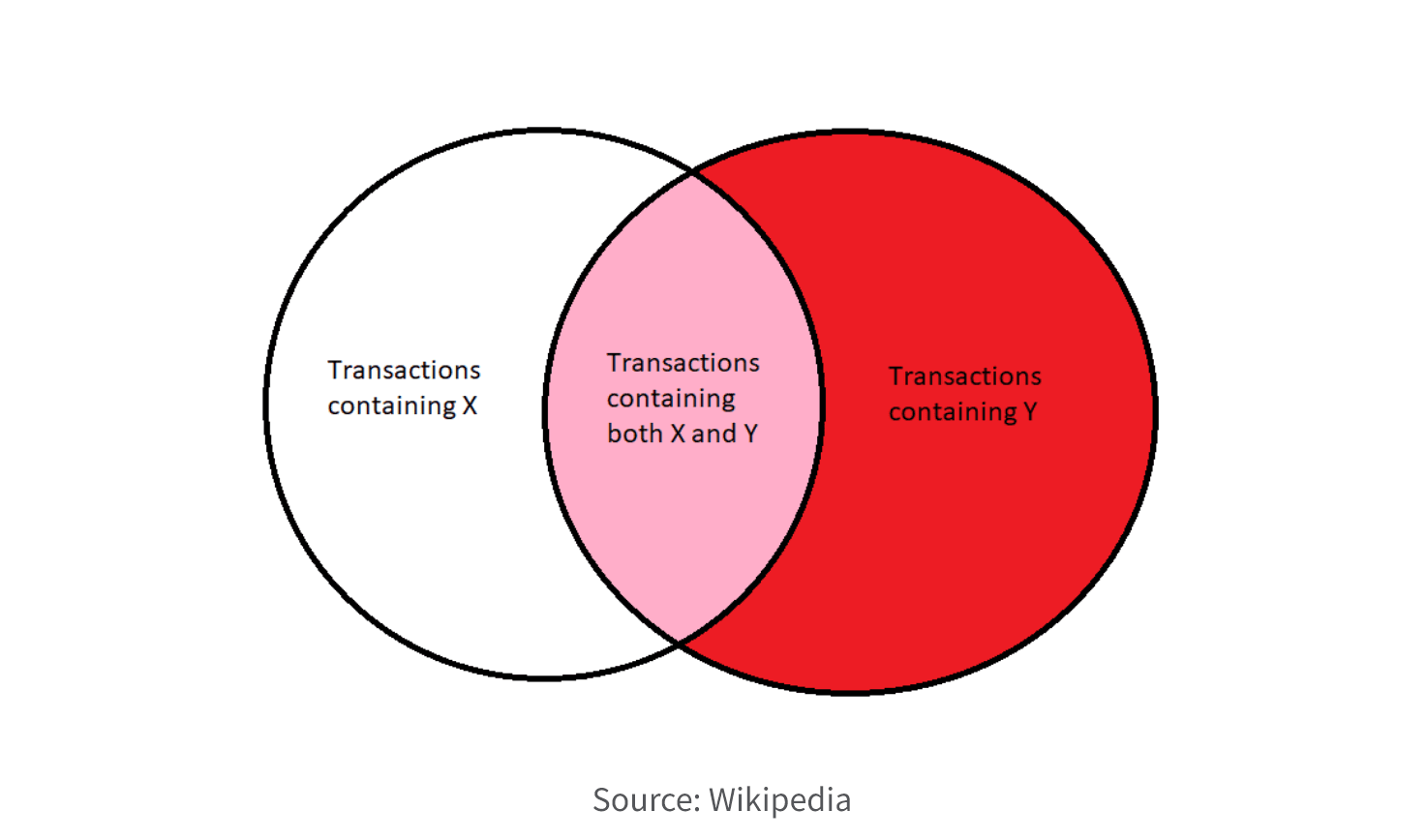
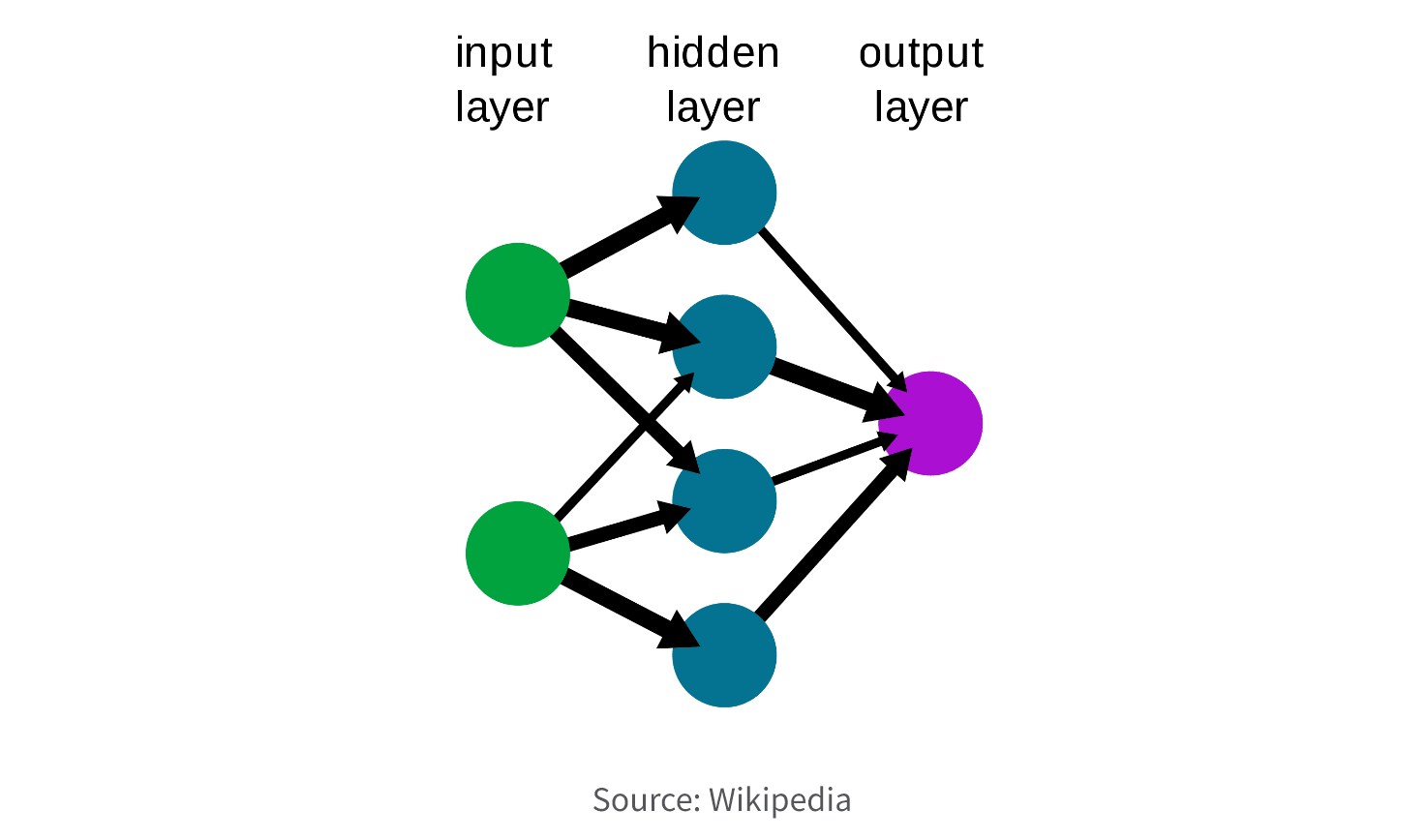
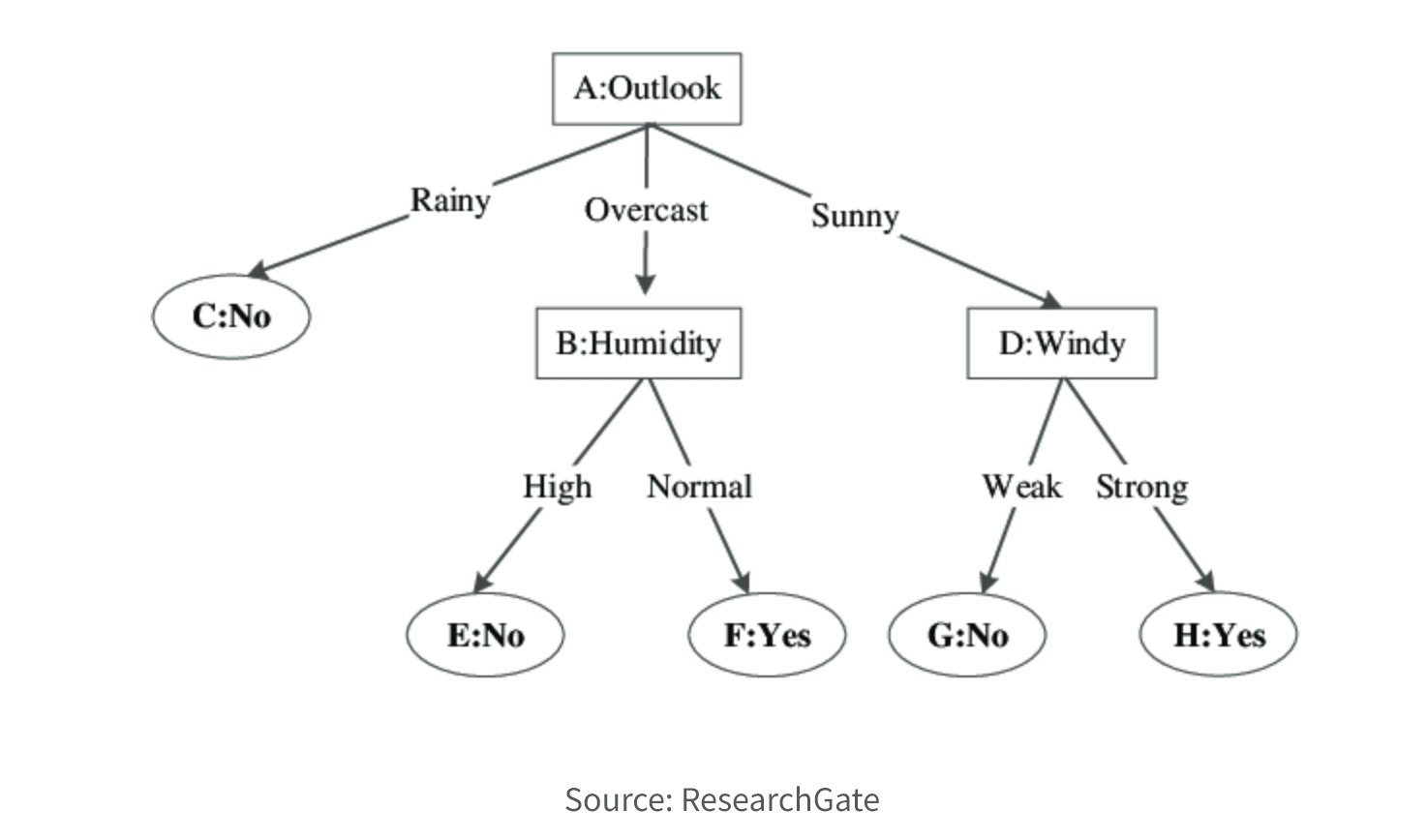
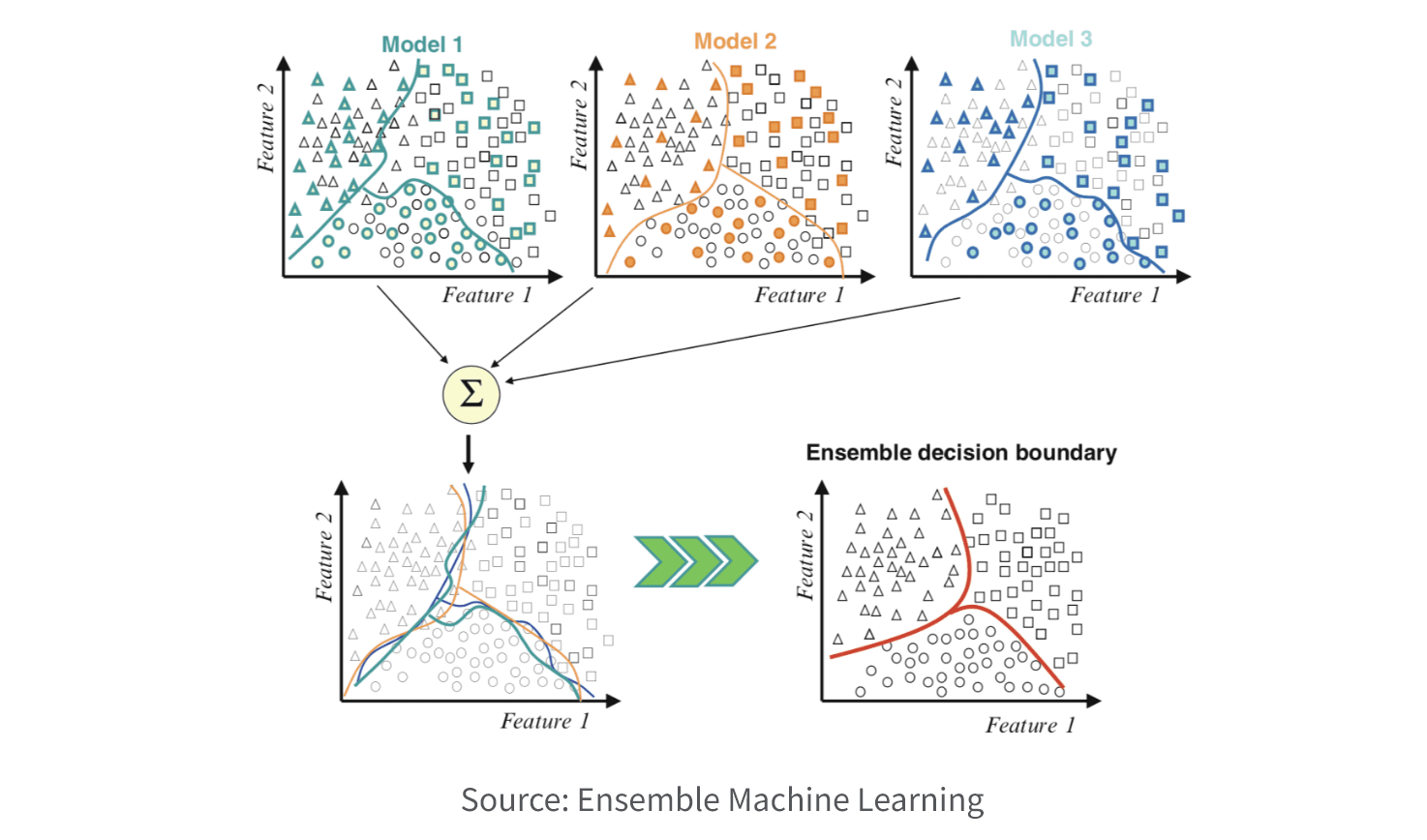
6. Select Model. Choose an appropriate model or algorithm based on the nature of the problem, the available data, and the desired outcome. Common techniques include decision trees, regression, clustering, classification, association rule mining, and neural networks. If you need to understand the relationship between the input features and the output prediction (explainable AI), you may want a simpler model like linear regression. If you need a highly accurate prediction and explainability is less important, a more complex model such as a deep neural network may be better.
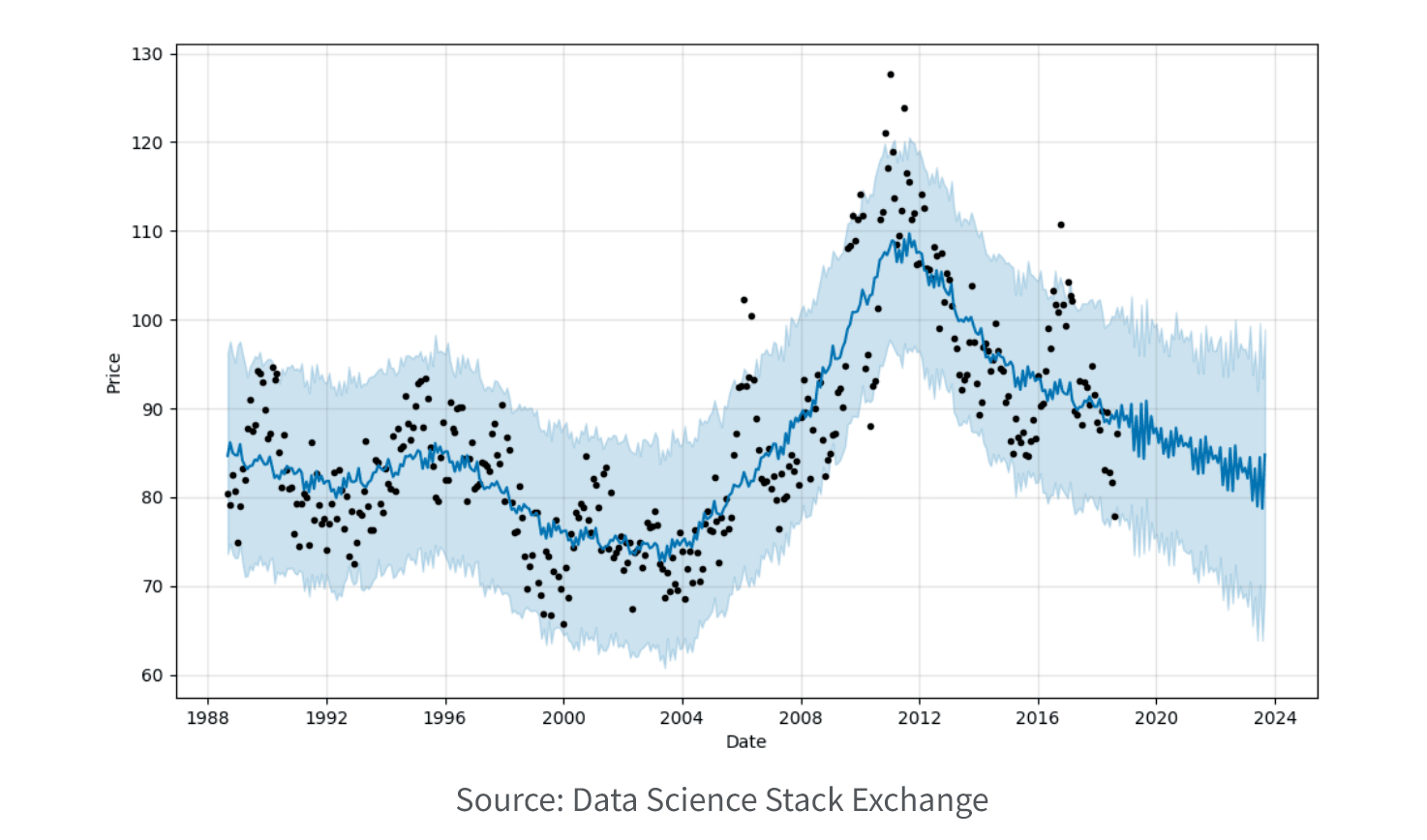
7. Train Model. Train your selected model using the prepared dataset. This involves feeding the model with the input data and adjusting its parameters or weights to learn from the patterns and relationships present in the data.
8. Evaluate Model. Assess the performance and effectiveness of your trained model using a validation set or cross-validation. This step helps in determining the model's accuracy, predictive power, or clustering quality and whether it meets the desired objectives. You may need to adjust the hyperparameters to prevent overfitting and improve the performance of your model.
9. Deploy Model. Deploy your trained model into a real-world environment where it can be used to make predictions, classify new data instances, or generate insights. This may involve integrating the model into existing systems or creating a user-friendly interface for interacting with the model.
10. Monitor & Maintain Model. Continuously monitor your model's performance and ensure its accuracy and relevance over time. Update the model as new data becomes available, and refine the data mining process based on feedback and changing requirements.
Flexibility and iterative approaches are often required to refine and improve the results throughout the process.