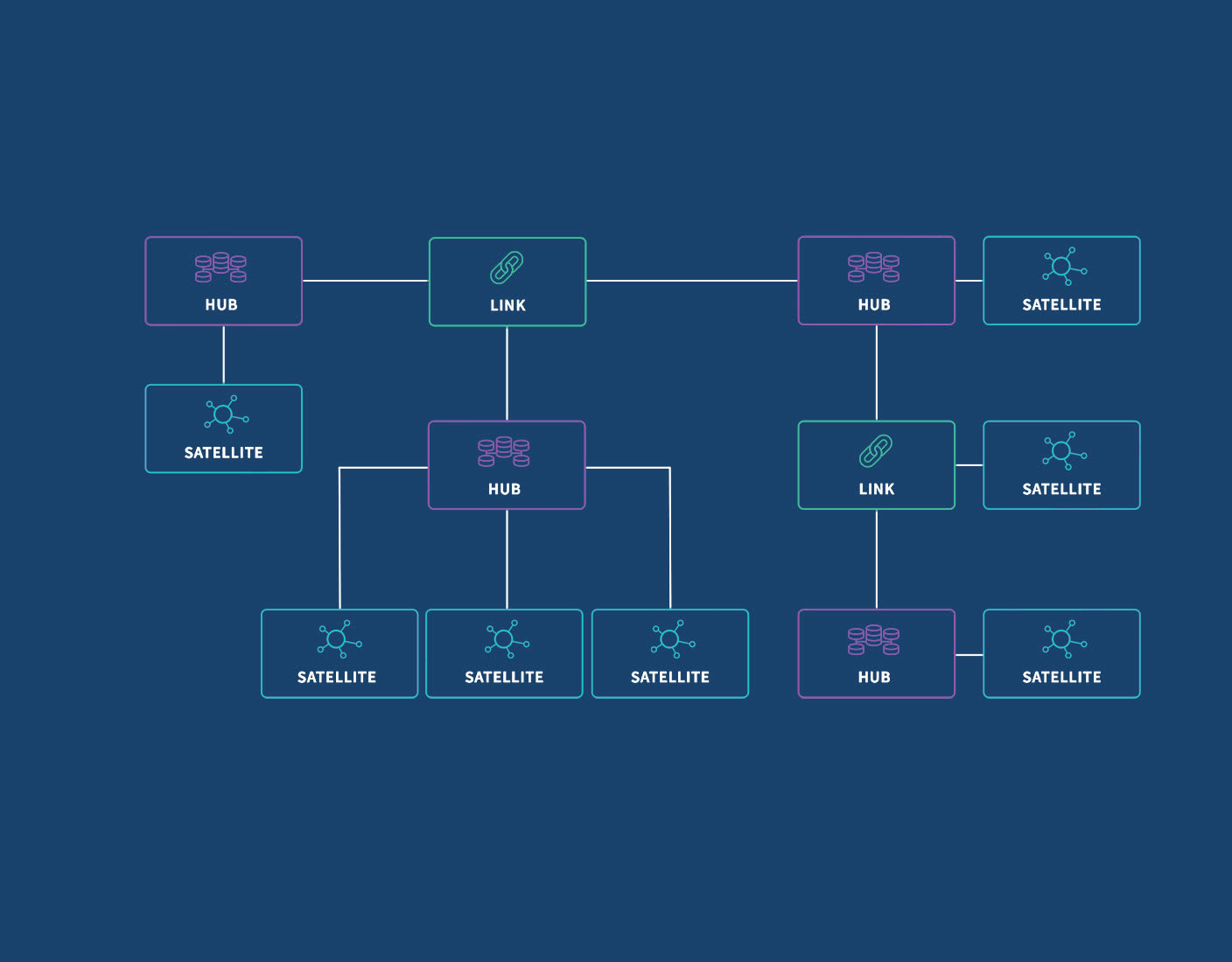
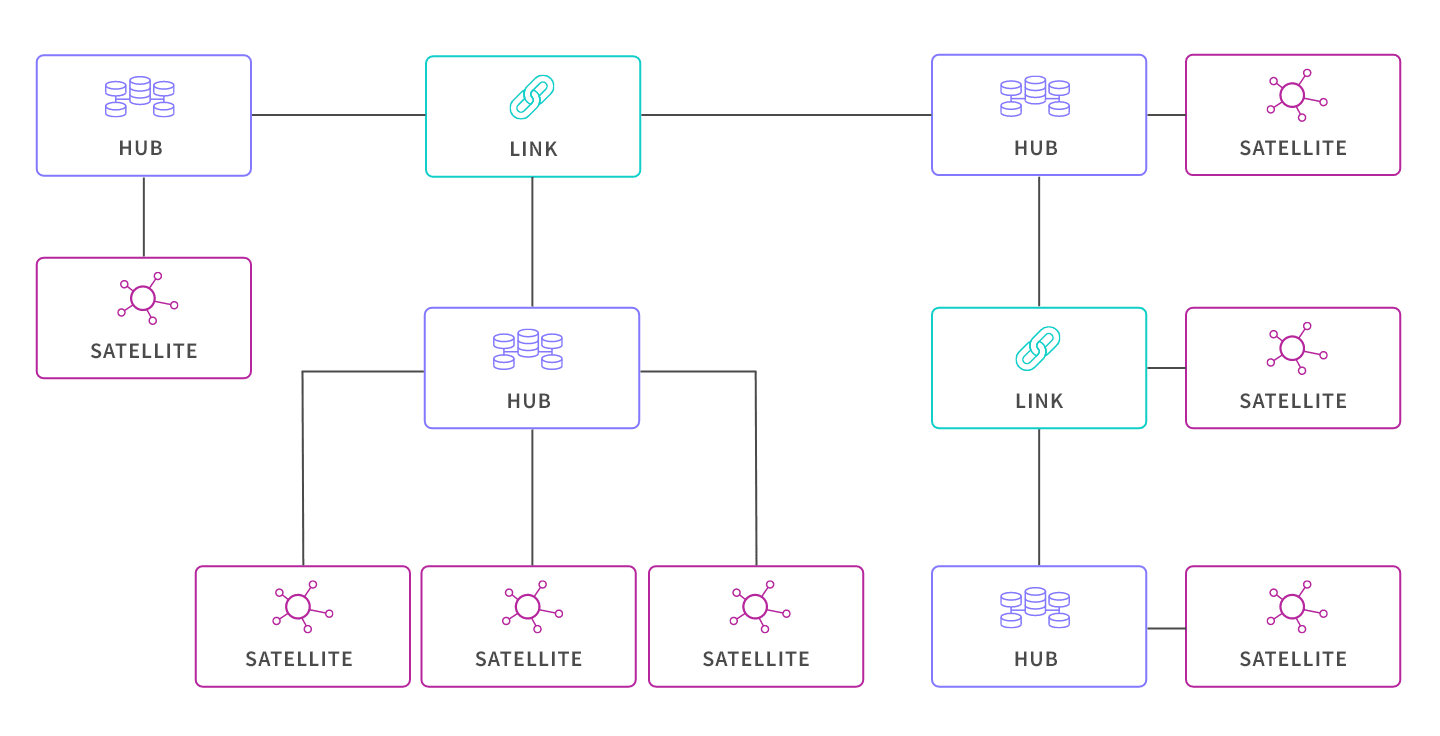
DV Solution: Through the separation of business keys (as they are generally static) and the associations between them from their descriptive attributes, a Data Vault (DV) confronts the problem of change in the environment. Using these keys as the structural backbone of a data warehouse all related data can be organized around them. These Hubs (business keys), Links (associations), and SAT (descriptive attributes) support a highly adaptable data structure while maintaining a high degree of data integrity. Dan Linstedt often correlates the DV to a simplistic view of the brain where neurons are associated with Hubs and Satellites and where dendrites are Links (vectors of information). Some Links are like synapses (vectors in the opposite direction). They can be created or dropped on the fly as business relationships change, automatically morphing the data model as needed without impacting the existing data structures.
DV Solution: Data Vault 2.0 arrived on the scene in 2013 and incorporates seamless integration of big data technologies along with methodology, architecture, and best practice implementations. Through this adoption, very large amounts of data can easily be incorporated into a DV designed to store using products like MongoDB, NoSQL, Apache Cassandra, Amazon DynamoDB, and many other NoSQL options. Eliminating the cleansing requirements of a star schema design, the DV excels when dealing with huge data sets by decreasing ingestion times, and enabling parallel insertions which leverages the power of big data systems.
DV Solution: Crafting an effective and efficient DV model can be done quickly once you understand the basics of the 3 table types: Hub, Satellite, and Link. Identifying the business keys 1st and defining the Hubs is always the best place to start. From there Hub-Satellites represent source table columns that can change, and finally Links tie it all up together. Remember it is also possible to have Link-Satellite tables too. Once you’ve got these concepts, it’s easy. After you’ve completed your DV model the next common thing to do is build the ETL data integration process to populate it. While a DV data model is not limited to EDW/BI solutions, anytime you need to get data out of some data source and into some target, a data integration process is generally required.
Challenge #4: The Business Domain (fitting the data to meet the needs of your business, not the other way around)
DV Solution: The DV essentially defines the Ontology of an Enterprise in that it describes the business domain and relationships within it. Processing business rules must occur before populating a Star Schema. With a DV, you can push them downstream, post EDW ingestion. An additional DV philosophy is that all data is relevant, even if it is wrong. Dan Linstedt suggests that data being wrong is a business problem, not a technical one. We agree! An EDW is really not the right place to fix (cleanse) bad data. The simple premise of the DV is to ingest 100% of the source data 100% of the time; good, bad, or ugly. Relevant in today’s world, auditability and traceability of all the data in the data warehouse thus become a standard requirement. This data model is architected specifically to meet the needs of today’s EDW/BI systems.
DV Solution: The DV methodology is based on SEI/CMMI Level 5 best practices and includes many of its components combining them with best practices from Six Sigma, TQM, and SDLC (Agile). DV projects have short controlled release cycles and can consist of a production release every 2 or 3 weeks automatically adopting the repeatable, consistent, and measurable projects expected at CMMI Level 5. When new data sources need to be added, similar business keys are likely, new Hubs-Satellites-Links can be added and then further linked to existing DV structures without any change to the existing data model.