










































Types of Data Management
There are many disciplines you should consider when developing your comprehensive data management strategy. The diagram below shows a typical customer data management system, including the five main approaches to data integration. Modern data integration architectures such as data fabric and data mesh are described later in this guide.

Let’s dig a bit deeper into the types of enterprise data management:
Architecture & Strategy
Data architecture: the formal design and structure and flow of data systems, including databases, data warehouses, and other data storage systems.
Data modeling: the process of creating a diagram that represents your data system and defines the structure, attributes, and relationships of your data entities.
DataOps (data operations): a methodology that streamlines data-related processes by combining aspects of DevOps and Agile principles.
Data Processing
Data wrangling: the process of cleaning, structuring, and transforming raw data into a usable format for analysis. Wrangling extends beyond identifying and rectifying data errors, inconsistencies, and inaccuracies to tasks such as reshaping, merging, and enriching data to make it suitable for analysis.
Data integration: the process of bringing together data from multiple sources across an organization to provide a complete, accurate, and up-to-date dataset for analysis and other applications and business processes. It includes data replication, ingestion and transformation to combine different types of data into standardized formats to be stored in a target repository.
Data Storage
Data warehouse: a system which aggregates large volumes of data from multiple sources into a single repository of highly structured and unified historical data.
Data lake: a centralized repository that holds all of your organization's structured and unstructured data. It employs a flat architecture which allows you to store raw data at any scale without the need to structure it first.
Data Governance
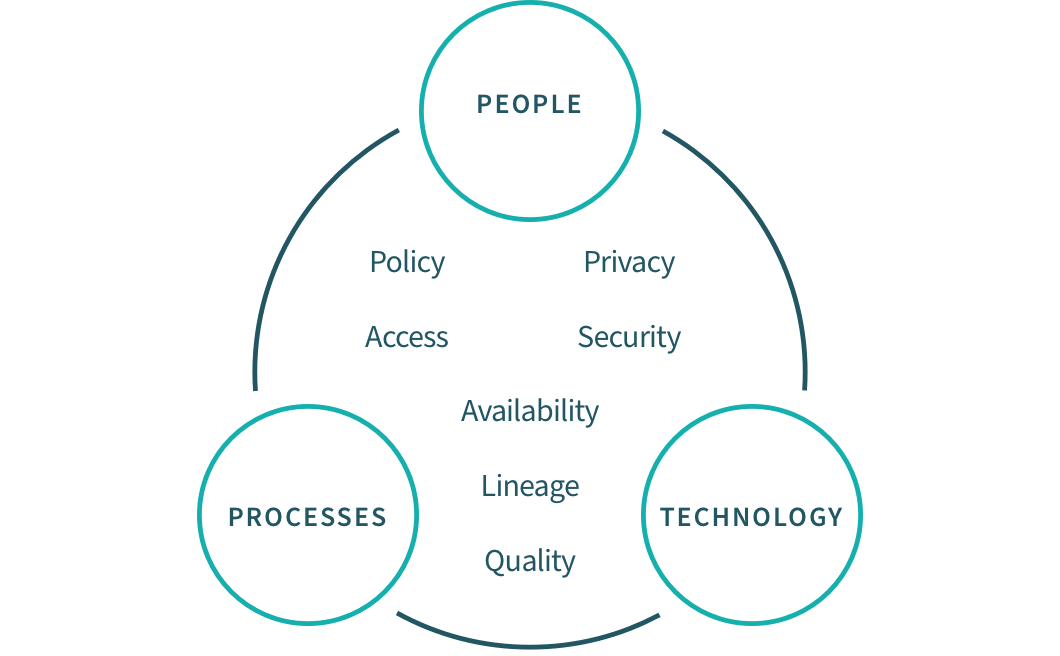
Data governance framework: the set of roles, processes, policies, and tools which ensure proper data integrity, quality, privacy, and security throughout the data lifecycle and proper data usage across an organization. Data governance allows users to more easily find, prepare, use and share trusted datasets on their own, without relying on IT.
Data integrity refers to the accuracy, consistency, and completeness of data throughout its lifecycle. It’s a critically important aspect of systems which process or store data because it protects against data loss and data leaks.
Data quality refers to the accuracy, completeness, and consistency of data, and involves ongoing monitoring and management to ensure that data meets established standards.
Data privacy involves protecting personal or sensitive data from unauthorized use or disclosure, and includes compliance with relevant regulations and standards.
Data security involves protecting data from unauthorized access, use, or disclosure, and includes measures such as encryption, access controls, and monitoring.
Data catalog: an inventory of data assets, organized by metadata and search tools, which provides on-demand access to business-ready data.
Master data management involves creating a single, authoritative source for key data elements, such as customer or product information, which can be used across multiple systems and applications.
Metadata management involves managing information about the data, including data definitions, relationships, and lineage, to ensure that data is properly understood and used.

