









































Why is it Important?
Data modeling defines how your data will be organized, stored, retrieved, and presented. In this way, it supports business intelligence and analytics by clearly defining your data so you can find and trust the data you need.
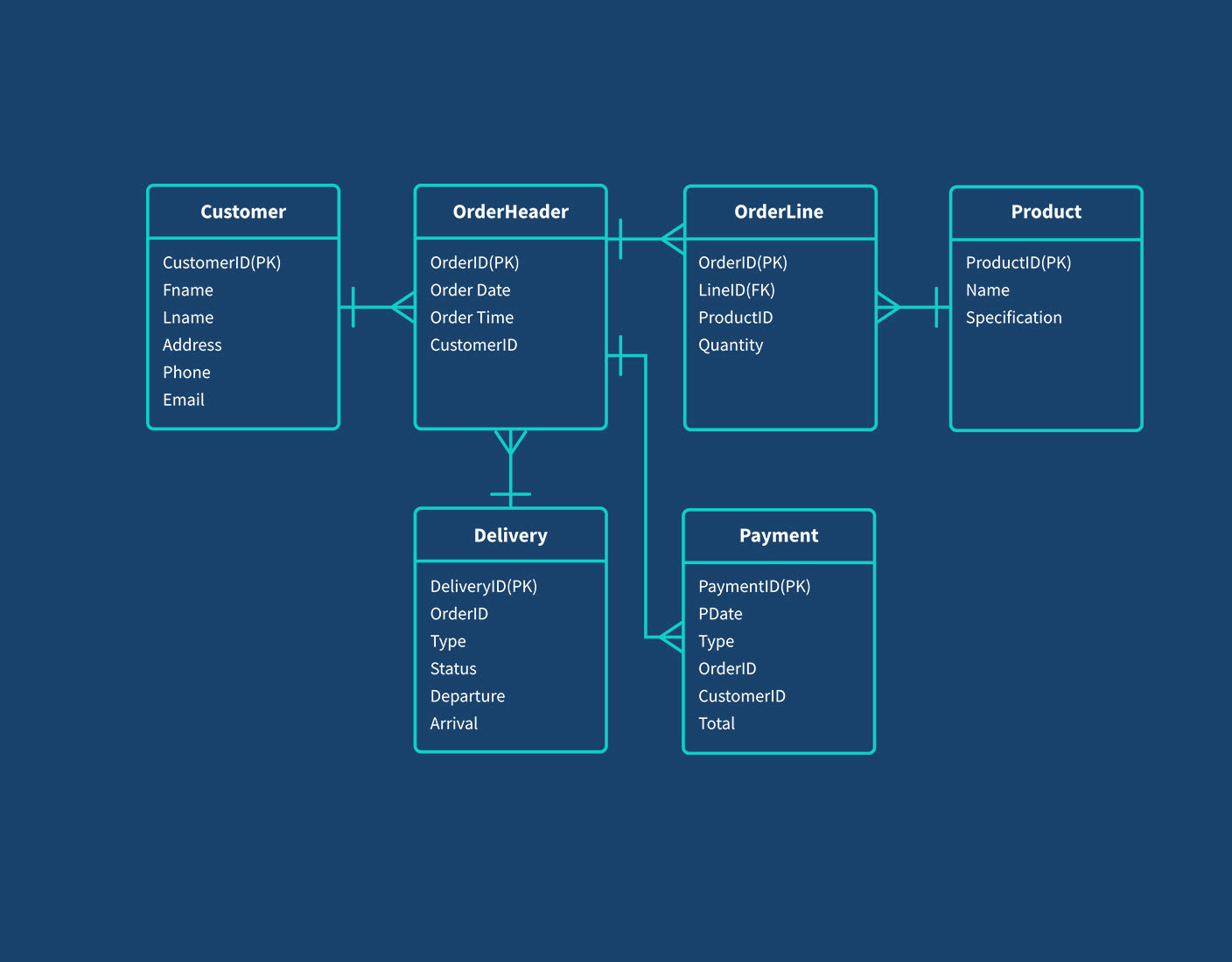
Your organization may have many large and complex datasets from different and unconnected sources such as finance, sales, marketing, operations, and even real-time streaming data. You may also have complicated data issues such as storing your data across cloud, hybrid multicloud, on premises, and edge devices.
Data modeling helps solve for these challenges so you can:
Understand the relationships between different data elements and how they’re connected so you can better organize and manage your data.
Identify and resolve potential issues before they occur. By modeling data in advance, you can identify potential problems and address them before they cause issues in the actual implementation. You can also define schemas for existing systems by examining raw data stored in data lakes or data lakehouses.
Create a logical and efficient database structure. A well-designed data model can improve query performance and reduce data redundancy.
Facilitate data governance and communication between different teams and stakeholders. A clear and consistent model can help ensure everyone’s on the same page regarding common internal data standards and definitions.
Maintain and scale your system more easily. A well-designed model informs your data architecture design and technology selection and can make it easier to add new features or data sources in the future.


