Talend „Job Design Patterns“ und Best Practices: Teil 3
Es scheint, als wären meine vorherigen Blogbeiträge zu diesem Thema auf großes Interesse gestoßen. Dafür möchte ich mich nochmals bei meinen Lesern bedanken.
Falls Sie neu hier sind und meine vorherigen Einträge nicht gelesen haben, fangen Sie bitte zuerst damit an (Talend „Job Design Patterns“ und Best Practices Teil 1 und Teil 2) und lesen Sie dann erst Teil 3, da die Teile aufeinander aufbauen. Diese Reihe ist in der Tat so beliebt, dass sogar Übersetzungen angefertigt wurden – Sie können die Beiträge auch auf Französisch lesen (klicken Sie einfach auf die französische Flagge). An dieser Stelle möchte ich mich bei Gaël Pegliasco, „Chef de Projets“ bei Makina Corpus, für seine Ausdauer, Geduld und professionelle Arbeitsweise bedanken – er war eine enorme Hilfe bei der Erstellung und Veröffentlichung dieser Übersetzungen.
Bevor ich noch mehr über Job Design Patterns und Best Practices erkläre, möchte ich kurz darauf hinweisen, dass die vorherigen Inhalte in einer 90-minütigen technischen Präsentation zusammengefasst wurden. Diese Präsentation wird im Rahmen der Talend Technical Boot Camps gehalten, die rund um den Globus stattfinden. Schauen Sie auf der Talend-Website nach, welche Events demnächst in Ihrer Nähe geplant sind – es würde mich freuen, Sie dort zu treffen!
Nach wie vor können Sie gerne meine Beiträge kommentieren, Fragen dazu stellen und/oder abweichende Meinungen einbringen – in der Tat liegt mein großes Ziel darin, die Diskussion auf die Talend-Community auszuweiten. Richtlinien statt Standards, erinnern Sie sich? Ich hoffe, dass Sie eigene Beiträge und Meinungen zu diesem Thema haben. Das würde mich jedenfalls sehr freuen ...
Auf dem Thema aufbauen
Es dürfte sich inzwischen herumgesprochen haben, dass ich der Meinung bin, dass die Definition von Entwicklungsleitlinien essenziell für den Erfolg eines Softwarelebenszyklus (einschließlich Talend-Projekten) ist. Aber ich sage es noch mal: Die Erstellung von Entwicklungsleitlinien, die Einführung dieser Richtlinien durch das Team und eine schrittweise disziplinierte Umsetzung im Unternehmen sind entscheidend, um möglichst viel aus Talend herauszuholen. Ich hoffe, dass Sie mir alle zustimmen! Die Erstellung von Talend-Jobs kann viele Wendungen nehmen (und ich spreche nicht über die neuen gebogenen Linien); um alles richtig zu machen, ist es daher umso wichtiger, die grundlegenden Begriffe Business-Use-Case, Technologie und Methode zu verstehen. Meiner Meinung nach lohnt es sich allemal, Richtlinien für Ihr Team zu definieren. Am Ende werden Sie darüber froh sein, glauben Sie mir!
Viele Use-Cases, die Talend-Kunden Schwierigkeiten bereiten, haben gewöhnlich mit irgendeiner Form der Datenintegration zu tun, der Kernkompetenz von Talend. Dabei geht es darum, Daten von einem Ort an einen anderen zu verlagern. Heute strömen Daten in vielen Formen ein; wichtig ist, was wir damit machen und wie wir sie ändern. Tatsächlich ist das für praktisch jeden Job, den wir erstellen, entscheidend. Wenn also die Verlagerung von Unternehmensdaten der Use-Case und Talend ein integraler Bestandteil des Technologie-Stacks ist, was ist dann die Methode? Natürlich die SDLC-Best-Practice, die wir bereits besprochen haben. Aber es ist mehr als nur das. Wenn es um Daten geht, ist auch die Datenmodellierung Teil dieser Methode – ein Thema, das mich wirklich begeistert. Ich bin schon seit über 25 Jahren Datenbankarchitekt und habe mehr Datenbanklösungen konzipiert und erstellt, als ich zählen kann. Daher ist es klar für mich, dass auch Datenbanksysteme einen Lebenszyklus haben! Unabhängig davon, ob es um Flatfiles, EDI, OLTP, OLAP, STAR, Snowflake oder Datentresor-Schemata geht – den durchgängigen Prozess für Daten und die entsprechenden Schemata (quasi von der Wiege bis zur Bahre) zu ignorieren, ist im besten Fall eine Achillesferse, im schlimmsten Fall ein komplettes Desaster!
Auch wenn es in dieser Blogreihe nicht um Datenmodellierungsmethoden geht, ist es extrem wichtig, geeignete Datenstrukturen zu entwerfen und zu nutzen. Werfen Sie einen Blick auf meine Datentresor-Blogreihe und verfolgen Sie auch künftige Blogeinträge zur Datenmodellierung. Im Augenblick müssen wir das einfach so hinnehmen, aber DDLC (Data-Development-Life-Cycle) ist in der Tat eine Best Practice! Denken Sie mal darüber nach; ich hab gar nicht mal so unrecht, oder?
Weitere Best Practices für Jobdesigns
Okay, jetzt ist es an der Zeit, Ihnen ein paar weitere Best Practices für Talend-Jobdesigns zu präsentieren. Bisher haben wir 16 behandelt und es folgen acht weitere (und ich bin sicher, dass es noch einen vierten Teil dieser Reihe geben wird, da es sonst nicht möglich ist, alles in diesen Teil zu packen und das Ganze dabei noch übersichtlich zu gestalten). Viel Spaß!
Acht weitere Best Practices:
Code-Routinen
Gelegentlich kommt es vor, dass die Talend-Komponenten bestimmte Programmierungsanforderungen nicht erfüllen. Das ist in Ordnung; Talend ist ein Java-Code-Generator, nicht wahr? Und außerdem sind auch Java-Komponenten verfügbar, die Sie in Ihrem Canvas platzieren können, um puren Java-Code in den Prozess und/oder Datenfluss zu integrieren. Aber was ist, wenn sogar das nicht ausreicht? Lassen Sie mich ein nützliches Instrument vorstellen: Code-Routinen! Das sind Java-Methoden, die Sie in Ihrem Projekt-Repository hinzufügen können; im Grunde benutzerdefinierte Java-Funktionen, die Sie codieren und an verschiedenen Stellen in Ihrem Job nutzen können.
Talend bietet viele Java-Funktionen, die Sie womöglich schon benutzt haben, wie zum Beispiel:
- getCurrentDate()
- sequence(String seqName, int startValue, int step)
- ISNULL(object variable)
Code-Routinen können Sie auf vielfältige Weise für Jobs, Projekte und Anwendungsfälle nutzen. Wiederverwendbarer Code ist hier mein Mantra. Idealerweise erstellen Sie eine nützliche Code-Routine, die einen Job auf allgemeine Weise optimiert. Integrieren Sie angemessene Kommentare, wenn diese beim Auswählen der Funktion als „Helper“-Text erscheinen.

Repository-Schemata
Der Metadaten-Bereich im Projekt-Repository bietet eine gute Gelegenheit, um wiederverwendbare Objekte zu erstellen – eine der zentralen Entwicklungsleitlinien, erinnern Sie sich? Mithilfe von Repository-Schemata können Sie auf effiziente Weise wiederverwendbare Objekte für Ihre Jobs generieren. Dazu gehören:

- Datei mit Trennzeichen
- positionell
- Regex (reguläre Ausdrücke)
- XML
- Excel
- JSON
- Allgemeine Schemata – werden für das Mapping verschiedener Datensatzstrukturen verwendet
- WDSL-Schemata – werden für das Mapping von Strukturen bei Webservice-Methoden verwendet
- LDAP-Schemata – werden für das Mapping von LDAP-Strukturen verwendet (LDIF auch verfügbar)
- UN/EDIFACT – werden für das Mapping vieler verschiedener EDI-Transaktionsstrukturen verwendet
Wenn Sie ein Schema erstellen, versehen Sie es mit einem Objektnamen, einem Zweck, einer Beschreibung und einem Metadaten-Objektnamen, der im Jobcode referenziert ist. Dies wird standardmäßig „Metadaten“ genannt; Sie sollten Namenskonventionen für diese Objekte definieren, ansonsten wird alles in Ihrem Code denselben Namen haben. Sinnvoll wäre etwa md_{objectname}. Werfen Sie einen Blick auf das Beispiel.
Allgemeine Schemata sind besonders wichtig, da Sie hier Datenstrukturen für ganz bestimmte Anforderungen erstellen. Nehmen wir als Beispiel eine Datenbankverbindung (wie im selben Beispiel dargestellt), die mittels Reverse-Engineering bearbeitete Tabellenschemata aus einer physischen Datenbankverbindung enthält. Die „Accounts“-Tabelle hat zwölf Spalten, aber ein passendes allgemeines Schema (unten definiert) hat 16 Spalten. Die zusätzlichen Spalten zählen als Mehrwertelemente für die „Accounts“-Tabelle und werden in einem Jobdatenfluss genutzt, um zusätzliche Daten einzubinden. Umgekehrt könnte eine Datenbanktabelle auch über 100 Spalten haben, wobei für einen bestimmten Jobdatenfluss nur zehn davon gebraucht werden. Ein allgemeines Schema lässt sich für eine Abfrage auf Basis der Tabellen mit den passenden zehn Spalten definieren – eine sehr nützliche Funktion. Mein Ratschlag: Nutzen Sie allgemeine Schemata SO OFT WIE MÖGLICH. Eine Ausnahme sind vielleicht Strukturen mit einer Spalte; meiner Meinung nach ist es sinnvoll, sie einfach zu integrieren.
Beachten Sie, dass andere Verbindungstypen wie SAP, Salesforce, NoSQL und Hadoop-Cluster auch Schemadefinitionen enthalten können.
Log4J
Apache Log4J ist seit Talend v6.0.1 verfügbar und bietet ein robustes Java-Logging-Framework. Alle Talend-Komponenten unterstützen jetzt komplett Log4J-Services und unterstützen die Fehlerbehebungsmethoden, die ich in meinen vorherigen Blogeinträgen besprochen habe. Ich bin mir sicher, dass Sie diese Best Practices mittlerweile in Ihre Projekte implementiert haben – zumindest hoffe ich es. Optimieren Sie Ihre Projekte jetzt mit Log4J!
Um Log 4J nutzen zu können, muss es aktiviert sein. Das können Sie im Bereich Projekteigenschaften tun. Dort können Sie auch Ihre Team-Logging-Richtlinien anpassen, um eine einheitliche Messaging-Methode für die Konsole (stderr/stdout) und Logstash-Appender sicherzustellen. Indem Sie diese Appender an nur einem Ort definieren, können Sie Log4J-Funktionen auf einfache Weise in die Talend-Jobs einbinden. Wie Ihnen vielleicht aufgefallen ist, entsprechen die Stufenwerte, die in die Log4J-Syntax eingebettet sind, den bereits bekannten Prioritäten INFO/WARN/ERROR/FATAL.
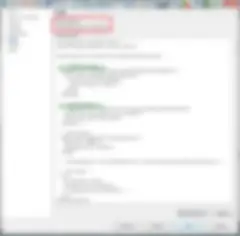
Wenn Sie in der Talend Administrator Console (TAC) eine Aufgabe zur Ausführung eines Jobs erstellen, können Sie auch die Prioritätsstufe von Log4J festlegen. Stellen Sie sicher, dass Sie für DEV-/TEST- und PROD-Umgebungen eine angemessene Stufe definieren. Am besten sollten Sie für DEV/TEST die Stufe INFO, für UAT die Stufe WARN und für PROD die Stufe ERROR einstellen. Höhere Stufen sind auch inbegriffen.

In Kombination mit den tWarn- und tDie-Komponenten und dem neuen Logserver ermöglicht Log4J eine wesentlich bessere Überwachung und Nachverfolgung von Jobs. Nutzen Sie dieses Feature und definieren Sie eine Entwicklungsrichtlinie für Ihr Team.
Activity Monitoring Console (AMC)
Talend bietet ein integriertes Add-on-Tool für eine bessere Job-Überwachung, das gesammelte Aktivitäten zu detaillierten Verarbeitungsinformationen in einer Datenbank konsolidiert. Dazu gehört eine grafische Oberfläche, die von Studio und von der TAC aus aufgerufen werden kann. Dies hilft Entwicklern und Administratoren, Komponenten- und Jobinteraktionen besser zu verstehen, unerwartete Fehler zu vermeiden und wichtige Entscheidungen rund um das Systemmanagement zu treffen. Allerdings müssen Sie die AMC-Datenbank und -Web-App installieren (dies ist ein optionales Feature). Alle Informationen zur AMC-Komponenten-Installation finden Sie im Talend Activity Monitoring Console User Guide. Daher werde ich Sie an dieser Stelle nicht damit langweilen. Lassen Sie uns stattdessen die Best Practices für deren Nutzung unter die Lupe nehmen.

Die AMC-Datenbank umfasst drei Tabellen mit:
- tLogCatcher – erfasst Daten, die von den Java-Ausnahmen oder den tWarn-/tDie-Komponenten weitergeleitet werden
- tStatCatcher – erfasst Daten, die vom „tStatCatcher Statistics“-Auswahlkästchen zu individuellen Komponenten weitergeleitet werden
- tFlowMeterCatcher – erfasst Daten, die von der tFlowMeter-Komponente weitergeleitet werden
Diese Tabellen speichern die Daten für die AMC-UI, die eine robuste Visualisierung der Jobaktivitäten auf Basis dieser Daten bietet. Wählen Sie die richtigen Einstellungen für Log-Prioritäten im Projektpräferenzen-Tab und berücksichtigen Sie eventuelle Dateneinschränkungen bei Jobausführungen für jede Umgebung (DEV/TEST/PROD). Nutzen Sie die „Main Chart“-Ansicht, um Engpässe im Jobdesign zu identifizieren und zu analysieren, bevor Sie eine Freigabe in PROD-Umgebungen veranlassen. Wählen Sie die „Error Report“-Ansicht, um zu analysieren, wie viele Fehler in einem bestimmten Zeitfenster vorkommen.

Dies ist zwar ganz hilfreich, aber mit den Tabellen kann man noch viel mehr machen. Da sie in einer Datenbank sind, lassen sich SQL-Abfragen schreiben, um wertvolle Informationen extern zu gewinnen. Mit den Scripting-Tools ist es möglich, automatisierte Abfragen und Benachrichtigungen zu erstellen, sofern bestimmte Bedingungen gegeben sind und in der AMC-Datenbank erfasst sind. Mithilfe einer etablierten Return-Code-Methode (wie in meinem ersten Blogbeitrag zu Job Design Patterns beschrieben) können diese Abfragen automatisierte Prozesse programmatisch ausführen. Echt nützlich!
Recovery-Checkpoints
Haben Sie also einen Job mit langer Laufzeit? Vielleicht sind dafür mehrere kritische Schritte erforderlich und wenn ein Schritt fehlschlägt, muss man von neuem beginnen – ein echtes Problem. Es wäre sicherlich toll, wenn man mit minimalem (Zeit-)Aufwand den Job an einem bestimmten Punkt im Jobflow, kurz vor dem Fehler, neu starten könnte. Die gute Nachricht: Die TAC bietet genau hierfür eine spezielle Funktion zur Wiederherstellung des Jobs. Mit diesen Recovery-Checkpoints konzipierte Jobs können, ohne von vorne anfangen zu müssen, die Verarbeitung wieder aufnehmen – vorausgesetzt, die Funktion wird strategisch und richtig eingesetzt.

Wenn ein Fehler auftritt, nutzen Sie den TAC-„Error Recovery Management“-Tab, um den Fehler zu bestimmen und den Job fortzusetzen. Tolle Sache, nicht wahr?

Joblets
Wir haben schon gesagt, dass ein Joblet wiederverwendbarer Jobcode ist, der nach Bedarf in einen oder mehrere Jobs eingefügt werden kann. Aber was sind Joblets wirklich? In der Tat gibt es nicht viele Anwendungsfälle für Joblets, aber wenn Sie einen finden, nutzen Sie ihn – das sind quasi wertvolle Raritäten. Sie können Joblets auf verschiedene Weisen erstellen und nutzen. Schauen wir uns das mal an!
Beim Erstellen eines neuen Joblets werden Input-/Output-Komponenten automatisch in Ihrem Canvas hinzugefügt. So können Sie die ein- und ausgehenden Schemata rund um den Job-Workflow mithilfe des Joblets zuweisen. Bei dieser typischen Nutzung von Joblets werden Daten durch das Joblet weitergegeben; was sie innerhalb davon machen, können Sie selbst entscheiden. Im folgenden Beispiel wird eine Zeile eingegeben, und eine Datenbanktabelle wird aktualisiert, die Zeile wird in stdout erfasst und dann wird dieselbe Zeile unverändert (in diesem Fall) ausgegeben.

In einem weniger typischen Anwendungsfall werden entweder der Input, der Output oder beide Komponenten entfernt, um spezielle Daten-/Prozessflows zu bewältigen. Im folgenden Beispiel geht nichts in dieses Joblet hinein bzw. aus dem Joblet heraus. Stattdessen hält eine tLogCatcher-Komponente Ausschau nach ausgewählten Ausnahmen für eine nachfolgende Verarbeitung (das haben wir schon bei den Best Practices zur Fehlerbehebung angesprochen).
Ohne Zweifel können Joblets die Wiederverwendbarkeit von Code drastisch erhöhen – genau dazu sind sie ja da. Platzieren Sie diese kostbaren Juwele in ein Referenzprojekt, um sie über viele verschiedene Projekte hinweg zu nutzen, und freuen Sie sich über diese nützlichen Helfer.
Komponenten-Testfälle
Wenn Sie immer noch eine ältere Version als Talend 6.0.1 nutzen, können Sie das ignorieren – oder führen Sie doch einfach ein Upgrade durch! Eines meiner neuen Lieblingsfeatures ist die Funktion zur Erstellung von Testfällen in einem Job. Dabei handelt es sich jetzt nicht ganz um Unittests, sondern Komponententests; Jobs, die mit dem Parent-Job verknüpft sind, und insbesondere die zu testende Komponente. Nicht alle Komponenten unterstützen Testfälle, aber wenn eine Komponente einen Datenfluss-Input weiterleitet, ist ein Testfall möglich.
Um einen Komponenten-Testfall zu erstellen, klicken Sie einfach mit der rechten Maustaste auf die ausgewählte Komponente. Unten finden Sie die Menüoption „create test case“. Wenn Sie diese Option wählen, wird ein neuer Job erstellt und ein funktionales Template für den Testfall erscheint. Dort befindet sich die zu testende Komponente gemeinsam mit integrierten INPUT- und OUTPUT-Komponenten, die in einen Datenfluss integriert sind, der einfach eine Input File ausliest, die Daten verarbeitet und die Datensätze in die zu testende Komponente überträgt; diese macht dann ihre Arbeit und schreibt das Ergebnis in eine neue Result File. Nach Abschluss wird diese Datei mit dem erwarteten Ergebnis bzw. der Reference File verglichen. Entweder passt es oder es passt nicht. Eigentlich ganz simpel, oder? Aber lassen Sie uns noch mal einen Blick darauf werfen.
Hier sehen Sie einen Job, den wir schon einmal hatten. Er umfasst eine tJavaFlex-Komponente, die den Datenfluss ändert und ihn zur weiteren Verarbeitung weitergibt.

Wir haben einen Testfall-Job (wie unten dargestellt) generiert: Es sind keine Änderungen erforderlich (ich habe nur den Canvas etwas aufgeräumt).
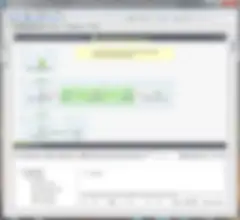
Wichtig: Sie können den Code des Testfall-Jobs anpassen, aber die zu testende Komponente sollten Sie nur im Parent-Job ändern. Sagen wir zum Beispiel, dass das Schema geändert werden muss: Ändern Sie es im Parent-Job (oder Repository), die Änderung wird dann auch im Testfall propagiert. Sie sind untrennbar miteinander verbunden und daher durch dieses Schema verknüpft.
Beachten Sie: Wenn eine Testfall-Instanz generiert wird, können mehrere Input- und Referenz-Dateien erstellt werden, um denselben Testfall-Job zu durchlaufen. Damit lassen sich gute, schlechte, kleine, große und/oder spezielle Testdaten testen. Die klare Empfehlung lautet hier, nicht nur sorgfältig zu evaluieren, was getestet werden soll, sondern auch welche Testdaten genutzt werden sollen.
Wenn schließlich das Nexus-Artefakt-Repository genutzt wird und Testfall-Jobs dort zusammen mit ihrem Parent-Job gespeichert werden, kann man mit Tools wie Jenkins die Ausführung dieser Tests automatisieren und feststellen, ob ein Job bereit für die nächste Umgebung ist.
Datenfluss-Iterationen
Bei der Arbeit mit Talend-Code ist Ihnen bestimmt aufgefallen, dass die Komponenten mit einem Trigger-Prozess oder einem Zeilen-Datenfluss-Konnektor miteinander verbunden werden. Um diese Verbindung herzustellen, müssen Sie nur mit der rechten Maustaste auf die Startkomponente klicken und die Verbindungslinie mit der nächsten Komponente verknüpfen. Die Prozessfluss-Verbindungen sind entweder OnSubJobOk/ERROR, OnComponentOK/ERROR oder RunIF (die kamen bereits in meinen vorherigen Blogbeiträgen vor). Die Datenflussverbindungen werden bei der Verknüpfung row{x} benannt, wobei x, eine Ziffer, dynamisch von Talend zugewiesen wird, um einen eindeutigen Objekt-/Zeilennamen zu erstellen. Diese Datenflussverbindungen können natürlich personalisierte Namen haben (eine Best Practice für Namenskonventionen), aber durch Herstellung dieser Verbindung wird das Datenschema im Grunde von einer Komponente auf die andere gemappt und bildet dabei die Pipeline, durch die die Daten weitergegeben werden. Zur Laufzeit werden Daten, die über diese Verbindung übertragen werden, oft als Datensatz bezeichnet. Je nach nachgeschalteten Komponenten wird der komplette Datensatz durchgängig innerhalb des gekapselten Subjobs verarbeitet.
Die gleichzeitige Verarbeitung von Datensätzen ist nicht immer so möglich. Manchmal ist eine direkte Steuerung des Datenflusses erforderlich (mithilfe der Row-by-Row-Verarbeitung oder durch Iterationen). Werfen Sie einen Blick auf den folgenden unstimmigen Code:

Sehen Sie die Komponenten tIterateToFlow und tFlowToIterate? Mithilfe dieser spezialisierten Komponenten können Sie die Datensätze Zeile für Zeile iterieren und so die Datenflussverarbeitung steuern. Diese listenbasierte Verarbeitung ist in manchen Fällen ganz nützlich. Aber geben Sie acht: Wenn Sie einen Datenfluss in Row-by-Row-Iterationen aufbrechen, müssen Sie ihn in manchen Fällen wieder zu einem vollständigen Datensatz zusammensetzen, bevor die Verarbeitung fortgesetzt werden kann (s. abgebildete tMap). Dies rührt daher, dass manche Komponenten einen Row-Datensatz-Flow umsetzen und mit einem iterativen Datensatz-Flow überfordert sind. Beachten Sie auch, dass t{DB}Input-Komponenten sowohl „Main“ als auch „iterate“ als Datenflussoption im Zeilenmenü bieten.
Werfen Sie einen Blick auf die Beispielszenarien Transforming data flow to a list (Transformation von Datenflüssen in einer Liste) und Transforming a list of files as a data flow (Transformation einer Liste von Dateien als Datenfluss) im Talend Help Center und Component Reference Guide. Hier finden Sie nützliche Erläuterungen zur Nutzung dieses Features. Verwenden Sie dieses Feature je nach Bedarf und stellen Sie lesbare Label bereit, um Ihren Zweck zu beschreiben.
Fazit
Jetzt müssen Sie das Ganze erst einmal verdauen. Aber keine Sorge, wir haben es bald geschafft! Teil 4 dieser Blogreihe beschäftigt sich mit den letzten Job Design Patterns und Best Practices, die eine solide Grundlage für die Erstellung guten Talend-Codes bilden. Aber ich habe Ihnen auch Beispiel-Use-Cases versprochen und dieses Versprechen halte ich auch. Ich glaube, es ist ganz gut, all diese Best Practices zu verinnerlichen. Das macht sich spätestens dann bezahlt, wenn wir uns mit ihren abstrakten Anwendungen beschäftigen. Wie immer freue ich mich über Kommentare, Fragen und/oder interessante Gespräche.

Weitere Artikel zu diesem Thema
- Was sind Datensilos?
- Datenextraktion – Eine Definition
- Talend „Job Design Patterns“ und Best Practices: Teil 4
- Was ist Datenmigration?
- Was ist Daten-Mapping?
- Datenbankintegration: Vorteile, Arten und Instrumente
- Was ist Datenintegration?
- Datenmigration verstehen: Strategie und Best Practices
- Talend Job Design Modelle und Best Practices: Teil 2
- Talend „Job Design Modelle“ und Best Practices: Teil 1
- Change Data Capture: Informationen und Anwendungsmöglichkeiten
- 5 erfolgreiche Datenintegrationsstrategien
- Ein Talend Überblick für Informatica PowerCenter-Entwickler: Teil 1