Data Lake Definition
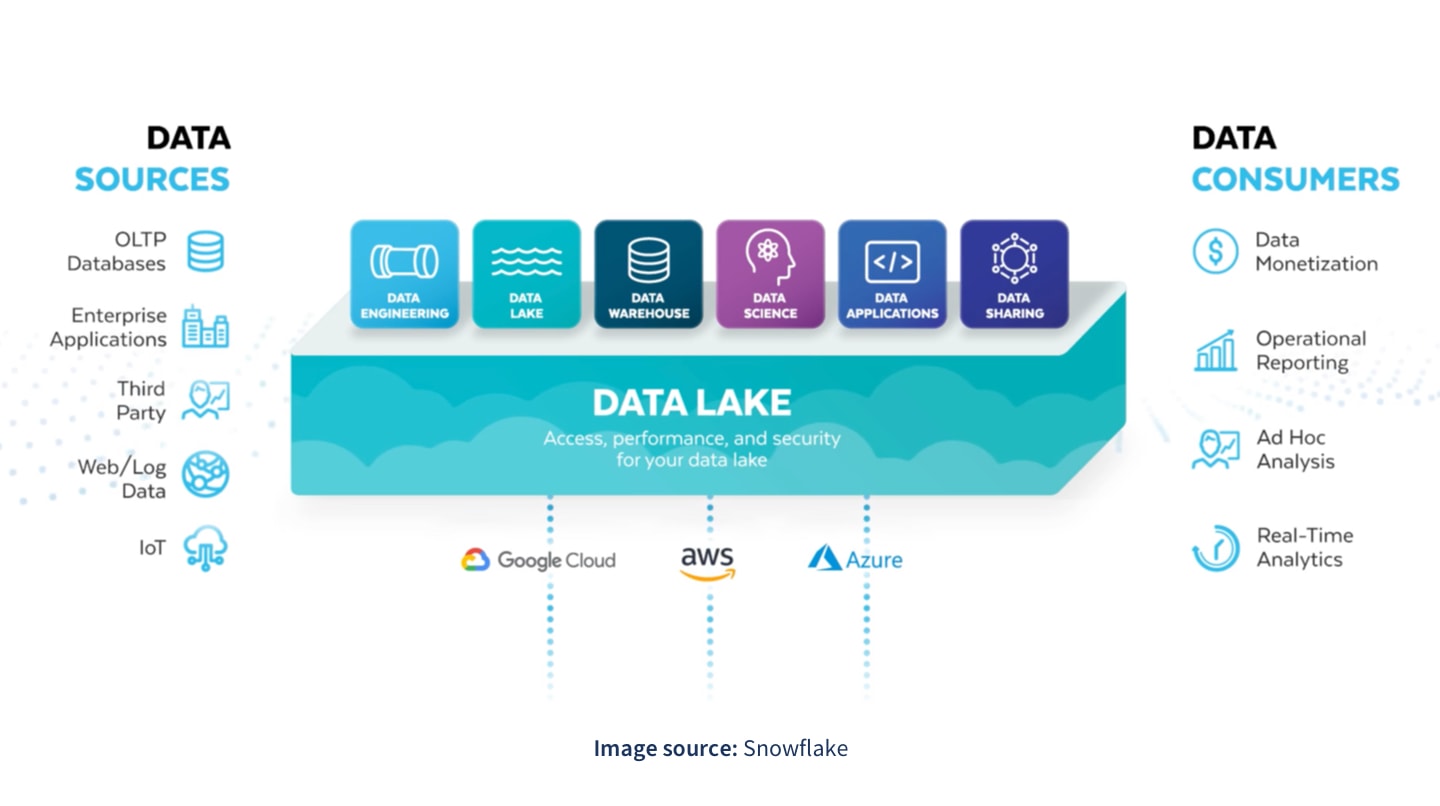
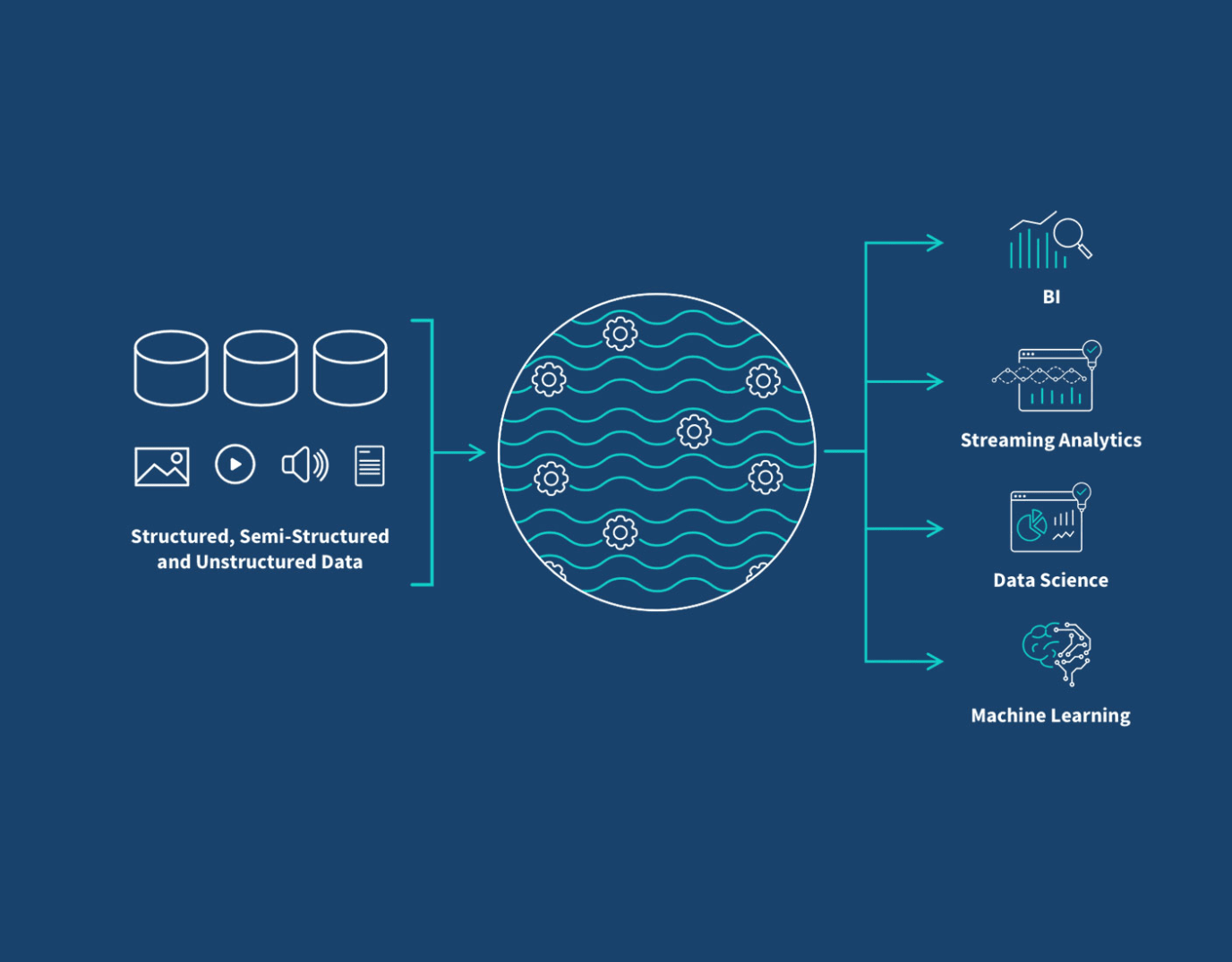
A data lake is a data storage strategy that consolidates your structured and unstructured data from a variety of sources. This provides a single source of truth for different use cases such as real-time analytics, machine learning, big data analytics, dashboards, and data visualizations to help you uncover insights and make accurate, data-driven business decisions.
Here six main advantages of a� data lake vs data warehouse:
Scale. A data lake's lack of structure lets it handle massive volumes of structured and unstructured data.
Speed. Your data is available for use much faster since you don’t have to transform it or develop schemas in advance.
Agility. Your data lake supports both analytics and machine learning and you can easily configure data models, queries, or applications without pre-planning.
Real-time. You can perform real-time analytics and machine learning and trigger actions in other applications.
Better insights. You’ll gain previously unavailable insights by analyzing a broader range of data in new ways.
Lower cost. Data lakes are less time-consuming to manage and most of the tools you use to manage them are open source and run on low-cost hardware or cloud services.
Ultimately, a data lake can transform your organization’s use of data and democratize access to data, improving data literacy for all. Learn more about data lakes.