What are the key benefits and differences? This guide provides definitions and practical advice to help you understand the differences as you evaluate data lake vs data warehouse for your organization.
A data lake is a massive repository of structured and unstructured data, and the purpose for this data has not been defined. A data warehouse is a repository of highly structured historical data which has been processed for a defined purpose.
What is a Data Lake?
A data lake is a repository that stores all of your organization's data — both structured and unstructured. Think of it as a massive storage pool for data in its natural, raw state (like a lake). A data lake architecture can handle the huge volumes of data that most organizations produce without the need to structure it first. Data stored in a data lake can be used to build data pipelines to make it available for data analytics tools to find insights that inform key business decisions.
Data Lake Benefits
Because the large volumes of data in a data lake are not structured before being stored, skilled data scientists or end-to-end self-service-BI tools can gain access to a broader range of data far faster than in a data warehouse.
Massive volumes of structured and unstructured data like ERP transactions and call logs can be stored cost effectively.
Data is available for use far faster by keeping it in a raw state.
A broader range of data can be analyzed in new ways to gain unexpected and previously unavailable insights.
Your data engineers can build ETL data pipelines and schema-on-read transformations to make data stored in a data lake available for analytics, data science, and machine learning. Managed data lake creation tools help you overcome the limitations of slow, hand-coded scripts and scarce engineering resources.
Today, many companies are adopting Delta Lake, an open-source storage layer that leverages ACID compliance from transactional databases to enhance reliability, performance, and flexibility in data lakes. It’s particularly useful for scenarios requiring transactional capabilities and schema enforcement within your data lake. It enables the creation of data lakehouses, which support both data warehousing and machine learning directly on the data lake. It offers features such as scalable metadata handling, data versioning, and schema enforcement for large-scale datasets, ensuring data quality and reliability for analytics and data science tasks.
Similar to a data lake, a data warehouse is a repository for business data. However, unlike a data lake, only highly structured and unified data lives in a data warehouse to support specific business intelligence and analytics needs. Think of it like an actual warehouse, where contents are first processed, then organized into sections and onto shelves (called data marts). Data from a warehouse is ready for use to support historical analysis and reporting to inform decision making across an organization’s lines of business.
A cloud data warehouse is a database stored as a managed service in a public cloud and optimized for scalable BI and analytics. It removes the constraint of physical data centers and lets you rapidly grow or shrink your data warehouses to meet changing business budgets and needs.
Data Warehouse Benefits
A data warehouse offers enormous benefits to organizations, especially as it relates to BI and analytics. After the initial work of cleansing and processing, data stored in a warehouse serves as a consistent "single source of truth" which is invaluable to business data analysis, collaboration, and better insights. Three major advantages of a data warehouse include:
Little or no data prep needed, making it far easier for analysts and business users to access and analyze this data.
Accurate, complete data is available more quickly, so businesses can turn information into insight faster.
Unified, harmonized data offers a single source of truth, building trust in data insights and decision-making across business lines.
The large majority of organizations primarily use data warehouses and the clear trend is toward cloud data warehouses. Data lakes are typically used by data scientists for machine learning and exploration of flat files.
Still, many organizations use both a data lake and a data warehouse to cover the spectrum of their data storage needs. Some choose to combine key capabilities of each by implementing a data lakehouse. Let’s take a side-by-side look at data lake vs data warehouse, and how they can work in tandem to provide a holistic data storage solution for your business.
Data Lake vs Data Warehouse — 6 Key Differences:
Data Lake
Data Warehouse
1. Data Storage
A data lake contains all an organization's data in a raw, unstructured form, and can store the data indefinitely — for immediate or future use.
A data warehouse contains structured data that has been cleaned and processed, ready for strategic analysis based on predefined business needs.
2. Users
Data from a data lake — with its large volume of unstructured data — is typically used by data scientists and engineers who prefer to study data in its raw form to gain new, unique business insights.
Data from a data warehouse is typically accessed by managers and business-end users looking to gain insights from business KPIs, as the data has already been structured to provide answers to pre-determined questions for analysis.
3. Analysis
Predictive analytics, machine learning, data visualization, BI, big data analytics.
Data visualization, BI, data analytics.
4. Schema
Schema is defined after the data is stored in a data lake vs data warehouse, making the process of capturing and storing the data faster.
In a data warehouse, the schema is defined before the data is stored. This lengthens the time it takes to process the data, but once complete, the data is at the ready for consistent, confident use across the organization.
5. Processing
ELT (Extract, Load, Transform). In this process, the data is extracted from its source for storage in the data lake, and structured only when needed.
ETL (Extract, Transform, Load). In this process, data is extracted from its source(s), scrubbed, then structured so it's ready for business-end analysis.
6. Cost
Storage costs are fairly inexpensive in a data lake vs data warehouse. Data lakes are also less time-consuming to manage, which reduces operational costs.
Data warehouses cost more than data lakes, and also require more time to manage, resulting in additional operational costs.
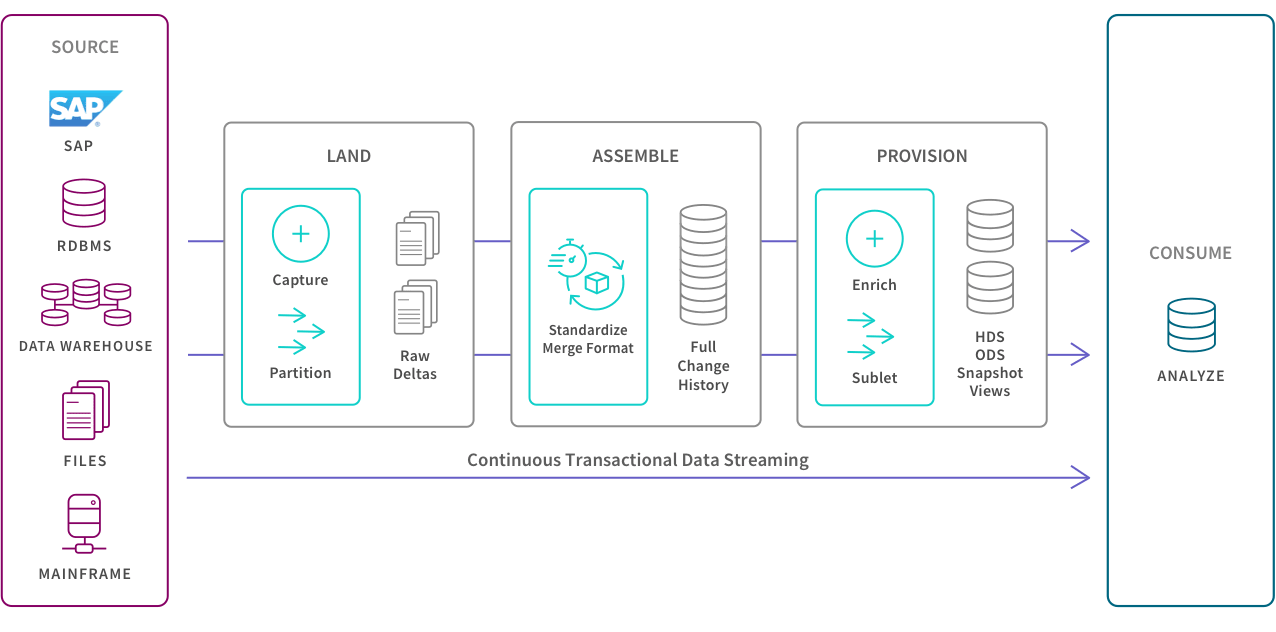
Data Lake ROI: 5 Principles for Managing Data Lake Pipeline
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.