What it is, why it matters, and best practices. This guide provides examples and practical advice to help you decide whether migrating to a cloud-based data warehouse is right for your organization.
A cloud data warehouse is a database stored as a managed service in a public cloud and optimized for scalable BI and analytics.
Why It Matters
Data warehouses have been staples of enterprise analytics and reporting for decades. But they weren’t designed to handle today’s explosive data growth or keep pace with end users’ ever-changing needs.
With cloud data warehousing, you’re no longer constrained by physical data centers and you can now dynamically grow or shrink your data warehouses to rapidly meet changing business budgets and requirements. Like a traditional data warehouse, a cloud data warehouse stores information from a variety of disparate data sources such as IoT, CRM, finance systems, and many others.
Because the data in a cloud-based data warehouse is highly structured and unified, it's at-the-ready to support a wide variety of specific business intelligence and analytics use cases.
Key features
Massively parallel processing (MPP): Cloud-based data warehouses that support big data projects use MPP architectures to provide high-performance queries on large data volumes. MPP architectures consist of many servers running in parallel to distribute processing and input/output (I/O) loads.
Columnar data stores: MPP data warehouses are typically columnar stores — the most flexible and economical for analytics. Columnar databases store and process data by columns instead of rows and make aggregate queries, the type often used for reporting, run dramatically faster.
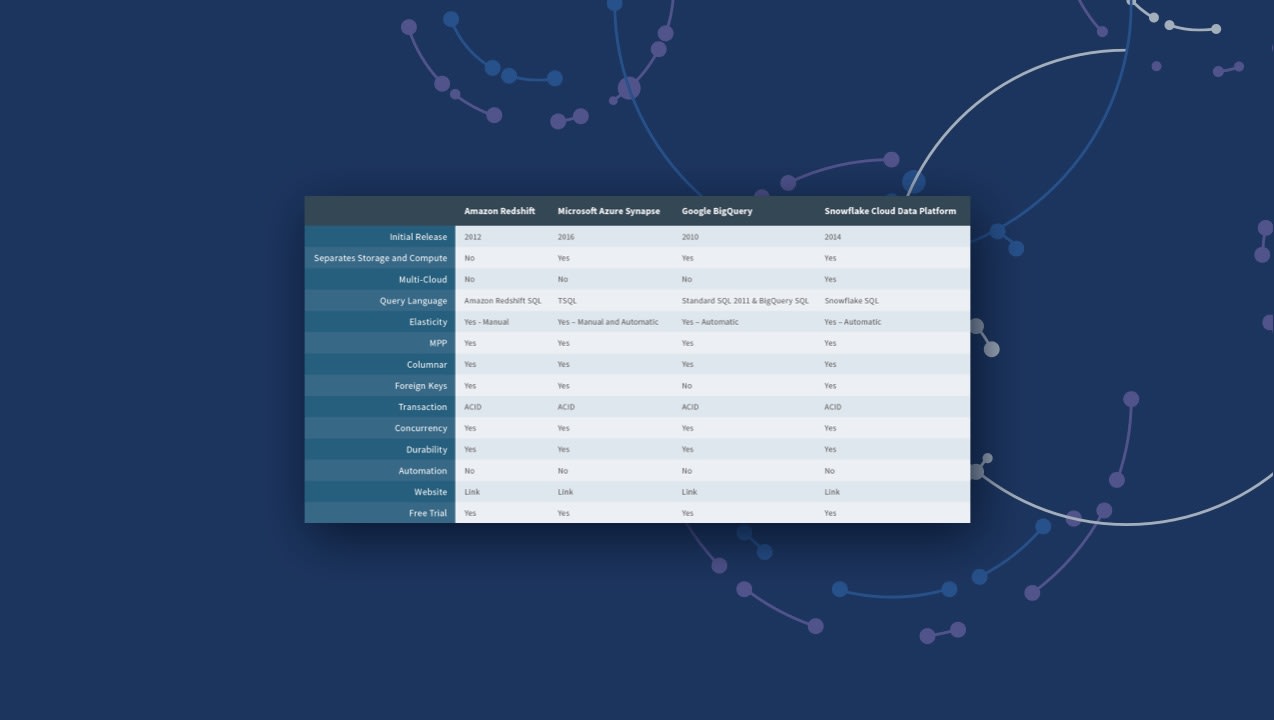
Comparison Guide: Top Cloud Data Warehouses
Modern cloud architectures combine three essentials: the power of data warehousing, flexibility of Big Data platforms, and elasticity of cloud at a fraction of the cost to traditional solution users. But which solution is the right one for you and your business? Download the eBook to see a side-by-side comparison of these leading vendors: Amazon vs. Azure vs. Google vs. Snowflake.
The cloud data warehouse has become a crucial element of the modern data stack. Cloud architectures combine the power of data warehousing, the flexibility of big data platforms, and the elasticity of the cloud at a fraction of the cost of traditional solutions. Here we discuss the advantages in performance, scalability and cost when implementing a cloud-based data warehouse over a traditional data warehouse.
Modern cloud architectures combine the power of data warehousing, the flexibility of big data platforms and the elasticity of the cloud at a fraction of the cost of traditional solutions. Here we discuss the advantages in performance, scalability and cost when implementing a cloud-based data warehouse over a traditional data warehouse.
Faster Insights: A cloud data warehouse provides more powerful computing capabilities, and will deliver real-time cloud analytics using data from diverse data sources much faster than an on-premises data warehouse, allowing business users to access better insights, faster.
Scalability: A cloud-based data warehouse offers immediate and nearly unlimited storage, and it’s easy to scale as your storage needs grow. Increasing cloud storage doesn’t require you to purchase new hardware as an on-premises data warehouse does, and you’ll pay a fraction of the cost.
Overhead: Maintaining a data warehouse on-premises requires a dedicated server room full of expensive hardware, and experienced employees to oversee, manually upgrade, and troubleshoot issues. A cloud data warehouse requires no physical hardware or allocated office space, making operational costs significantly lower.
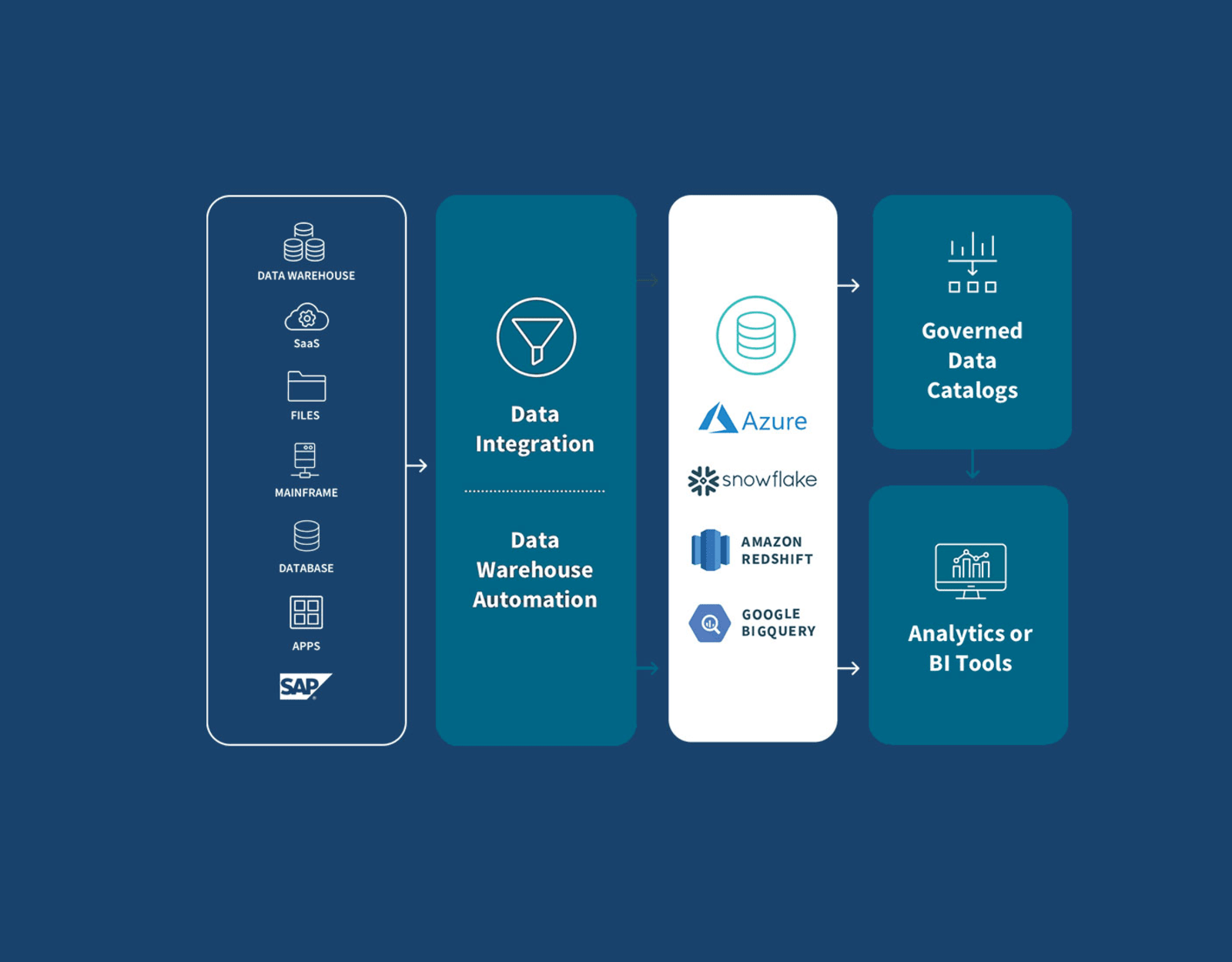
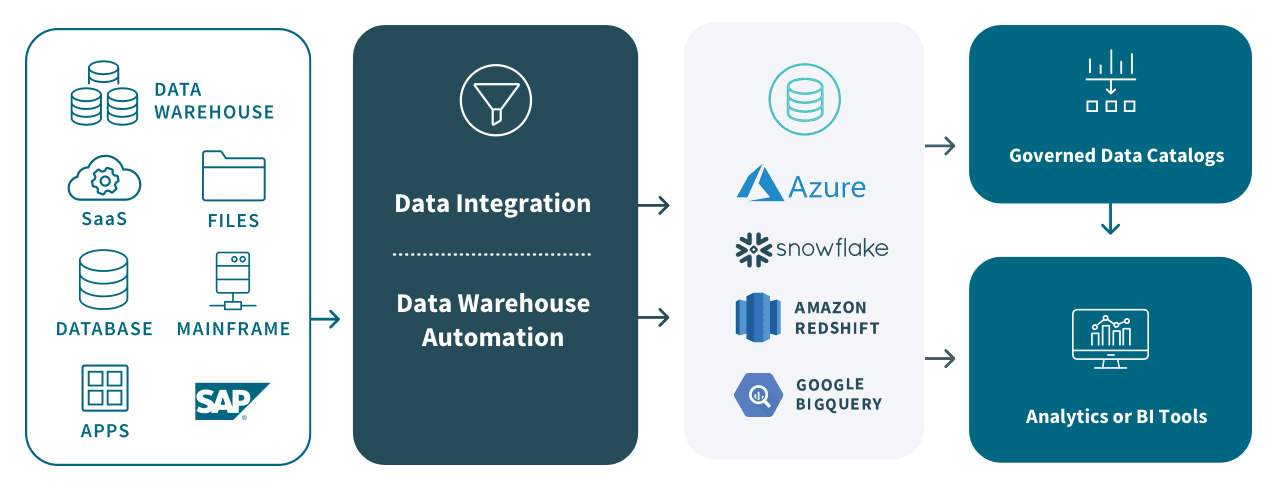
Cloud Data Warehouse Automation
Some modern data integration platforms automate the entire data warehouse lifecycle to accelerate the availability of your analytics-ready data. And a model-driven approach will help your data engineers to design, deploy, manage, and catalog purpose-built, cloud data warehouses faster than traditional solutions.
This 2-minute video describes the key data warehouse automation concepts and benefits.
The flow chart below highlights 3 key productivity drivers of an agile data warehouse:
Real-time data ingestion and updates. A simple and universal solution for continually ingesting your enterprise data into popular cloud-based data warehouses in real time.
Automated workflow. A model-driven approach for continually refining your data warehouse operations.
Trusted, enterprise-ready data. A smart, enterprise-scale data catalog to securely share your data marts.
There are many popular cloud-based data warehouse platforms to choose from, including Amazon Redshift, Google BigQuery, Microsoft Azure, Snowflake, and others — and there are just as many important considerations when deciding on the right solution for your organization.
While many of the popular cloud data platforms offer similar capabilities, you’ll find many differences in pricing, scalability, architecture, security features, speed, and other factors.
Here we compare the four top vendors for the enterprise: Amazon vs. Azure vs. Google vs. Snowflake
Amazon Redshift: The first widely adopted cloud data warehouse
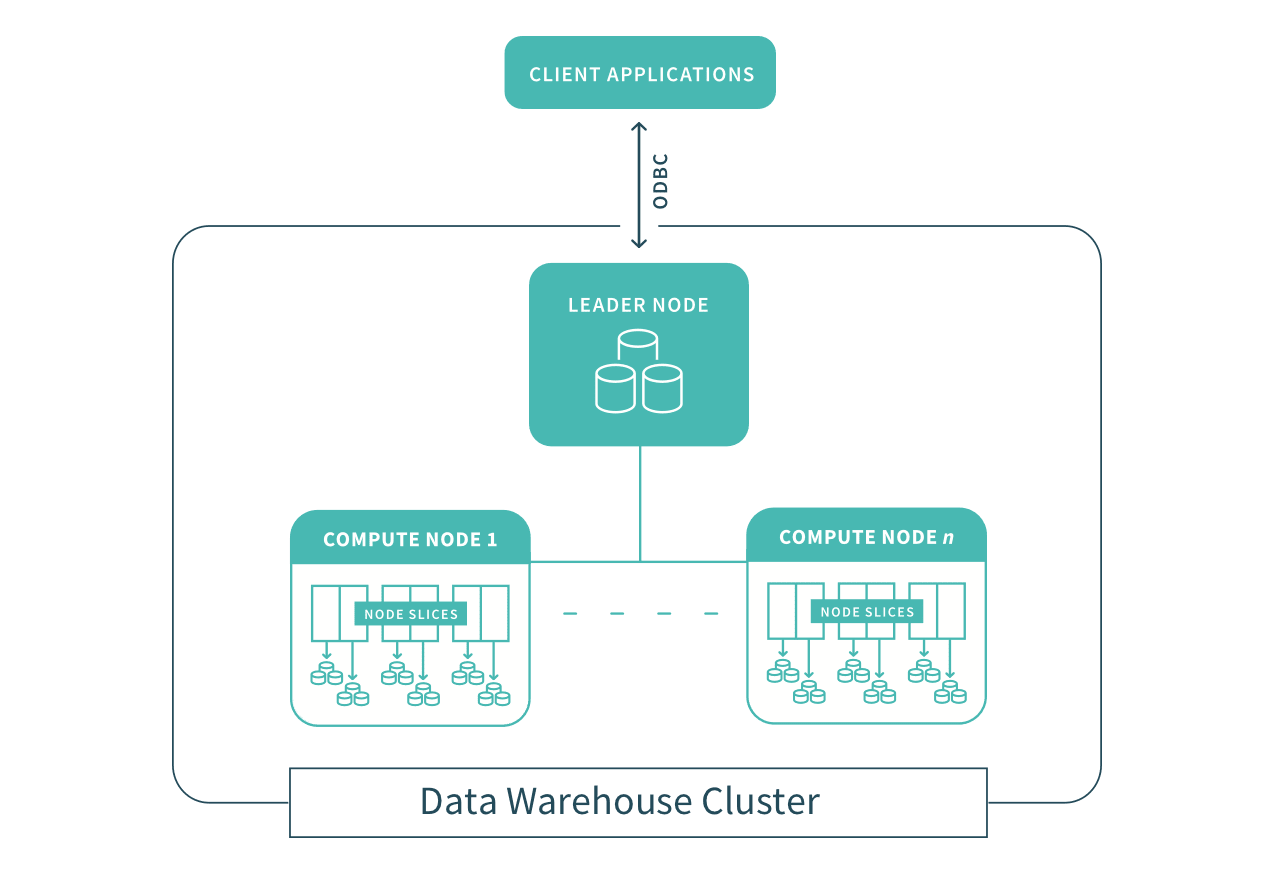
For many years, data warehousing was only available as an on-premise solution. Then in November 2012, Amazon Web Services (AWS) launched Redshift, a fully managed, petabyte-scale data warehouse service in the cloud. Although not the first cloud-based data warehouse, it was the first to gain market share through adoption. Redshift’s SQL dialect is based on PostgreSQL, which is well understood by analysts worldwide, and uses an architecture familiar to many on-premises data warehouses users.
You can start with as little as a few gigabytes of data and scale to petabytes. This empowers you to acquire new insights from your business and customer data.
The first step to creating a Redshift data warehouse is to launch a set of nodes, called an Amazon Redshift cluster. After you provision your cluster, you upload your data set and then perform data analysis queries. Regardless of the size of your data set, Amazon Redshift delivers fast query performance using familiar SQL-based tools and business intelligence applications.
Microsoft Azure Synapse Analytics: Taking SQL beyond data warehousing
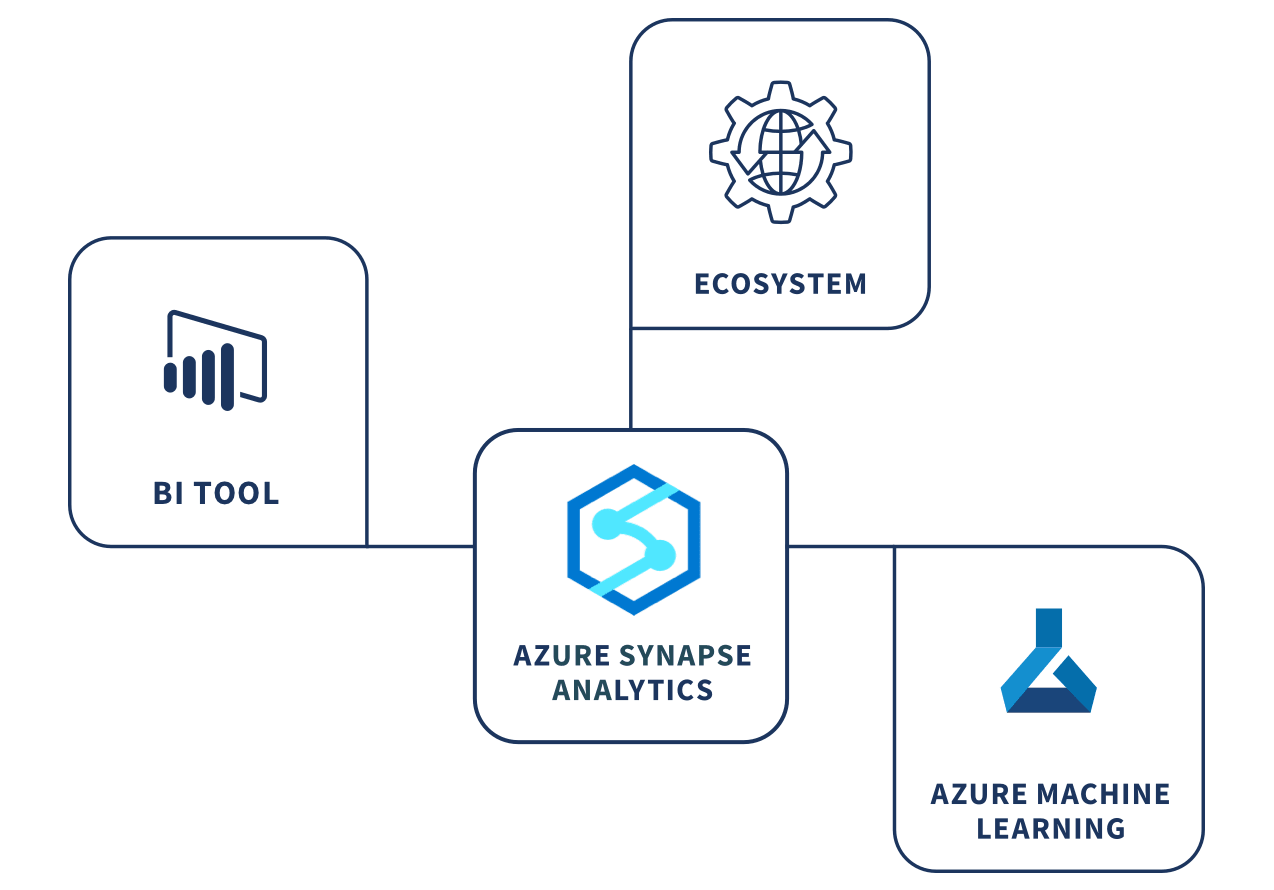
Azure Synapse Analytics is a newer analytics service that brings together enterprise data warehousing and big data analytics. It gives you the freedom to query data using either serverless on-demand or provisioned resources. Azure Synapse offers a unified experience to ingest, prepare, manage, and serve data for your business intelligence (BI) and machine learning (ML) needs.
At the heart of Azure Synapse is a cloud-native, distributed SQL processing engine. It’s built on the foundation of SQL Server to drive your most demanding enterprise data warehousing workloads. Similar to other cloud MPP solutions, Azure SQL Data Warehouse (SQL DW) separates storage and compute, billing for each separately. Azure Synapse saves relational tables data with columnar storage and abstracts physical machines by representing compute power in the form of data warehouse units (DWUs). This allows your users to easily and seamlessly scale compute resources at will.
Synapse Analytics aims to unify a range of analytics workloads, such as data warehouses or data lakes, and ML, in a singular user interface (UI). The combination of an SQL Engine, Apache Spark with Azure Data Lake Storage (ADLS), and Azure Data Factory gives users the option to control both data warehouse/data lakes and data preparation for ML tasks. Azure Synapse allows for both vertical and horizontal scaling of the data warehouse. Vertically by changing the service tier or placing the database in an elastic pool. Horizontally by adding more data warehouse units.
Google BigQuery: A serverless solution
BigQuery is a fully managed, serverless data warehouse that automatically scales to match storage and computing power needs. Google doesn’t expect you to manage your data warehouse infrastructure which is why BigQuery hides many of the underlying hardware, database, nodes, and configuration details. Its elasticity automatically works out of the box. And getting started is simply a matter of creating an account with Google Cloud Platform (GCP), loading a table, and running a query. Google takes care of the rest.
With BigQuery, you get a columnar and ANSI SQL database that can analyze terabytes to petabytes of data at incredible speeds. BigQuery also lets you do spatial analysis using familiar SQL with BigQuery GIS. In addition, you can quickly build and operationalize ML models on large-scale structured or semi-structured data using simple SQL with BigQuery ML. And you can support real-time interactive dashboarding with BigQuery BI Engine.
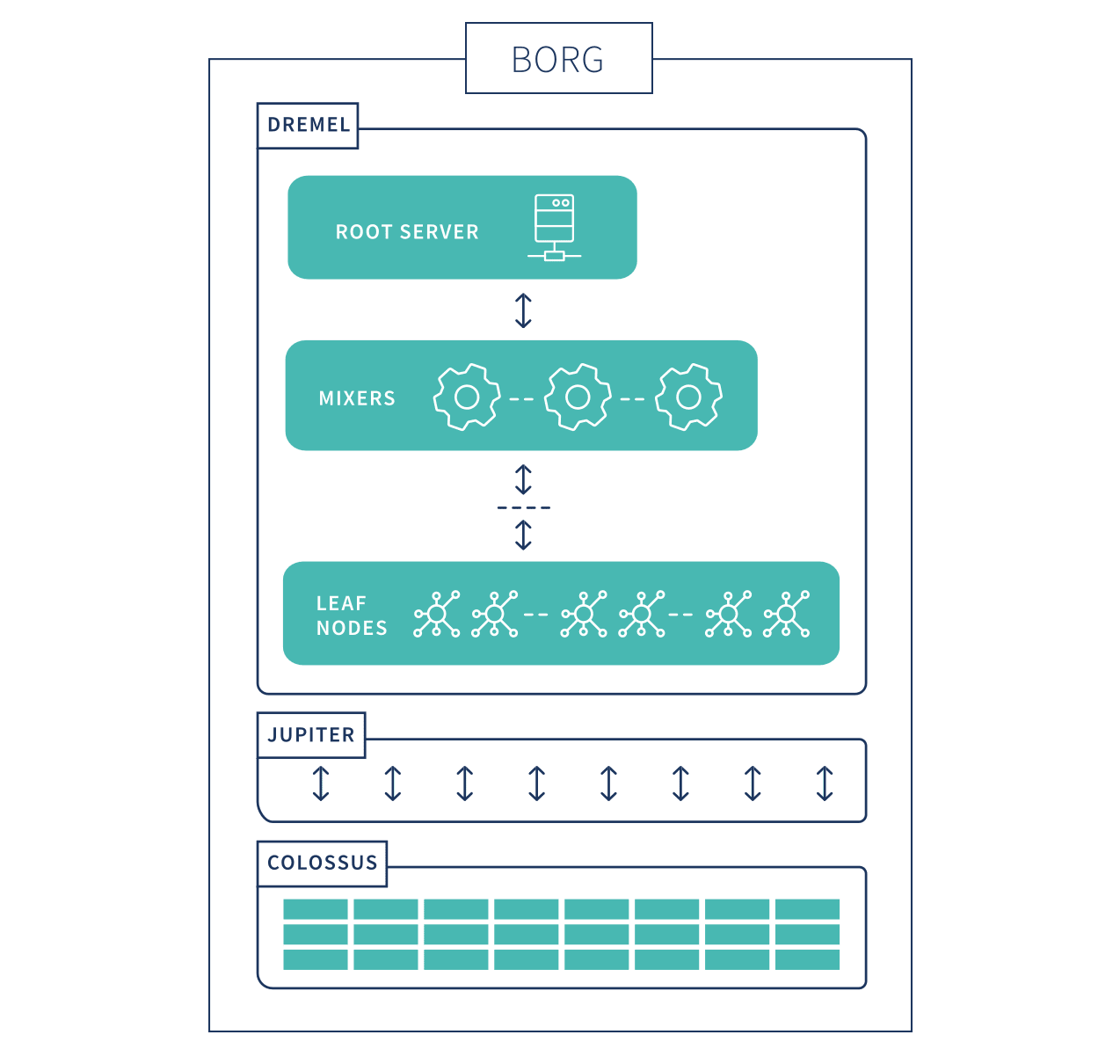
The BigQuery architecture is composed of several components. Borg is the compute. Colossus is the distributed storage. Jupiter is the network. And Dremel is the execution engine.
Snowflake Cloud Data Warehouse: The first multi-cloud data warehouse
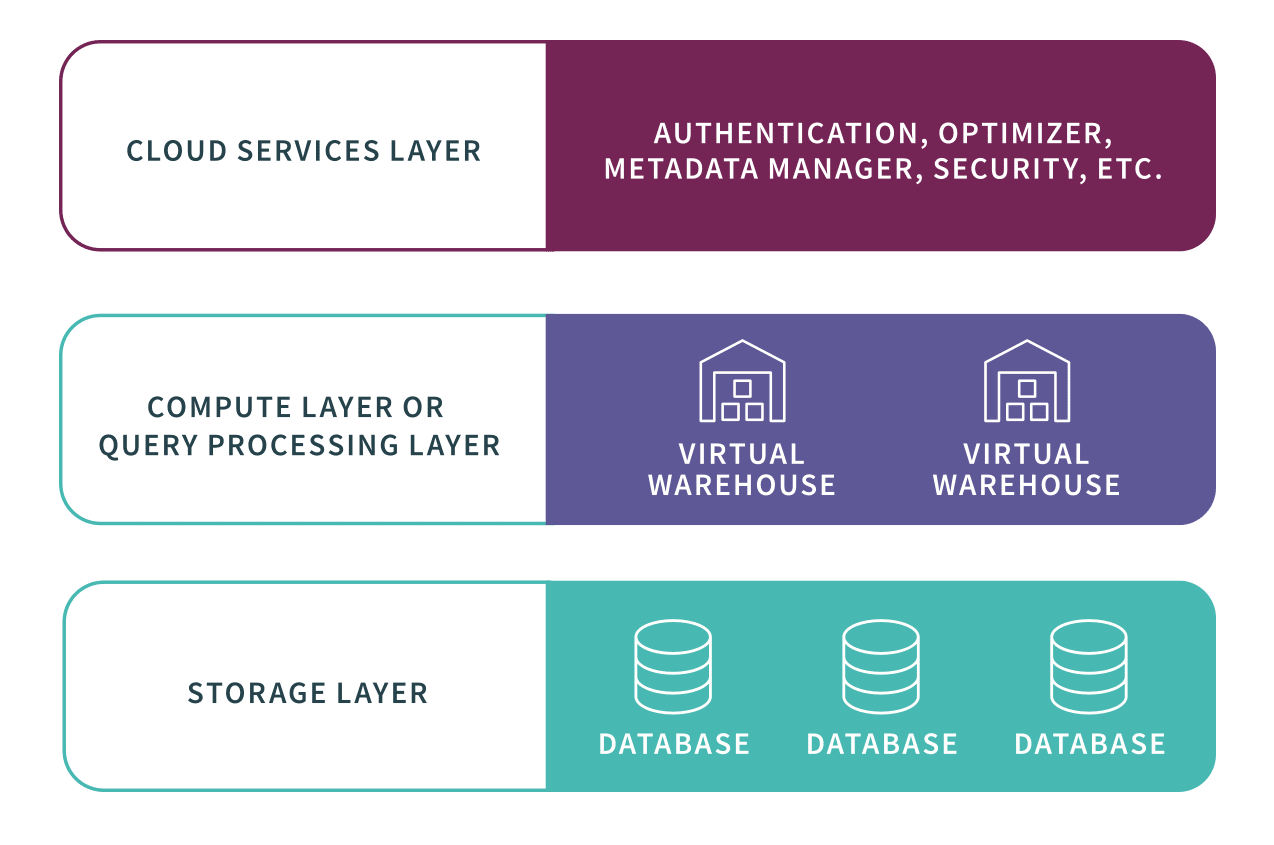
Snowflake is a fully managed MPP cloud-based data warehouse that runs on AWS, GCP, and Azure. Snowflake, unlike the other data warehouses profiled here, is the only solution that doesn’t run on its own cloud. With a common and interchangeable code base, Snowflake features global data replication, which means you can move your data to any cloud, in any region — without having to re-code your applications or learn new skills.
When you’re a Snowflake user, you can spin up as many virtual warehouses as you need to parallelize and isolate the performance of individual queries. Snowflake enables very high concurrency by separating storage and compute to ensure that many warehouses can simultaneously access the same data source.
You interact with Snowflake’s data warehouse through a web browser, the command line, an analytics platform, or via Snowflake’s ODBC, JDBC, or other supported drivers. The platform supports ACID-compliant relational processing and has native support for document store formats such as JSON, Avro, ORC (Optimized Row Columnar), Parquet, and XML.
What are the risks in moving to a cloud data warehouse?
Whichever cloud-based data warehouse solution you decide on for your business, keep in mind that the migration itself may have a few bumps along the way. Data scientists and business analysts may need to change their reporting workflows, and there may be a decrease in performance from your on-premises data warehouse.
Managing a cloud-based data warehouse can also pose a challenge for certain IT teams, as traditional data loading and ETL processes can be unwieldy, time-consuming and prone to error.
To help your organization make the transition, there are solutions that minimize the cost and operational complexity of migration.
Is AWS a data warehouse?
AWS offers on-demand cloud computing platforms and APIs on a metered pay-as-you-go basis. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud.
How is Snowflake different from AWS?
Snowflake is a fully managed MPP cloud data warehouse that runs on AWS, GCP, and Azure. AWS offers a suite of cloud computing services including compute power, database storage and content delivery. Learn more about the top cloud data warehouses.